 3G Eden
3G Eden RSS
RSS使用社会网络可以更轻松地获取并聚合数据,从而创建富有革新精神的新 Web 应用程序。但是,仍然必须处理创建可伸缩 Web 应用程序的所有常见问题。现在,使用 Google App Engine (GAE) 也可以简化工作。使用 GAE,可以不必考虑管理应用服务器池的所有事务,而是集中精力创建优秀的 mashup。本文是共分三部分的系列文章 “使用 Eclipse 在 Google App Engine 上创建 mashup” 的第二部分,在本文中,将利用并增强在第 1 部分中构建的应用程序。我们将通过 GAE 的更多数据建模功能来提高性能。然后使用 GAE 的 Memcache 服务进一步提高性能。
关于本系列
在本系列中,将了解如何开始使用 Google App Engine (GAE)。在 第 1 部分 中,了解了如何设置开发环境,以便可以开始创建运行在 GAE 上的应用程序。了解如何使用 Eclipse 简化应用程序的开发和调试。本文是第 2 部分,将使用 Eclipse 构建 Ajax mashup 并将其部署到 GAE 中。最后,在第 3 部分中,将通过为应用程序创建 RESTful Web 服务返回到生态系统,这样其他人就可以使用它创建自己的 mashup。
GAE 是创建 Web 应用程序的平台。使用它的最重要的先决条件是具备 Python 知识,因为要在 GAE 中使用 Python 作为编程语言(目前为 Python V2.5.2)。对于本系列,具备一些典型的 Web 开发技能将会有帮助(例如,HTML、JavaScript 和 CSS 知识)。要针对 GAE 进行开发,需要下载三个软件包。
- Eclipse Classic
- 我使用的是 Eclipse Classic V3.3.2。更新的版本也可以使用。
- Google App Engine SDK
- 阅读 GAE 站点中的官方文档并查找下载 SDK 的链接。
- PyDev
- 使用更新站点 http://pydev.sourceforge.net/ 从 Eclipse 内下载 PyDev,它可以将 Eclipse 转换为 Python IDE。
如何安装后两个软件包已经在 第 1 部分 中讨论过。如果您刚开始使用 Eclipse,请参阅 参考资料 了解入门知识。
增强功能
在 第 1 部分 中,我们构建了一个小型应用程序,用来聚集内容提要并通过 GAE 处理它们。我们可以在此基础上继续开发并将该应用程序部署到 GAE 中,但是在这之前,让我们对它实现一些增强功能。第一组增强与性能有关。第 1 部分的版本将在每次请求页面时从订阅的服务中提取数据。这可能需要花费很长时间,尤其是如果任何一项服务响应较慢或一个用户订阅了多项服务。这是常见问题,但是对于运行在 GAE 上的程序来说,这个问题尤为严重。要让 GAE 具有可伸缩性,就需要减少长时间运行的请求。如果处理时间过长,则会终止该请求并向用户发送一条错误消息。这并不是我们想要的结果,因此将更多地使用 GAE 的数据建模和 Bigtable 特性来提高性能。Bigtable 是用于管理结构化数据的分布式存储系统(有关更多信息,请参阅 参考资料)。还将使用它的 Memcache API 来做出更多改进。
我们将在本文中实现的另一组增强将处理用户体验。通过向应用程序添加 Ajax 元素改进用户界面。不仅将使用 Ajax,还将绑定一些数据建模及缓存增强以进一步提高应用程序的性能。实现了这些增强后,我们就可以将应用程序部署到 GAE 中。首先来看一看数据建模增强。
使用关系
在 第 1 部分 中,我们使用了一个数据模型:Account。它使用了 GAE 的 Expando 属性特性来存储服务的 URL。为了提高性能,需要存储提要中的实际数据。访问 Bigtable 绝不会像访问传统的关系数据库(或者至少是负载较轻的关系数据库)一样快,但是应当比从数据源中提取提要快得多。不过,如果只依赖 Bigtable,则永远得不到新功能。因此,需要跟踪何时提取实时数据并将其插入 Bigtable 中,因此如果数据过时,那么我们可以返回到数据源。
在创建新数据模型之前,还有一件事需要考虑。不同的用户可以拥有相同的提要。提要与帐户之间存在多对多关系。了解这些之后,让我们看一看新模型。清单 1 中显示了修改后的 Account 模型。
清单 1. Account 模型
class Account(db.Model):
user = db.UserProperty(required=True)
|
这里的主要更改是从模型中移除了服务信息。如何确定服务的 URL?该信息已被移到独立的模型级数据结构(目录)中,如下所示:
清单 2. 服务数据
service_templates = {
'twitter': "http://twitter.com/statuses/user_timeline/%s.rss",
'del.icio.us': "http://del.icio.us/rss/%s",
