 3G Eden
3G Eden RSS
RSSFirefox 中的 Find 命令可以在 Web 页面的主体中定位用户指定的文本。该命令是一个易于使用的工具,大多数用户通常都可以很好地使用该工具。但是,使用更强大的类似 Find 的工具有时可以更轻松地定位文本。本文将介绍如何构建这种工具,通过检测邻近文字的显示和消失更快地隔离 Web 页面中相关的文本。
Firefox 中自带的文本搜索功能提供了实用的可以突出显示邻近搜索词和短语的功能。附加的 Firefox 扩展可用于合并正则表达式搜索与其他文本高亮显示功能。本文将提供向 Firefox 中添加自定义文本搜索界面所需的工具和代码。使用 Greasemonkey 用户脚本和一些自定义算法,您可以将 grep -v 函数添加到文本搜索中 — 也就是说,在第二个搜索词不在附近时高亮显示第一个搜索词。
要求
硬件
用较旧(2002 年以前)的硬件在典型 Web 页面中进行文本搜索几乎可以瞬间完成。但是,本文提供的代码在设计时没有考虑高速执行,并且可能要求使用较快的硬件才能在大型 Web 页面中按照用户满意的速度执行。
软件
本文的代码是为了结合使用 Firefox V2.0 和 Greasemonkey V0.7 而开发的。使用比它们更高的版本需要测试并且可能需要修改才能确保功能性。作为 Greasemonkey 脚本,本文提供的代码应当可以在支持 Firefox 和 Greasemonkey 的任何一个操作系统中运行。我们在 Microsoft® Windows® 和 Linux® Ubuntu V7.10 版本中进行过测试。
Greasemonkey 和 Firefox 扩展
对 Web 页面执行用户修改是 Greasemonkey 履行的任务,并且本文提供的代码将使用 Greasemonkey 框架来搜索和高亮显示相关文本。有关 Greasemonkey Firefox 扩展,请参阅 参考资料。
此 Greasemonkey 脚本的设计目的演示
熟悉 UNIX grep 命令及其常用 -v 选项的人知道如何将不可缺少的 grep 用于从文件提取相关文本行。遵守 UNIX 简单性原则的文本文件通常按照逐行的格式存储文本,这样可以轻松地找到靠近在一起的文字。-v 选项将输出未找到指定文本的行。
与文本文件不同的是,Web 页面通常用标签和浏览器呈现到行中的其他标记分隔文本。各种不同的浏览器窗口大小使您很难根据期望的行位置来隔离邻近文本。表、链接和其他文本标记也使您很难隔离位于 “同一行” 的文本。
本文中的算法旨在解决这些难题,提供类似于 grep 的简单功能,并使用工作原理类似于 grep 的 -v 选项的函数。这将允许用户查找文本的某个词,然后只高亮显示不包含另一个不同词的条目。图 1 显示了这种情况的示例。
图 1. DOM 和 DOM hierarchy 搜索示例
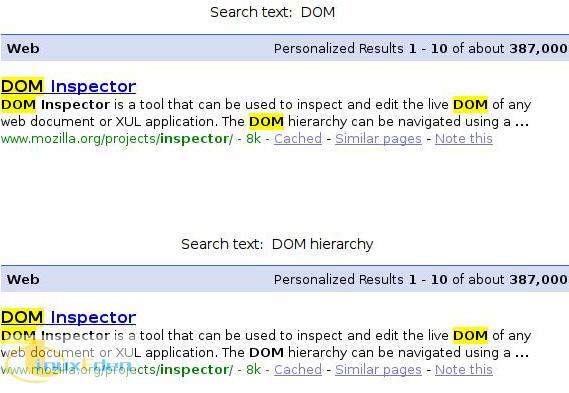
在图像的上半部分中,脚本高亮显示了搜索文本 “DOM”。在下半部分中,注意如何只高亮显示前三个 “DOM” 条目,因为在极为接近第三个 “DOM” 的位置找到了第二个搜索文本 “hierarchy”。
考虑图 2。
图 2. 2008 和 2008 PM 搜索示例
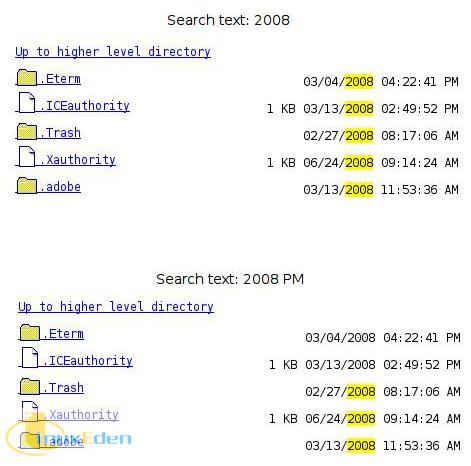
该图的第一部分显示所有 2008 条目,而第二部分由于 -v 关键字 PM,因此只显示中午前的条目。继续阅读获得全部信息以及如何实现此功能的更多示例。
greppishFind.user.js Greasemonkey 用户脚本
介绍 Greasemonkey 编程环境的独特之处不在本文讨论范围之内。假定您熟悉 Greasemonkey,包括如何安装、修改和调试脚本。要获得关于 Greasemonkey 及如何开始编写自定义用户脚本的更多信息,请参阅 参考资料。
一般而言,greppishFind.user.js 用户脚本在载入页面时启动,在输入特定组合键后提供文本区域,并且根据用户输入的文本执行高亮搜索。清单 1 显示了 greppishFind.user.js 用户脚本的开头部分。
清单 1. greppishFind.user.js 程序头
// ==UserScript==
// @name greppishFind
// @namespace IBM developerWorks
// @description grep and grep -v function-ish for one or two word searches
// ==/UserScript==
var boxAdded = false; // user interface for search active
var dist = 10; // proximity distance between words
var highStart = '<high>'; // begin and end highlight tags
var highEnd = '</high>';
var lastSearch = null; // previous highlight text
window.addEventListener('load', addHighlightStyle,'true');
window.addEventListener('keyup', globalKeyPress,'true');
|
在定义描述用户脚本及其函数、全局变量和高亮标签的必要元数据之后,将添加 load 和 keyup 事件侦听程序以处理用户生成的事件。清单 2 详细说明了负载事件侦听程序所调用的 addHighlightStyle 函数。
清单 2. addHighlightStyle 函数
function addHighlightStyle(css)
{
var head = document.getElementsByTagName('head')[0];
if( !head ) { return; }
var style = document.createElement('style');
var cssStr = "high {color: black; background-color: yellow; }";
style.type = 'text/css';
