 3G Eden
3G Eden RSS
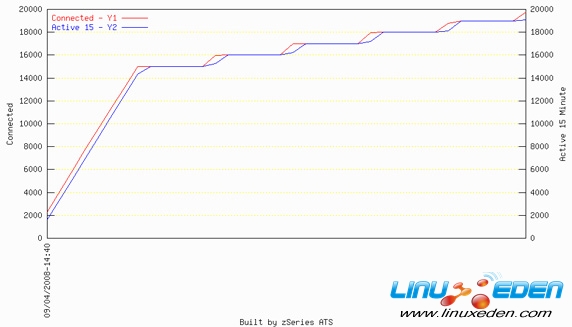
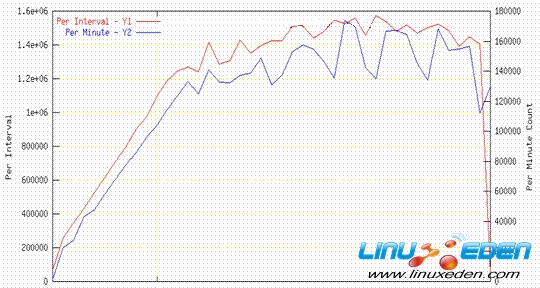
RSS如图 4 所示,我们可以在一个 Lotus Domino 实例中最多达到 19 K 到 20 K 的基准测试用户。
图 4. 单个 Domino PARrtition(DPAR)服务器测试期间已连接/活动了 15 分钟的用户
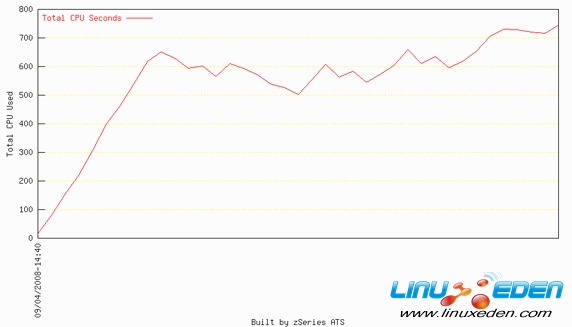
对于这些测试,我们度量了使用的 CP 时间(秒),而不是处理器繁忙时间所占百分比,如图 5 所示。
图 5. 单个 DPAR 测试中使用的 CP 时间(秒)
处理器繁忙时间所占百分比是将使用的资源(CP 时间)除以可用资源得到的计算结果。在过去,这个计算的分子(使用的 CP 时间)是随机的,而分母(可用的物理处理器资源)是静态的。由于等式中的一半是静态的,并且只有当一个单元被升级或替换时结果才会改变,因此处理器繁忙时间所占百分比可以很好地指示当前被使用的资源。然而,在虚拟环境中,分母现在也是随机的值。
最近 5 年多的时间里,在大型企业硬件中,一个给定的虚拟环境中处理器的数量每 10 秒就变化一次。在这些配置上,测试中的可用处理器数量现在是一个分数,因为每一分钟它都要变化数次。例如,这一分钟处理器的数量是 4.5,到下一分钟又变成了 5.166。这种变化意味着现在处理器繁忙时间所占百分比的分子和分母都是随机的,因此这个值在生产虚拟环境中没有用处。而通过度量 CP 时间,可以知道环境所使用的处理器资源的数量,而不是虚拟环境中有多少可用的处理器资源,后者是不断变化的。
在我们的测试中,我们使用一个 10 分钟的收集时间间隔。这个时间间隔意味着在 600 CP 秒(10 分钟 x 60 秒)内,使用相当于一个完整引擎的处理器容量。
虚拟环境的另一个缺点是,处理器繁忙时间所占百分比会令人在理解还剩多少容量时产生误解。如果一个系统有 2 个物理处理器,并且定义了 2 个操作系统映像,每个映像有 2 个逻辑处理器,那么这种配置总共有 4 个逻辑处理器。如果两个操作系统映像都是用虚拟化技术同等对待和管理的,那么当两个操作系统映像的处理器繁忙时间所占百分比为 50% 时,对于物理系统而言处理器是 100% 繁忙,已达到容量的极限。理解了当前使用的资源数量(CP 时间),而不是一个虚拟容量数字的百分比,就可以更好地管理和监视环境。
除了评测使用的资源外,我们还观察了运行基准测试用户的成本。图 6 显示活动了 15 分钟的 Lotus Domino 用户的处理器成本。对于每个抽样周期,将 Lotus Domino 服务器实例使用的处理器时间(秒)除以活动用户的数量,就得到这些数字。
图 6. 每个活动了 15 分钟的用户的处理器成本
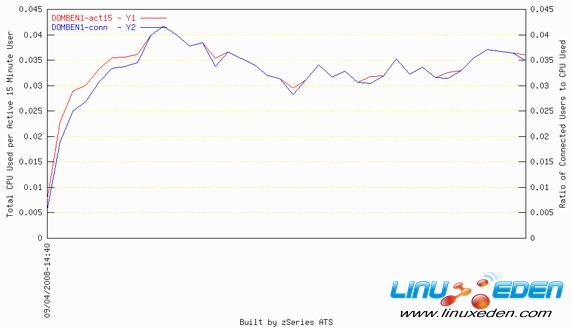
图 6 表明一种有趣但又在意料之中的趋势。每个用户的最高成本发生在基准测试的开始处。由于用户在登录和验证权限,处理开销使成本增加。例如,若在繁忙时段重新启动服务器,那么需要准备好所有用户重新登录该服务器时所需的额外处理器资源。在用户完成身份验证并建立连接会话之后,稳定状态下的成本将降低。