'last.fm': "http://ws.audioscrobbler.com/1.0/user/%s/recenttracks.rss",
'YouTube': "http://www.youtube.com/rss/user/%s/videos.rss",
}
|
这将允许使用简单的字符串替换来创建基于用户名的服务 URL。换言之,使用服务名称(用作 service_templates 字典中的关键字)与用户名(用于对从字典中检索到的值进行字符串替换)组合可以计算 URL。这将把我们引向 Feed 数据模型。
清单 3. Feed 模型
class Feed(db.Model):
service = db.StringProperty(required=True)
username = db.StringProperty(required=True)
content = db.TextProperty()
timestamp = db.DateTimeProperty(auto_now=True)
|
服务和用户名如上所示。服务属性将用作 service_templates 字典中的关键字,而用户名将与该值结合使用以计算 URL。内容属性是从 Web 服务中提取的实际内容。时间戳是提取内容的日期和时间。auto_now=True 将告诉 Bigtable 在每次更新记录时更新属性。需要使用连接表定义 Account 与 Feed 之间的多对多关系,如下所示:
清单 4. AccountFeed 模型
class AccountFeed(db.Model):
account = db.ReferenceProperty(Account, required=True, collection_name='feeds')
feed = db.ReferenceProperty(Feed, required=True, collection_name='accounts')
|
ReferenceProperty 是 Bigtable 用来将一个模型与另一个模型关联起来的工具。它类似于关系数据库中的外键。您可能要注意使用的 collection_name 属性。如果需要在查询中使用引用,则使用它作为指代引用的名称。如果不设置此属性,则它将被设为模型名加上 _set(类似 account_set)。
数据建模已完成。我们已经为提要建立了模型并用多对多关系将这些模型与帐户关联了起来。使用 Bigtable 和 GAE 的 API 可以轻松地为实体建模,但是怎样版本化?我们刚刚从一个版本的数据模型转到另一个版本的数据模型。让我们看看如何在 GAE 中处理此问题。
在开发期间更改模式
修改模式通常十分棘手。幸运的是,在这里仍处于开发模式,在此时更改模式要比在生产应用程序中进行更容易。在开发期间更改模式十分常见,使用 GAE 可以轻松完成。只需要为 GAE 的本地 Web 服务器提供一个附加参数,如图 1 所示:
图 1. 添加用于清理本地数据库的参数
我们只是添加了 --clear-datastore 参数作为传递到启动脚本中的命令行实参。使用 Eclipse 和 PyDev 可以轻松地根据需要添加这些参数。有一点需要注意,Eclipse 将记住这些实参。如果留下实参,它将在每次启动开发服务器时删除本地数据库。这可能不会造成问题,但是应当引起注意。
现在具备了允许使用 Bigtable 存储提要的新模式。从 Bigtable 中查找数据的代价十分高昂。不会像许多开发人员掌握如何使用关系数据库那样快。幸运的是,GAE 提供了额外的 API,可以更快地访问数据:Memcache。
Memcache
GAE 包括内存缓存:Memcache。此内存缓存的灵感来源于流行的开源分布式缓存 memcached,但这是 GAE 的专用实现。它拥有类似的语义:只需在 Memcache 中放置或获得名称-值对。使用 Memcache 可以极大地提高应用程序的性能。
对于 aggroGator 应用程序,将缓存两类内容。首先也是最明显的内容是用户的服务。这只能在 AddService 操作中更改,因此可以很容易地确保缓存的精确性。下面的 Cache 类显示了相关代码。
清单 5. 用户服务缓存
class Cache:
@staticmethod
def setUserServices(account):
userServices = [{'service': accountFeed.feed.service, 'username':
accountFeed.feed.username}
for accountFeed in account.feeds]
if not memcache.set(account.user.email(),
pickle.dumps(userServices)):
logging.error('Cache set failed: userServices')
return userServices
@classmethod
def getUserServices(cls, user):