style.innerHTML = cssStr;
head.appendChild(style);
}//addHighlightStyle
|
该函数将用相应的高亮显示的信息在当前的 DOM 结构中创建一个新节点。在本例中,它是简单的黑底黄字文本属性。清单 3 显示了另一个事件侦听程序 globalKeyPress 以及 boxKeyPress 函数的代码。
清单 3. globalKeyPress、boxKeyPress 函数
function globalKeyPress(e)
{
// add the user interface text area and button, set focus and event listener
if( boxAdded == false && e.altKey && e.keyCode == 61 )
{
boxAdded = true;
var boxHtml = "<textarea wrap='virtual' id='sBoxArea' " +
"style='width:300px;height:20px'></textarea>" +
"<input name='btnHighlight' id='tboxButton' " +
"value='Highlight' type='submit'>";
var tArea = document.createElement("div");
tArea.innerHTML = boxHtml;
document.body.insertBefore(tArea, document.body.firstChild);
tArea = document.getElementById("sBoxArea");
tArea.focus();
tArea.addEventListener('keyup', boxKeyPress, true );
var btn = document.getElementById("tboxButton");
btn.addEventListener('mouseup', processSearch, true );
}//if alt = pressed
}//globalKeyPress
function boxKeyPress(e)
{
if( e.keyCode != 13 ){ return; }
var textarea = document.getElementById("sBoxArea");
textarea.value = textarea.value.substring(0,textarea.value.length-1);
processSearch();
}//boxKeyPress
|
捕捉每次击键并且侦听特定组合是 globalKeyPress 的目的。按下 Alt+= 组合键后(即,按住 Alt 键的同时按下 = 键),将把搜索框的用户界面添加到当前 DOM 中。此界面包含输入关键字的文本区域和 Submit 按钮。在添加新条目后,需要通过 getElementById 函数选择文本区域以正确设置焦点。然后添加事件侦听程序以处理文本区域中的击键,并且在单击 Submit 按钮后执行搜索。
清单 3 中的第二个函数将处理文本区域中的每次击键。如果按下 Enter 键,文本区域的值将删除新行并且执行 processSearch 函数。清单 4 详细说明了 processSearch 函数。
清单 4. processSearch 函数
function processSearch()
{
// remove any existing highlights
if( lastSearch != null )
{
var splitResult = lastSearch.split( ' ' );
removeIndicators( splitResult[0] );
}//if last search exists
var textarea = document.getElementById("sBoxArea");
if( textarea.value.length > 0 )
{
var splitResult = textarea.value.split( ' ' );
if( splitResult.length == 1 )
{
oneWordSearch( splitResult[0] );
}else if( splitResult.length == 2 )
{
twoWordSearch( splitResult[0], splitResult[1] );
}else
{
textarea.value = "Only two words supported";
}//if number of words
}//if longer than required
lastSearch = textarea.value;
}//processSearch
|
每次搜索都存储在每次调用 processSearch 时都要删除的 lastSearch 变量中。删除后,如果只有一个查询词或者如果需要 twoWordSearch 函数或 grep -v 函数,则使用 oneWordSearch 高亮显示搜索查询。清单 5 显示了关于 removeIndicators 函数的详细信息。
清单 5. removeIndicators 函数
function removeIndicators( textIn )
{
// use XPath to quickly extract all of the rendered text
var textNodes = document.evaluate( '//text()', document, null,
XPathResult.UNORDERED_NODE_SNAPSHOT_TYPE,
null );
for (var i = 0; i < textNodes.snapshotLength; i++)
{
textNode = textNodes.snapshotItem(i);
if( textNode.data.indexOf( textIn ) != -1 )
{
// find the appropriate parent node with the innerHTML to be removed