由于这个原因,如果装载上一组用户令处理器的负载达到极限,基准测试往往缩短装载时间,留出一段时间用于评测稳定状态。此外还可以看到,在服务器崩溃之前,在运行结束时,每个用户的成本突然增高,这表明服务器在崩溃之前已经开始受到压力。该测试只有一个 DPAR,并且所有邮件都是本地传递的,因此可以理解,当使用多个 LPAR,并且同时有本地和远程邮件时,每个用户的成本将有所上升。
我们使用这个基准测试的一个目的是看看是否能在一个 Linux guest 中承受 100 K 基准测试用户。根据单个 Lotus Domino 分区服务器测试,我们计算出,在一个 Linux guest 中,6 个 Lotus Domino 分区服务器中的每个 Lotus Domino 分区服务器需要运行 17 K 基准测试用户。我们增加了 5 个额外的 Lotus Domino 分区服务器,将这一个 Linux guest 扩展到 6 个 Lotus Domino 分区服务器中。而且,我们又增加了 4 个 CP,将内存增加到 26 GB,并增加更多 DASD,以支持全部用户负载。
每个 DPAR 在 /notesdatax/mail 路径下都有它自己的 notesdata 目录和 4 个惟一的邮件目录。我们将用于用户邮件箱的 DASD 分布在这些挂载点上。每个 Lotus Domino 分区服务器被定义为在一个单独的用户 ID 下运行,并且有一个惟一的 IP 地址。由于所有这些 Lotus Domino 分区服务器都在相同的物理足迹上,因此可以利用 VLAN,在 Lotus Domino 分区服务器之间以内存速度(从 TCP/IP 缓冲区到 TCP/IP 缓冲区之间的传输)传输数据,而不必通过物理骨干网在服务器之间传输。
第一个 100 K 测试被定义为以和单个服务器测试相同的速度增加到 60 K,然后放缓增加用户的速度。但是,当到达 50 K 用户时,我们开始观察到运行出现问题。邮件开始备份,客户机上的响应时间开始加长。根据对 Lotus Domino 和平台数据的分析,我们检测到一个 I/O 瓶颈。虽然 DS8000® 的响应时间少于 2 毫秒,VM 的响应时间也少于 2 毫秒,但是我们观察到 Linux 内核的响应时间却超过 80 毫秒。
在调查这个问题的过程中,我们尝试了一些测试,看是否能克服这个 I/O 瓶颈。当运行不同的测试时,我们做了以下事情:
- 减少写入到 log.nsf 的数据量
- 将 Linux guest 内存增加到 48 GB
- 增加 NSF_Buffer_Pool 大小
- 将 mail.box(每个 DPAR 有 6 个)移到一个 RAM 磁盘上
- 将 names.nsf 移到一个 RAM 磁盘上
- 将 log.nsf 移到一个 RAM 磁盘上
- 将 mail.box、log.nsf、names.nsf 移到一个 RAM 磁盘上
- 更改 mail.box 的数量
- 更改服务器任务中的线程数
- 更改用于本地和远程邮件传递的路由器任务中的线程数