userServices_pickled = memcache.get(user.email())
if userServices_pickled:
userServices = pickle.loads(userServices_pickled)
else:
account = DB.getAccount(user)
userServices = cls.setUserServices(account)
return userServices
|
下面简单解释了这些代码。首先解释用来在缓存中设置用户服务的静态方法(不依赖于类)。这将使用列表理解(list comprehension)创建对象数组,其中每个对象都是一个服务以及该服务的用户的用户名。用户的电子邮件随后用作 Memcache 的关键字。使用 pickle 模块序列化数据并将其放入 Memcache 中。
getUserServices 方法与之相似。它是一个类方法,因为它是静态的,但是需要能够在丢失缓存时调用 setUserServices 方法。它将尝试检索上面所述的序列化对象。如果在缓存中什么都没找到,它将从 Bigtable 中查找数据并把找到的数据放到缓存中。
提要中的缓存条目使用了类似的策略。这里有一个主要差别:必须注意时效性。毕竟,用户随时都可以创建新条目,并且我们必须返回到数据源。需要使用一个到期策略,如下所示:
清单 6. 条目缓存
class Cache:
#user service methods omitted
@staticmethod
def setEntries(feed):
entries = GenericFeed.entries(feed)
if not memcache.set("%s_%s" % (feed.service, feed.username),
pickle.dumps(entries), CACHE_FEED_TIME):
logging.error('Cache set failed: entries')
return entries
@classmethod
def getEntries(cls, service, username):
entries_pickled = memcache.get("%s_%s" % (service, username))
if entries_pickled:
entries = pickle.loads(entries_pickled)
else:
feed = DB.getFeed(service, username)
entries = cls.setEntries(feed)
return entries
|
这里再次使用了类似的模式。序列化数据并存储在 Memcache 中,这一次结合使用了服务与用户名。这将允许进行跨用户缓存,从而获得更高的效率。当尝试从缓存中载入时,如果丢失了缓存,则将转到 Bigtable。另请注意,使用了 CACHE_FEED_TIME 到期值使缓存中的数据过期。如果不进行设置,Memcache 将把所有内容都保存在缓存中,直至用光内存。对于用户服务和条目,我们将使用 DB 类查询 Bigtable。此类如下所示:
清单 7. DB 访问类
class DB:
@staticmethod
def getAccount(user):
return Account.gql("WHERE user = :1", user).get()
@staticmethod
def getFeed(service, username):
return Feed.gql("WHERE service = :1 AND username = :2", service, username).get()
|
此类将使用非常简单的查询,这些查询都使用 GAE 的 GQL 语法。此语法非常简单,但是是功能强大的 SQL 语法的子集。在上例中,使用了编号的参数,但是也可以使用指定参数以进行更复杂的查询。通过查询 Bigtable 中的提要,实际上使用了 Bigtable 作为另一个缓存层。让我们看看如何通过 Ajax 从客户机协调所有这些高性能缓存。
Ajax
大多数人想到 Ajax 时,都会想到它能够增强用户体验。当然,这是对的,但是 Ajax 有许多其他优点。特别是,有许多架构优点。它允许将大量应用程序逻辑移到客户机中,并且从服务器中检索较少量的数据。在 GAE 上运行并没有改变这一点,但是它可以利用应用程序的可伸缩特性。让我们看一看如何把 Ajax 组织到 aggroGator 应用程序中。
初始页面视图
在上一版的 aggroGator 中,当页面装入后将显示各项服务条目的列表。使用了 Django 样式模板来完成这项工作。为了使页面更具有动态性,需要分离数据与表示逻辑。要查看工作原理,让我们看看如何更改模板。
清单 8. 主页面模板
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN"