var getNode = getHtml( textNode );
if( getNode != null )
{
var temp = getNode.parentNode.innerHTML;
var reg = new RegExp( highStart, "g");
temp = temp.replace( reg, "" );
reg = new RegExp( highEnd, "g");
temp = temp.replace( reg, "" );
getNode.parentNode.innerHTML = temp;
}//if correct parent found
}//if word found
}//for each text node
}//removeIndicators
|
使用 removeIndicators 无需手动遍历 DOM 树,而是使用 XPath 快速提取文档中的文本节点。如果某个文本节点包含 lastSearch 文本(最近高亮显示的词),则 getHtml 将查找相应的父节点,并且删除高亮显示的文本。注意,将 innerHTML 的提取与 innerHTML 的分配合并为一个步骤将带来各种各样的问题,因此需要将 innerHTML 临时指定为外部变量。清单 6 是 getHtml 函数,该函数将详细展示如何查找相应的父节点。
清单 6. getHtml 函数
function getHtml( tempNode )
{
// walk up the tree to find the appropriate node
var stop = 0;
while( stop == 0 )
{
if( tempNode.parentNode != null &&
tempNode.parentNode.innerHTML != null )
{
// make sure it contains the tags to be removed
if( tempNode.parentNode.innerHTML.indexOf( highStart ) != -1 )
{
// make sure it's not the title or greppishFind UI node
if( tempNode.parentNode.innerHTML.indexOf( "<title>" ) == -1 &&
tempNode.parentNode.innerHTML.indexOf("btnHighlight") == -1)
{
return( tempNode );
}else{ return(null); }
// the highlight tags were not found, so go up the tree
}else{ tempNode = tempNode.parentNode; }
// stop the processing when the top of the tree is reached
}else{ stop = 1; }
}//while
return( null );
}//getHtml
|
在遍历 DOM 树搜索 innerHTML 以插入高亮显示的标签时,必须忽略两个特定节点。不应当更新包含 title 和 btnHighlight 的节点,因为这些节点中的更改将导致文档无法正常显示。当找到正确的节点时,无论 DOM 树中的父节点有多少个,都返回节点并删除高亮显示。清单 7 是向文档中添加高亮显示的第一个函数。
清单 7. oneWordSearch 函数
function oneWordSearch( textIn )
{
// use XPath to quickly extract all of the rendered text
var textNodes = document.evaluate( '//text()', document, null,
XPathResult.UNORDERED_NODE_SNAPSHOT_TYPE,
null );
for (var i = 0; i < textNodes.snapshotLength; i++)
{
textNode = textNodes.snapshotItem(i);
if( textNode.data.indexOf( textIn ) != -1 )
{
highlightAll( textNode, textIn );
}//if word found
}//for each text node
}//oneWordSearch
|
再次使用 XPath,oneWordSearch 将处理每个文本节点以找到查询。找到后,将调用 highlightAll 函数,如清单 8 所示。
清单 8. highlightAll 函数
function highlightAll( nodeOne, textIn )
{
if( nodeOne.parentNode != null )
{
full = nodeOne.parentNode.innerHTML;
var reg = new RegExp( textIn, "g");
full = full.replace( reg, highStart + textIn + highEnd );
nodeOne.parentNode.innerHTML = full;
}//if the parent node exists
}//highlightAll
function highlightOne( nodeOne, wordOne, wordTwo )
{
var oneIdx = nodeOne.data.indexOf( wordOne );
var tempStr = nodeOne.data.substring( oneIdx + wordOne.length );
var twoIdx = tempStr.indexOf( wordTwo );
// only create the highlight if it's not too close
if( twoIdx > dist )
{
var reg = new RegExp( wordOne );
var start = nodeOne.parentNode.innerHTML.replace(
