 3G Eden
3G Eden RSS
RSS下面以我们之前提到的 NUMA,SMP,Multcore,SMT 结合的复杂系统为例来具体解释一下 Scheduling domains 和 CPU groups 之间的关系。
这里为了简化讨论,假设每个物理 CPU 只有两个核,每个核只有两个逻辑 CPU 。
如下图所示:
图 2. 物理 CPU 示意图
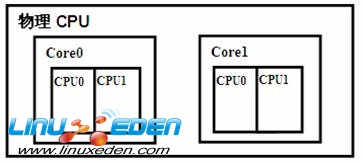
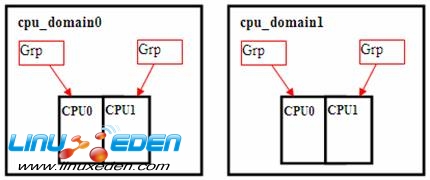
当系统启动时,会分别把每个核的两个逻辑 CPU 放入一个 Scheduling Domain,
这个级别的 domain 叫做 cpu_domain 。其中每个 domain 包括两个 CPU groups,每个 CPU group 只有一个逻辑 CPU 。
如下图所示:
图 3. 逻辑 CPU
同时每个物理 CPU 的两个核被放入一个高一级的 Scheduling Domain 。这个 domain 命名为 core_domain 。其中每个 domain 包括两个 CPU groups,每个 CPU group 有两个逻辑 CPU 。
如下图所示:
图 4. CPU group
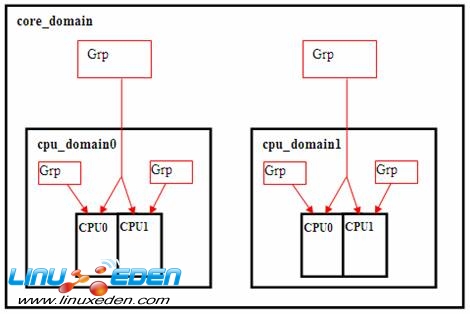
对于我们前述的复杂系统,再往上的话依次还有 phys_domain( 物理 CPU 放入的 domain) ;
numa_domain(NUMA 中的 16 个 nodes 放入的 domain) ; allnode_domain( 所有 NUMA 中的 node 放入的 domain) 。从而将所有 CPU 组织成一个基于 domain 的层次结构。
Scheduling Domains 实现
对每个 Scheduling Domain 中的 CPU groups 之间的 CPU 进行的。
每个 Scheduling Domain 都包含一些重要的信息用来决定在这级 domain 的 CPU groups 之间如何进行 Load Balance 。
- 典型的一些原则如下:
- 在 cpu_domain 级: 因为是共享 cache,cpu_power 也基本是共用的。所以可以在这个 domain 级的 cpu groups 之间可以不受限制的进行 load balance 。
- 在 core_domain 级:可能会共享 L2 级 cache, 具体跟实现相关了。因此这一级的 balance 相对没那么频繁。要 core 之间负载的不平衡达到一定程度才进行 balance 。
- 在 phys_domain 级:在这一个 domain 级,如果进行 balance 。则每个物理 CPU 上的 Cache 会失效一段时间,并且要考虑 cpu_power,因为物理 CPU 级的 power 一般是被数关系。比如两个物理 CPU 是 power*2,而不像 core, 或逻辑 CPU,只是 power*1.1 这样的关系。
- 在 numa_domain 级:这一级的开销最大,一般很少进行 balance 。
- 基本实现
Linux 主要通过以下几个方面来实现基于 Scheduling domains 的 Load Balance 。
- 周期性的 load balance
每次时钟中断到来,如果发现当前 cpu 的运行队列需要进行下一次的 balance 的时间已
经到了,则触发 SCHED_SOFTIRQ 软中断。
触发软中断
if (time_after_eq(jiffies, rq->next_balance))
raise_softirq(SCHED_SOFTIRQ);
软中断的执行函数是 run_rebalance_domains(), 它主要是再调 rebalance_domains() 来实现。
清单 1. run_rebalance_domains()
static void run_rebalance_domains(struct softirq_action *h) { int this_cpu = smp_processor_id(); struct rq *this_rq = cpu_rq(this_cpu); enum cpu_idle_type idle = this_rq->idle_at_tick ? CPU_IDLE : CPU_NOT_IDLE; rebalance_domains(this_cpu, idle); #ifdef CONFIG_NO_HZ #endif }
rebalance_domains(),根据 domain 的级别,从下往上扫描每一级 Scheduling Domain 。如果发现这个 domain 的 balance 之间的间隔时间到了,则进一步进行 task 的移动。不同级别的 domain 是会有不同的间隔时间的。而且级别越高值越大,因为移动 task 的代价越大。
清单 2. rebalance_domains()
static void rebalance_domains(int cpu, enum cpu_idle_type idle) { int balance = 1; struct rq *rq = cpu_rq(cpu); unsigned long interval; struct sched_domain *sd; /* Earliest time when we have to do rebalance again */ unsigned long next_balance = jiffies + 60*HZ; int update_next_balance = 0; int need_serialize; cpumask_t tmp; for_each_domain(cpu, sd) { if (!(sd->flags & SD_LOAD_BALANCE)) continue; interval = sd->balance_interval; if (idle != CPU_IDLE) interval *= sd->busy_factor; /* scale ms to jiffies */ interval = msecs_to_jiffies(interval); if (unlikely(!interval)) interval = 1; if (interval > HZ*NR_CPUS/10) interval = HZ*NR_CPUS/10; need_serialize = sd->flags & SD_SERIALIZE; if (need_serialize) { if (!spin_trylock(&balancing)) goto out; } if (time_after_eq(jiffies, sd->last_balance + interval)) { if (load_balance(cpu, rq, sd, idle, &balance, &tmp)) { /* * We've pulled tasks over so either we're no * longer idle, or one of our SMT siblings is * not idle. */ idle = CPU_NOT_IDLE; } sd->last_balance = jiffies; } if (need_serialize) spin_unlock(&balancing); out: if (time_after(next_balance, sd->last_balance + interval)) { next_balance = sd->last_balance + interval; update_next_balance = 1; } /* * Stop the load balance at this level. There is another * CPU in our sched group which is doing load balancing more * actively. */ if (!balance) break; } /* * next_balance will be updated only when there is a need. * When the cpu is attached to null domain for ex, it will not be * updated. */ if (likely(update_next_balance)) rq->next_balance = next_balance; } - 针对 CPU IDLE 的处理
如果一个逻辑 CPU 进入了 IDLE 状态,并且它所属的 domain 设置了 SD_BALANCE_NEWIDLE,则马上就会进行 balance,把忙的 CPU 上的进程 move 过来,从而最大的发挥多 CPU 的优势。
- 针对 fork(), exec() 的处理
当一个进行调用 exec() 执行时,本来就是要加载一个新进程,缓存本来就会失效。所以,move 到哪里都可以。因此找设置了 SD_BALANCE_EXEC 标记的 domain 。然后把进程移动到那个 domain 中最闲的 CPU group 的 CPU 上。
fork() 时也进行类似的处理。
- 其它因素比如针对 cpu_power 的处理(责任编辑:A6)
- 周期性的 load balance