"http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
<html xmlns="http://www.w3.org/1999/xhtml" lang="en" xml:lang="en">
<head>
<meta http-equiv="content-type" content="text/html; charset=utf-8" />
<title>Aggrogator</title>
<link rel="stylesheet" href="/css/aggrogator.css" type="text/css" />
<script type="text/javascript" src="/js/prototype.js"></script>
<script type="text/javascript" src="/js/effects.js"></script>
<script type="text/javascript" src="/js/builder.js"></script>
<script type="text/javascript" src="/js/aggrogator.js"></script>
</head>
<body onload="initialize();">
<ul id="cache"></ul>
<img id="spinner" alt="spinner" src="/gfx/spinner.gif"
style="display: none; float: left;" />
<p id="logout">
{{ user.nickname }}
<a href="{{ logout_url }}">Logout</a>
</p>
<div class="clearboth"></div>
<form id="form_addService" onsubmit="addService(); return false;">
<fieldset>
<legend>Add New Service</legend>
<label for="service">Service: </label>
<select name="service" id="service">
<option>twitter</option>
<option>del.icio.us</option>
<option>last.fm</option>
<option>YouTube</option>
</select><br/>
<label for="username">Username: </label>
<input type="text" name="username" id="username" />
<input type="submit" value="Add" />
</fieldset>
</form>
<table>
<tbody style="vertical-align: top;">
<tr>
<td>
<div id="userServices"><span /></div>
<div id="entries"><span /></div>
<td>
<table><tbody id="allEntries"></tbody></table>
</td>
</tr>
</tbody>
</table>
</body>
</html>
|
对于模板,有两个重要的注意事项。首先,它几乎没有任何动态内容 — 只有用户名和登录/退出链接。其次,包括大量 JavaScript。使用 Prototype 和 script.aculo.us JavaScript 库(有关更多信息,请参阅 参考资料)。还包括自定义 JavaScript 库:aggrogator.js。当页面载入时它调用了 initialize() 方法,如下所示:
清单 9. 页面初始化
function initialize() {
getUserServices();
new PeriodicalExecuter(getUserServices, 300);
}
function getUserServices() {
var handler = function(xhr) {
var json = xhr.responseJSON;
if (json.error) {
// display the error
}
else {
cacheStats(json.stats);
userServicesTable(json.userServices);
updateEntries(json.userServices);
}
};
// create options for request
var options = {
method: "get",
onSuccess: handler
};
// send the request
new Ajax.Request("/getUserServices", options);
}
|
