 3G Eden
3G Eden RSS
RSS接下来,修改目录项(E 节点),同样引发这一过程,从而生成新的根节点 A ’’。
图 6. COW transaction 2
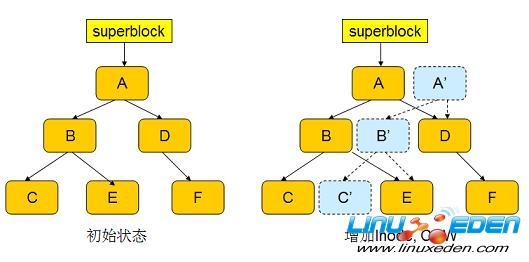
此时,inode 和目录项都已经写入磁盘,可以认为事务已经结束。 btrfs 修改 superblock,使其指向 A ’’,如下图所示:
图 7. COW transaction 3
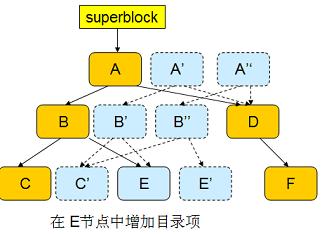
COW 事务能够保证文件系统的一致性,并且系统 Reboot 之后不需要执行 fsck 。因为 superblock 要么指向新的 A ’’,要么指向 A,无论哪个都是一致的数据。
Checksum
Checksum 技术保证了数据的可靠性,避免 silent corruption 现象。由于硬件原因,从磁盘上读出的数据会出错。比如 block A 中存放的数据为 0x55,但读取出来的数据变是 0x54,因为读取操作并未报错,所以这种错误不能被上层软件所察觉。
解决这个问题的方法是保存数据的校验和,在读取数据后检查校验和。如果不符合,便知道数据出现了错误。
ext2/3 没有校验和,对磁盘完全信任。而不幸的是,磁盘的错误始终存在,不仅发生在廉价的 IDE 硬盘上,昂贵的 RAID 也存在 silent corruption 问题。而且随着存储网络的发展,即使数据从磁盘读出正确,也很难确保能够安全地穿越网络设备。
btrfs 在读取数据的同时会读取其相应的 checksum 。如果最终从磁盘读取出来的数据和 checksum 不相同,btrfs 会首先尝试读取数据的镜像备份,如果数据没有镜像备份,btrfs 将返回错误。写入磁盘数据之前,btrfs 计算数据的 checksum 。然后将 checksum 和数据同时写入磁盘。
Btrfs 采用单独的 checksum Tree 来管理数据块的校验和,把 checksum 和 checksum 所保护的数据块分离开,从而提供了更严格的保护。假如在每个数据 block 的 header 中加入一个域保存 checksum,那么这个数据 block 就成为一个自己保护自己的结构。这种结构下有一种错误无法检测出来,比如本来文件系统打算从磁盘上读 block A,但返回了 block B,由于 checksum 在 block 内部,因此 checksum 依旧是正确的。 btrfs 采用 checksum tree 来保存数据块的 checksum,避免了上述问题。
Btrfs 采用 crc32 算法计算 checksum,在将来的开发中会支持其他类型的校验算法。为了提高效率,btrfs 将写数据和 checksum 的工作分别用不同的内核线程并行执行。
多设备管理相关的特性
每个 Unix 管理员都曾面临为用户和各种应用分配磁盘空间的任务。多数情况下,人们无法事先准确地估计一个用户或者应用在未来究竟需要多少磁盘空间。磁盘空间被用尽的情况经常发生,此时人们不得不试图增加文件系统空间。传统的 ext2/3 无法应付这种需求。
很多卷管理软件被设计出来满足用户对多设备管理的需求,比如 LVM 。 Btrfs 集成了卷管理软件的功能,一方面简化了用户命令;另一方面提高了效率。
多设备管理
Btrfs 支持动态添加设备。用户在系统中增加新的磁盘之后,可以使用 btrfs 的命令将该设备添加到文件系统中。
为了灵活利用设备空间,Btrfs 将磁盘空间划分为多个 chunk 。每个 chunk 可以使用不同的磁盘空间分配策略。比如某些 chunk 只存放 metadata,某些 chunk 只存放数据。一些 chunk 可以配置为 mirror,而另一些 chunk 则可以配置为 stripe 。这为用户提供了非常灵活的配置可能性。
Subvolume
Subvolume 是很优雅的一个概念。即把文件系统的一部分配置为一个完整的子文件系统,称之为 subvolume 。
采用 subvolume,一个大的文件系统可以被划分为多个子文件系统,这些子文件系统共享底层的设备空间,在需要磁盘空间时便从底层设备中分配,类似应用程序调用 malloc() 分配内存一样。可以称之为存储池。这种模型有很多优点,比如可以充分利用 disk 的带宽,可以简化磁盘空间的管理等。