- 将 Lotus Domino 服务器升级至黄金级 GA 代码
- 设置 MailLeaveSessionsOpen=1
虽然这些变化对于我们遇到的 I/O 瓶颈和可伸缩性问题无济于事,但将 notes.ini 参数 MailLeaveSessionsOpen 设为 1 的确对使用的处理器资源有可观的影响。我们看到,每个活动了 15 分钟的用户的处理器成本从 .07 减少至 .05 秒,这意味着运行相同工作负载所需的处理器资源减少大约 28%。这个参数告诉 Lotus Domino 将不同服务器之间传递邮件的会话保持在开启状态。在设置该参数之前,Lotus Domino 需要建立与接收消息的邮件服务器的会话,进行认证,发送消息,然后撤销会话。如果使会话保持开启状态,Lotus Domino 可以重用已有的会话,而不必重复地建立会话。
最终,我们确定,I/O 问题是由 Linux 支持 ECKD 卷的方式和逻辑设备级别上请求的排队方式引起的。SLES 11 中为并行访问卷(PAV)提供了一个修复,但是这个修复不能用于这一次的基准测试。我们重新配置了 I/O 子系统,将卷划分成较小的 3 GB 的逻辑设备,从而为等量的 DASD 创建更多的逻辑设备。这种配置可以为 Linux 提供更多的逻辑驱动器,从而可以将 I/O 分散到相同的 DS8000 系统上。
重新配置 DASD 后,对于 8 个 CP 的容量而言,最高可以将负载加到大约 85 K 用户。我们再增加 4 个 CP,将 VM 和 Linux guest 可用的 CP 增加到 12 个,以便运行接下来的测试。在不必重新构建、重新分布或者为附加容量而对 Lotus Domino 做出任何更改的情况下,虚拟 guest 和 Lotus Domino 服务器的 CP 数量增加了 50%。
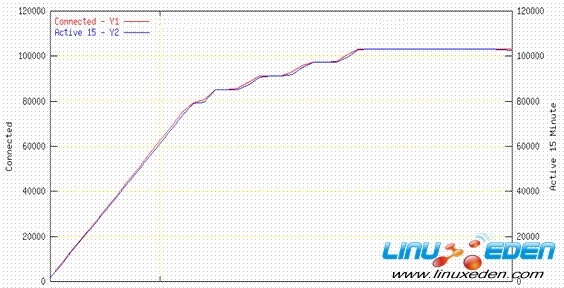
有了这些额外的容量,对于 VM 下运行的一个 Linux guest 中共 102 K 用户的稳定状态,在 6 个 DPAR 的每个 DPAR 中可以达到 17 K 用户的稳定状态。图 7 显示活动了 15 分钟和已连接的用户数。
图 7. 102 K 运行期间的用户数
在稳定状态期间,测试期间平均每 10 分钟有大约 150 万 Lotus Domino 事务,即每小时大约有 900 万 Lotus Domino 事务,如图 8 所示。
图 8. Lotus Domino 事务数量
在运行这些负载时,这个 Linux guest 的总体 I/O 工作负载达到每秒 27 K I/O 的高峰。在 DS8000、VM 和 Linux 内核中的平均响应时间少于 2 毫秒。当运行这些负载时,之前提到的其他工作负载也在同一个服务器上活动,因此这个服务器每秒 I/O 总量要远远大于 Lotus Domino 工作负载导致的 27 K。
对于不同的用户数量,每个用户的处理器成本一直保持稳定,直到达到 80 K 用户。此时,当增加最后 20 K 用户时,每个用户的成本开始增加。我们没有在达到 17 K 用户的单个 DPAR 测试中看到这种处理器成本的增长,也没有在 51 K 用户测试中看到这样的增长,本文后面的小节将描述这个测试,在这个测试中,我们运行多个有 17 K 用户的 Lotus Domino 服务器。每个用户的处理器成本的这种增长似乎与 Linux 内核本身的开销有关。