正如您所见,初始化代码仅仅调用了另一个函数:getUserServices。它还将启动一个轮询进程以使用 Prototype 的 PeriodicalExecutor 类定期调用 getUserServices。在本例中,它将每 300 秒或者每 5 分钟调用一次 getUserServices。此轮询将提供数据正在从服务器推出(也称为 Comet 或反向 Ajax)的错觉。因此,举例来说,当在 Twitter 中发布新内容后,将把它立即推给 aggroGator 中的用户。
getUserServices 类执行了更多有趣的工作。它发出了一个 Ajax 请求,该请假载入当前用户订阅的服务。然后构建服务表,如下所示:
清单 10. 构建用户服务表
function userServicesTable(json) {
var table = Builder.node('table',
Builder.node('tbody',
function() {
var l = [];
json.each(function(s) {
l.push(Builder.node('tr', [
Builder.node('td',
Builder.node('a', {href: "",
onclick: "getEntries('" + s.service + "', '" +
s.username + "'); return false;"},
s.service + ':' + s.username)
)
]));
});
return l;
}()
)
);
$('userServices').replaceChild(table, $('userServices').firstChild);
}
|
此函数主要使用 script.aculo.us 的 Builder 库创建一个 HTML 表,在其中显示所有用户的服务。在继续之前,让我们看看此服务中使用的数据。正如我们在清单 9 中所见,它要向 GetUserServices 发出请求。这只能在应用程序的 main 方法中配置。
清单 11. 设置路由规则
def main():
app = webapp.WSGIApplication([
('/', MainPage),
('/addService', AddService),
('/getEntries', GetEntries),
('/getUserServices', GetUserServices),
], debug=True)
util.run_wsgi_app(app)
|
正如您所见,/getUserServices URL 被映射到名为 GetUserServices 的新类上。该类如下所示:
清单 12. GetUserServices
class GetUserServices(webapp.RequestHandler):
def get(self):
user = users.get_current_user()
# get the user's services from the cache
userServices = Cache.getUserServices(user)
stats = memcache.get_stats()
self.response.headers['content-type'] = 'application/json'
self.response.out.write(simplejson.dumps({'stats': stats, 'userServices': userServices}))
|
该类十分简单,但是非常强大。它将从 Cache 类中检索数据,该类实际上是位于 Bigtable 和 Memcache 顶部的抽象。然后将数据作为 JSON 传回。有许多第三方库可用于相互转换 Python 对象与 JSON,但是我们不需要这些库。GAE SDK 包括 Django,因此我们将使用 Django 的 django.utils.simplejson 函数把 Python 对象序列化为 JSON。您可能还注意到我们将传回一些缓存统计数据。这些是一些简单的统计数据,比较了在 Memcache 中找到数据的频率与找不到数据的次数。当然,这些数据不是必需的,但是十分有趣,至少对于开发人员是这样。您可以在 Web 页面中制作一段视图源代码以查看这些统计数据。最后,注意将 content-type 头部设为 application/json,这可以向 Prototype 表示有效负荷是 JSON,因此它将为我们处理 JSON 的安全反序列化。
现在我们已经了解了如何通过在 GAE 上运行应用程序处理数据。如果返回到清单 9,则不只是构建服务表。还将通过调用 updateEntries 函数检索每项服务的所有条目。您可以在本文附带的完整代码中找到该函数及处理该函数的 Python 类。它将遵循类似的模式:
- 呼叫服务器
- 在 Memcache 中查找数据
- 如果不在 Memcache 中,则转到 Bigtable