reg, highStart + wordOne + highEnd
);
nodeOne.parentNode.innerHTML = start;
}//if the distance threshold exceeded
}//highlightOne
|
类似于 removeIndicators 函数,highlightAll 将使用正则表达式来替换用标记高亮显示的文本(包括高亮显示标签和原始文本)。
稍后在 twoWordSearch 函数中使用的 highlightOne 函数将检查第一个词是否距离第二个词足够远,然后执行相同的替换。需要在从 XPath 语句返回的呈现文本中执行字距检查;否则,诸如 <b> 之类的各个标记将影响距离计算。清单 9 详细说明了 twoWordSearch 函数。
清单 9. twoWordSearch 函数
function twoWordSearch( wordOne, wordTwo )
{
// use XPath to quickly extract all of the rendered text
var textNodes = document.evaluate( '//text()', document, null,
XPathResult.UNORDERED_NODE_SNAPSHOT_TYPE,
null );
var nodeOne;
var foundSingleNode = 0;
for (var i = 0; i < textNodes.snapshotLength; i++)
{
textNode = textNodes.snapshotItem(i);
// if both words in the same node, highlight if not too close
if( textNode.data.indexOf( wordOne ) != -1 &&
textNode.data.indexOf( wordTwo ) != -1 )
{
highlightOne( textNode, wordOne, wordTwo );
foundSingleNode = 0;
nodeOne = null;
}else
{
if( textNode.data.indexOf( wordOne ) != -1 )
{
// if the first word is already found, highlight the entry
if( foundSingleNode == 1 &&
nodeOne.parentNode != null &&
nodeOne.parentNode.innerHTML.indexOf( wordTwo ) == -1 )
{
highlightAll( nodeOne, wordOne );
}//if second word is in the same parent node
// record current node found
nodeOne = textNode;
foundSingleNode = 1;
}//if text match
if( textNode.data.indexOf( wordTwo ) != -1 ){ foundSingleNode = 0; }
}//if both words in single node
}//for each text node
// no second word nearby, highlight all entries
if( foundSingleNode == 1 ){ highlightAll( nodeOne, wordOne ); }
}//twoWordSearch
|
对 XPath 调用检索得到的每个文本节点执行遍历,方法与 oneWordSearch 函数中的执行方法相同。如果在当前文本节点内同时找到两个词,则调用 highlightOne 函数以高亮显示距离 wordTwo 足够远的 wordOne 的实例。
如果两个词不在同一个节点中,则在第一次匹配时设置 foundSingleNode 变量。对于后续匹配,在第二次节点匹配之前,当再次侦测到单个节点时,调用 highlightAll 函数。这将确保高亮显示第一个词的每个实例 — 甚至第二个词不在附近的那些词。在循环过程中,如果隔离了最后一个 wordOne 匹配并且仍然需要高亮显示,则执行最终检查以运行 highlightAll。
将用以上代码创建的文件另存为 greppishFind.user.js,继续阅读获得安装和使用细节。
安装 greppishFind.user.js 脚本
打开安装了 Greasemonkey V0.7 扩展的 Firefox 浏览器,并输入 greppishFind.user.js 所在目录的 URL。单击 greppishFind.user.js 文件,然后应当会看到标准 Greasemonkey 安装弹出。选择 install,然后重新载入页面以激活扩展。
用法示例
在将 greppishFind.user.js 脚本安装到 Greasemonkey 中后,可以通过输入 dom inspector 作为在 www.google.com 中的搜索查询模拟图 1 中所示的示例。显示结果页面时,请按 Alt+= 组合键激活用户界面。键入查询 DOM(区分大小写)并按 Enter 键以查看所有高亮显示的 DOM 条目。将查询更改为 DOM hierarchy,您将看到如何只高亮显示前三个 DOM 条目,如图 1 所示。
选择诸如 file:///home/ 或 file:///c:/ 之类的目录清单以显示类似图 2 中列出的条目。您可能需要更改距离参数或者高亮显示样式才能得到符合搜索条件的结果。
结束语
有了以上代码和已完成的 greppishFind.user.js 程序后,您现在已经为在 Firefox 中实现自己的文本搜索功能打下了基础。虽然此程序主要关注某些词与其他词极为接近的特殊情况,但是它为以后的文本搜索选项提供了框架。
考虑根据第二搜索词的邻近程度为高亮显示词添加颜色变化。扩展 grep -v 词的数目以逐步删除条目。使用本文的代码结合您自己的想法创建新的 Greasemonkey 用户脚本,进一步增强用户查找文本的能力。(责任编辑:A6)