 3G Eden
3G Eden RSS
RSS随着系统规模的不断扩大,以 Hyper-threading, SMP, NUMA architectures,以及近年来很热门的多核 (Multi-core) 技术为代表的高端系统得到越来越广泛的应用。这样复杂的系统给 Linux 内核的调度器带来了严峻的考验。因此,从 Linux 2.6 内核开始引入了 Scheduling Domains 的概念,用它来维护 CPU 之间的负载平衡,最大化多 CPU 的效率、性能,同时最低化系统的功耗 (Power) 。
Scheduling Domains 引入的背景
Scheduling Domains 是现代硬件技术尤其是多 CPU 多核技术发展的产物。现在,一个复杂的高端系统由上到下可以这样构成:
- 它是一个 NUMA 架构的系统,系统中的每个 Node 访问系统中不同区域的内存有不同的速度。
- 同时它又是一个 SMP 系统。由多个物理 CPU(Physical Package) 构成。这些物理 CPU 共享系统中所有的内存。但都有自己独立的 Cache 。
- 每个物理 CPU 又由多个核 (Core) 构成,即 Multi-core 技术或者叫 Chip-level Multi processor(CMP) 。这些核都被集成在一块 die 里面。一般有自己独立的 L1 Cache,但可能共享 L2 Cache 。
- 每个核中又通过 SMT 之类的技术实现多个硬件线程,或者叫 Virtual CPU( 比如 Intel 的 Hyper-threading 技术 ) 。这些硬件线程,逻辑上看是就是一个 CPU 。它们之间几乎所有的东西都共享。包括 L1 Cache,甚至是逻辑运算单元 (ALU) 以及 Power 。
在上述系统中,最小的执行单元是逻辑 CPU,进程的调度执行也是相对于逻辑 CPU 的。因此,后文皆简称逻辑 CPU 为 CPU,是物理 CPU 时会特别说明。
在这样复杂的系统,调度器要解决的一个首要问题就是如何发挥这么多 CPU 的性能,使得负载均衡。不存某些 CPU 一直很忙,进程在排队等待运行,而某些 CPU 却是处于空闲状态。
但是在这些 CPU 之间进行 Load Balance 是有代价的,比如对处于两个不同物理 CPU 的进程之间进行负载平衡的话,将会使得 Cache 失效。造成效率的下降。而且过多的 Load Balance 会大量占用 CPU 资源。
还有一个要考虑的就是功耗 (Power) 的问题。一个物理 CPU 中的两个 Virtual CPU 各执行一个进程,显然比两个物理 CPU 中的 Virtual CPU 各执行一个进程节省功耗。因为硬件上可以实现一个物理 CPU 不用时关掉它以节省功耗。
为了解决上述的这些问题,内核开发人员 Nick Piggin 等人在 Linux 2.6 中引入基于 Scheduling Domains 的解决方案。
Scheduling Domains 原理
每个 Scheduling Domain 其实就是具有相同属性的一组 cpu 的集合。并且跟据 Hyper-threading, Multi-core, SMP, NUMA architectures 这样的系统结构划分成不同的级别。不同级之间通过指针链接在一起,从而形成一种的树状的关系。如下图所示:
图 1. Scheduling Domains 原理
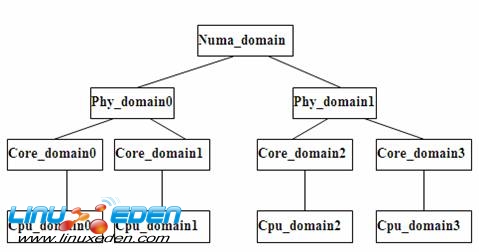
负载平衡就是针对 Scheduling domain 的。从叶节点往上遍历。直到所有的 domain 中的负载都是平衡的。当然对不同的 domain 会有不同的策略识别是否负载不平衡,以及不同的调度策略。通过这样的方式,从而很好的发挥众多 cpu 的效率。
Scheduling Domains 结构
基于 Scheduling Domains 的调度器引入了一组新的数据结构。下面先讲一下两个主要的数据结构:
- struct sched_domain: 代表一个 Scheduling Domain,也就是一个 CPU 集合,这个集合里所有的 CPU 都具有相同的属性和调度策略。 Load Balance 是针对每个 domain 里的 CPU 进行的。这里要注意 Scheduling Domains 是分级的。像上节所讲的复杂系统就分为 Allnuma_domain,Numa_domain, Phy_domain, Core_domain, Smt_domain(Cpu_domain) 五个等级。
表 1 列出了这个结构的主要字段。
- struct sched_group: 每个 Scheduling domain 都有一个或多个 CPU group,每个 group 都被 domain 当做一个单独的单元来对待。 Load Balance 就是在这些 CPU group 之间的 CPU 进行的。表 2 列出了它的主要字段。
表 1. sched_domain 数据结构
| 类型 | 名称 | 描述 |
| struct domain * | Parent | 当前 domain 的父 domain |
| struct domain * | Child | 当前 domain 的子 domain |
| cpumask_t | Span | 当前 domain 中的所有 cpu 位图 |
| unsigned long | min_interval | 最小的 load balance 间隔 |
| unsigned long | max_interval | 最大的 load balance 间隔 |
| unsigned int | busy_factor | Busy 时延迟进行 balance 的系数 |
| unsigned int | busy_idx | |
| unsigned int | idle_idx | |
| unsigned int | newidle_idx | |
| unsigned int | wake_idx | |
| unsigned int | forkexec_idx | |
| int | flags | 当前 domain 的一些状态标记 |
| enum sched_domain_level | level | 当前 domain 的级别 |
| unsigned long | last_balance | 当前 domain 最近一次进行 balance 时的时间 (jiffies 为单位 ) |
| unsigned int | balance_interval | 进行 balance 的时间间隔(ms 为单位) |
| unsigned int | nr_balance_failed | balance 失败的次数 |
表 2. sched_group 数据结构
| 类型 | 名称 | 描述 |
| struct sched_group * | next | 下一个 group 的指针 |
| cpumask_t | cpumask | 当前 group 有哪些 CPU |
| unsigned int | __cpu_power | 当前 group 的 CPU power |
| u32 | reciprocal_cpu_power | CPU power 的倒数 |