- 如果不在那里,或者数据太旧,则转到数据源
- 将数据序列化为 JSON
- 在客户机中,通过编程方式构建 UI
可以为应用程序构建更多优秀功能,但是从某种程度上说,需要把它部署到 GAE 中。让我们接下来看看如何部署以及如何监视和调试生产应用程序。
部署
部署到生产环境经常是个痛苦的过程。它可能包括用 FTP 传输代码、运行构建等等。但是,使用 GAE 可以轻松完成部署,这是 GAE 的一个特性。有一个名为 appcfg.py 的简单部署脚本,GAE 安装程序应当已经把它放到路径中(如果未使用安装程序,而只是解压缩了包,则它位于 GAE 主目录中)。只需用它的 update 命令及应用程序目录(含有 app.yaml 文件的目录,因为它需要读取此文件)调用此脚本,并且您应当会看到类似清单 13 的内容。
清单 13. 使用 appcfg.py 脚本部署
$ appcfg.py update aggrogator/src/ Loaded authentication cookies from /Users/michael/.appcfg_cookies Scanning files on local disk. Initiating update. Email: your_email@here Password for your_email@here: Saving authentication cookies to /Users/michael/.appcfg_cookies Cloning 7 static files. Cloning 3 application files. Uploading 1 files. Closing update. Uploading index definitions. |
就是这样。现在已经把应用程序部署到 GAE 中。您可以在浏览器中转到该应用程序并尝试使用。您需要在部署前在 GAE 中注册应用程序,因为在 app.yaml 中需要它的名称(如 第 1 部分 中所示)。请不要选用 aggroGator 作为该名称,因为它被用于此应用程序。您可以在此处查看运行中的应用程序:http://aggrogator.appspot.com。
监视应用程序
对于任意一个生产 Web 站点,都需要能够监视并确保它能够正常运行。使用 GAE 可以轻松完成此操作。如果登录到 Google App Engine 中,则将看到您自己的应用程序列表,如下所示:
图 2. 在 GAE 中看到自己的应用程序
单击链接,然后将打开应用程序指示板。
图 3. 应用程序指示板
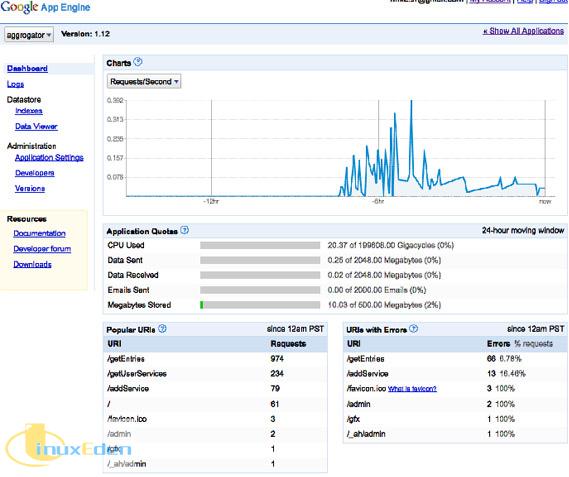
这里有很多有用信息可以使用。最有用的信息之一是日志。当初次部署 aggroGator 应用程序时,它的 del.icio.us 服务没运行。在开发阶段,该服务运行正常,但在生产时却不能正常运行。幸运的是,GAE SDK 将提供日志记录。问题出在从 del.icio.us 中提取 RSS 提要的代码,因此在那里添加了日志记录,如下所示。
清单 14. 添加日志记录代码
class GenericFeed:
@staticmethod
def fetch(service, username):
content = None
# construct service url
service_url = SERVICE_TEMPLATES[service] % username
# fetch feed from service
result = urlfetch.fetch(service_url)
if result.status_code == 200:
content = unicode(result.content, 'utf-8')
else:
logging.error("Error fetching content, HTTP status code = " + str(result.status_code))
return content
|
现在,可以使用 GAE 中的日志控制台查看日志记录,如下所示。
图 4. 日志控制台
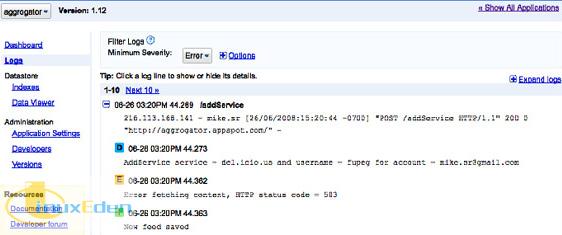
正如您所见,del.icio.us 返回了 HTTP 503(服务不可用状态代码)。代码没问题,只是 GAE 与 del.icio.us Web 站点之间的通信发生错误。
结束语
我们已经了解了如何利用 Google App Engine 的特性为应用程序提供更优秀的可伸缩性和性能。这包括同时使用 Bigtable 和 Memcache 来提供 “昂贵” 数据的缓存 — 需要花费很长时间才能从远程资源中检索到的数据。将此特性与 Ajax 结合使用,您将能够高效地使用 GAE 并且为最终用户提供吸引人的特性,例如从服务器推出数据。在第 3 部分中,将继续增强特性集,进一步探索 GAE 的数据建模功能,并且查看如何将 aggroGator 转换为其他 mashup 的数据提供者。(责任编辑:A6)