所谓充分利用 disk 的带宽,指文件系统可以并行读写底层的多个 disk,这是因为每个文件系统都可以访问所有的 disk 。传统的文件系统不能共享底层的 disk 设备,无论是物理的还是逻辑的,因此无法做到并行读写。
所谓简化管理,是相对于 LVM 等卷管理软件而言。采用存储池模型,每个文件系统的大小都可以自动调节。而使用 LVM,如果一个文件系统的空间不够了,该文件系统并不能自动使用其他磁盘设备上的空闲空间,而必须使用 LVM 的管理命令手动调节。
Subvolume 可以作为根目录挂载到任意 mount 点。 subvolume 是非常有趣的一个特性,有很多应用。
假如管理员只希望某些用户访问文件系统的一部分,比如希望用户只能访问 /var/test/ 下面的所有内容,而不能访问 /var/ 下面其他的内容。那么便可以将 /var/test 做成一个 subvolume 。 /var/test 这个 subvolume 便是一个完整的文件系统,可以用 mount 命令挂载。比如挂载到 /test 目录下,给用户访问 /test 的权限,那么用户便只能访问 /var/test 下面的内容了。
快照和克隆
快照是对文件系统某一时刻的完全备份。建立快照之后,对文件系统的修改不会影响快照中的内容。这是非常有用的一种技术。
比如数据库备份。假如在时间点 T1,管理员决定对数据库进行备份,那么他必须先停止数据库。备份文件是非常耗时的操作,假如在备份过程中某个应用程序修改了数据库的内容,那么将无法得到一个一致性的备份。因此在备份过程中数据库服务必须停止,对于某些关键应用这是不能允许的。
利用快照,管理员可以在时间点 T1 将数据库停止,对系统建立一个快照。这个过程一般只需要几秒钟,然后就可以立即重新恢复数据库服务。此后在任何时候,管理员都可以对快照的内容进行备份操作,而此时用户对数据库的修改不会影响快照中的内容。当备份完成,管理员便可以删除快照,释放磁盘空间。
快照一般是只读的,当系统支持可写快照,那么这种可写快照便被称为克隆。克隆技术也有很多应用。比如在一个系统中安装好基本的软件,然后为不同的用户做不同的克隆,每个用户使用自己的克隆而不会影响其他用户的磁盘空间。非常类似于虚拟机。
Btrfs 支持 snapshot 和 clone 。这个特性极大地增加了 btrfs 的使用范围,用户不需要购买和安装昂贵并且使用复杂的卷管理软件。下面简要介绍一下 btrfs 实现快照的基本原理。
如前所述 Btrfs 采用 COW 事务技术,从图 1-10 可以看到,COW 事务结束后,如果不删除原来的节点 A,C,E,那么 A,C,E,D,F 依然完整的表示着事务开始之前的文件系统。这就是 snapshot 实现的基本原理。
Btrfs 采用引用计数决定是否在事务 commit 之后删除原有节点。对每一个节点,btrfs 维护一个引用计数。当该节点被别的节点引用时,该计数加一,当该节点不再被别的节点引用时,该计数减一。当引用计数归零时,该节点被删除。对于普通的 Tree Root, 引用计数在创建时被加一,因为 Superblock 会引用这个 Root block 。很明显,初始情况下这棵树中的所有其他节点的引用计数都为一。当 COW 事务 commit 时,superblock 被修改指向新的 Root A ’’,原来 Root block A 的引用计数被减一,变为零,因此 A 节点被删除。 A 节点的删除会引发其子孙节点的引用计数也减一,图 1-10 中的 B,C 节点的引用计数因此也变成了 0,从而被删除。 D,E 节点在 COW 时,因为被 A ’’所引用,计数器加一,因此计数器这时并未归零,从而没有被删除。
创建 Snapshot 时,btrfs 将的 Root A 节点复制到 sA,并将 sA 的引用计数设置为 2 。在事务 commit 的时候,sA 节点的引用计数不会归零,从而不会被删除,因此用户可以继续通过 Root sA 访问 snapshot 中的文件。
图 8. Snapshot
软件 RAID
RAID 技术有很多非常吸引人的特性,比如用户可以将多个廉价的 IDE 磁盘组合为 RAID0 阵列,从而变成了一个大容量的磁盘; RAID1 和更高级的 RAID 配置还提供了数据冗余保护,从而使得存储在磁盘中的数据更加安全。
Btrfs 很好的支持了软件 RAID,RAID 种类包括 RAID0,RAID1 和 RAID10.