对于这个基准测试和其他测试,我们看到 VM 下第一个 guest 占用了大约 10% 的开销。此外,此后每个附加的 VM guest(不是 Lotus Domino 分区服务器)有大约 1% 到 2% 的开销。这 10% 的开销分布在 6 个 Lotus Domino 服务器实例上,这意味着对于这种配置,对于这个基准测试,虚拟环境中每个 Lotus Domino 服务器有大约 2% 的开销。但是请注意,并不是所有虚拟化技术和平台都能在单个物理足迹中取得这种级别的可伸缩性、吞吐率和低开销。因此,这些数字不能用于不同于本文的 Lotus Domino 虚拟实现。
垂直和水平可伸缩性
当将 Lotus Domino 基础设施迁移到一个虚拟环境时,应该查看一下已有的基础设施。最快、最容易的方式是将已有的 Lotus Domino 服务器转移到新的环境中。这种方法通常无法充分利用新的虚拟环境。我们执行过一个评测,以估计在两种不同的配置上运行一个给定的工作负载有何不同。为度量这种不同,我们在两种配置上运行相同的工作负载,这两种配置的惟一区别是 Lotus Domino 分区服务器的数量。
在第一个测试中,我们在 3 个 DPAR 上运行 51 K 基准测试用户,并测定每个用户的成本。然后,在相同的虚拟配置中,我们在 6 个 DPAR 上运行同样的 51 K 用户,并测定每个用户的成本。图 9 显示这两个测试的结果。
图 9. 每个用户的处理器成本比较
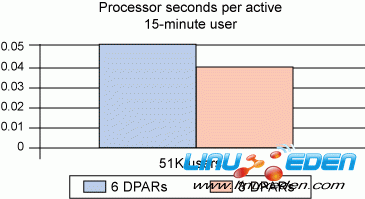
我们可以看到,通过将工作负载整合到更少的 Lotus Domino 分区服务器上,每个用户的处理器成本下降了 20%。在客户和 IBM 的生产环境中,当他们能够执行服务器整合时,我们也看到过服务器成本的这种下降。通过垂直伸缩 Lotus Domino 基础设施(图 1 就是一个例子),不仅可以节省用于运行环境的资源,还可以节省管理成本,因为需要管理、升级和支持的服务器更少了。
要充分利用虚拟技术的优点,关键在于物理/虚拟实现允许为环境增加资源,首先允许垂直增长,而不必水平地重新构建环境。
基准测试已成为事实!
您可能要问:“听起来不错,但是在生产中如何做这些实际工作?”IBM 已经与一个客户合作,成功地将 14 K 生产用户迁移到 2 个 Linux 内核中。VM 下的每个 Linux guest 支持大约 8 TB 的 DASD。每个内核中大约有 7 K 生产用户,每个 guest 运行多个 DPAR。除了邮件服务器外,他们在这两个 Lunch guest 中还有名称服务器和管理服务器,总共在每个 Linux guest 中占 4 个 DPAR。在 64 位 8.5 版 Lotus Domino 代码(允许更大的服务器整合)出现之前,这种配置使用 Lotus Domino 7。这个客户看到他们管理的 Lotus Domino 实例和基础设施设置得到了减少。