Btrfs 缺省情况下对 metadata 进行 RAID1 保护。前面已经提及 btrfs 将设备空间划分为 chunk,一些 chunk 被配置为 metadata,即只存储 metadata 。对于这类 chunk,btrfs 将 chunk 分成两个条带,写 metadata 的时候,会同时写入两个条带内,从而实现对 metadata 的保护。
其他特性
Btrfs 主页上罗列的其他特性不容易分类,这些特性都是现代文件系统中比较先进的技术,能够提高文件系统的时间或空间效率。
Delay allocation
延迟分配技术能够减少磁盘碎片。在 Linux 内核中,为了提高效率,很多操作都会延迟。
在文件系统中,小块空间频繁的分配和释放会造成碎片。延迟分配是这样一种技术,当用户需要磁盘空间时,先将数据保存在内存中。并将磁盘分配需求发送给磁盘空间分配器,磁盘空间分配器并不立即分配真正的磁盘空间。只是记录下这个请求便返回。
磁盘空间分配请求可能很频繁,所以在延迟分配的一段时间内,磁盘分配器可以收到很多的分配请求,一些请求也许可以合并,一些请求在这段延迟期间甚至可能被取消。通过这样的“等待”,往往能够减少不必要的分配,也有可能将多个小的分配请求合并为一个大的请求,从而提高 IO 效率。
Inline file
系统中往往存在大量的小文件,比如几百个字节或者更小。如果为其分配单独的数据 block,便会引起内部碎片,浪费磁盘空间。 btrfs 将小文件的内容保存在元数据中,不再额外分配存放文件数据的磁盘块。改善了内部碎片问题,也增加了文件的访问效率。
图 9. inline file
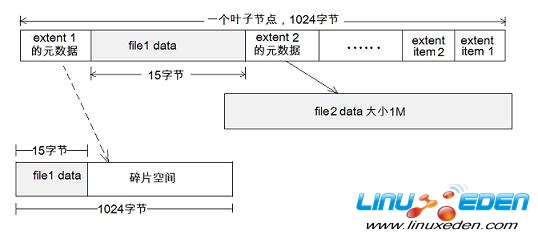
上图显示了一个 BTree 的叶子节点。叶子中有两个 extent data item 元数据,分别用来表示文件 file1 和 file2 所使用的磁盘空间。
假设 file1 的大小仅为 15 个字节; file2 的大小为 1M 。如图所示,file2 采用普通的 extent 表示方法:extent2 元数据指向一段 extent,大小为 1M,其内容便是 file2 文件的内容。
而对于 file1, btrfs 会把其文件内容内嵌到元数据 extent1 中。如果不采用 inline file 技术。如虚线所示,extent1 指向一个最小的 extent,即一个 block,但 file1 有 15 个字节,其余的空间便成为了碎片空间。
采用 inline 技术,读取 file1 时只需要读取元数据 block,而无需先读取 extent1 这个元数据,再读取真正存放文件内容的 block,从而减少了磁盘 IO 。
得益于 inline file 技术,btrfs 处理小文件的效率非常高,也避免了磁盘碎片问题。
目录索引 Directory index
当一个目录下的文件数目巨大时,目录索引可以显著提高文件搜索时间。 Btrfs 本身采用 BTree 存储目录项,所以在给定目录下搜索文件的效率是非常高的。
然而,btrfs 使用 BTree 管理目录项的方式无法同时满足 readdir 的需求。 readdir 是 POSIX 标准 API,它要求返回指定目录下的所有文件,并且特别的,这些文件要按照 inode number 排序。而 btrfs 目录项插入 BTree 时的 Key 并不是 Inode number,而是根据文件名计算的一个 hash 值。这种方式在查找一个特定文件时非常高效,但却不适于 readdir 。为此,btrfs 在每次创建新的文件时,除了插入以 hash 值为 Key 的目录项外,还同时插入另外一种目录项索引,该目录项索引的 KEY 以 sequence number 作为 BTree 的键值。这个 sequence number 在每次创建新文件时线性增加。因为 Inode number 也是每次创建新文件时增加的,所以 sequence number 和 inode number 的顺序相同。以这种 sequence number 作为 KEY 在 BTree 中查找便可以方便的得到一个以 inode number 排序的文件列表。
另外以 sequence number 排序的文件往往在磁盘上的位置也是相邻的,所以以 sequence number 为序访问大量文件会获得更好的 IO 效率。
压缩
大家都曾使用过 zip,winrar 等压缩软件,将一个大文件进行压缩可以有效节约磁盘空间。 Btrfs 内置了压缩功能。