 3G Eden
3G Eden RSS
RSS自旋锁(Spinlock)是一种在 Linux 内核中广泛运用的底层同步机制。排队自旋锁(FIFO Ticket Spinlock)是 Linux 内核 2.6.25 版本中引入的一种新型自旋锁,它解决了传统自旋锁由于无序竞争导致的“公平性”问题。但是由于排队自旋锁在一个共享变量上“自旋”,因此在锁竞争激烈的多核或 NUMA 系统上导致性能低下。MCS Spinlock 是一种基于链表的高性能、可扩展的自旋锁,本文详细剖析它的原理与具体实现。
一、引言
自旋锁(Spinlock)是一种在 Linux 内核中广泛运用的底层同步机制,长期以来,人们总是关注于自旋锁的安全和高效,而忽视了自旋锁的“公平”性。排队自旋锁(FIFO Ticket Spinlock)是内核开发者 Nick Piggin 在Linux Kernel 2.6.25[1] 版本中引入的一种新型自旋锁,它通过保存执行线程申请锁的顺序信息解决了传统自旋锁的“不公平”问题[4]。
排队自旋锁仍然使用原有的 raw_spinlock_t 数据结构,但是赋予 slock 域新的含义。为了保存顺序信息,slock 域被分成两部分,低位部分保存锁持有者的票据序号(Ticket Number),高位部分则保存未来锁申请者的票据序号。只有 Next 域与 Owner 域相等时,才表明锁处于未使用状态(此时也无执行线程申请该锁)。排队自旋锁初始化时 slock 被置为 0,即 Owner 和 Next 置为 0。内核执行线程申请自旋锁时,原子地将 Next 域加 1,并将原值返回作为自己的票据序号。如果返回的票据序号等于申请时的 Owner 值,说明自旋锁处于未使用状态,则直接获得锁;否则,该线程忙等待检查 slock 的 Owner 部分是否等于自己持有的票据序号,一旦相等,则表明锁轮到自己获取。线程释放锁时,原子地将 Owner 域加 1 即可,下一个线程将会发现这一变化,从忙等待状态中退出。线程将严格地按照申请顺序依次获取排队自旋锁,从而完全解决了“不公平”问题。
但是在大规模多处理器系统和 NUMA系统中,排队自旋锁(包括传统自旋锁)存在一个比较明显的性能问题:由于执行线程均在同一个共享变量 slock 上自旋,申请和释放锁的时候必须对 slock 进行修改,这将导致所有参与排队自旋锁操作的处理器的缓存变得无效。如果排队自旋锁竞争比较激烈的话,频繁的缓存同步操作会导致繁重的系统总线和内存的流量,从而大大降低了系统整体的性能。
二、MCS Spinlock 的原理
为了解决自旋锁可扩展性问题,学术界提出了许多改进版本,其核心思想是:每个锁的申请者(处理器)只在一个本地变量上自旋。MCS Spinlock[2] 就是其中一种基于链表结构的自旋锁(还有一些基于数组的自旋锁)。MCS Spinlock 的设计目标如下:
- 保证自旋锁申请者以先进先出的顺序获取锁(FIFO Ordering)。
- 只在本地可访问的标志变量上自旋。
- 在处理器个数较少的系统中或锁竞争并不激烈的情况下,保持较高性能。
- 自旋锁的空间复杂度(即锁数据结构和锁操作所需的空间开销)为常数。
- 在没有处理器缓存一致性协议保证的系统中也能很好地工作。
MCS Spinlock采用链表结构将全体锁申请者的信息串成一个单向链表,如图 1 所示。每个锁申请者必须提前分配一个本地结构 mcs_lock_node,其中至少包括 2 个域:本地自旋变量 waiting 和指向下一个申请者 mcs_lock_node 结构的指针变量 next。waiting 初始值为 1,申请者自旋等待其直接前驱释放锁;为 0 时结束自旋。而自旋锁数据结构 mcs_lock 是一个永远指向最后一个申请者 mcs_lock_node 结构的指针,当且仅当锁处于未使用(无任何申请者)状态时为 NULL 值。MCS Spinlock 依赖原子的“交换”(swap)和“比较-交换”(compare_and_swap)操作,缺乏后者的话,MCS Spinlock 就不能保证以先进先出的顺序获取锁,从而可能造成“饥饿”(Starvation)。
图 1. MCS Spinlock 示意图
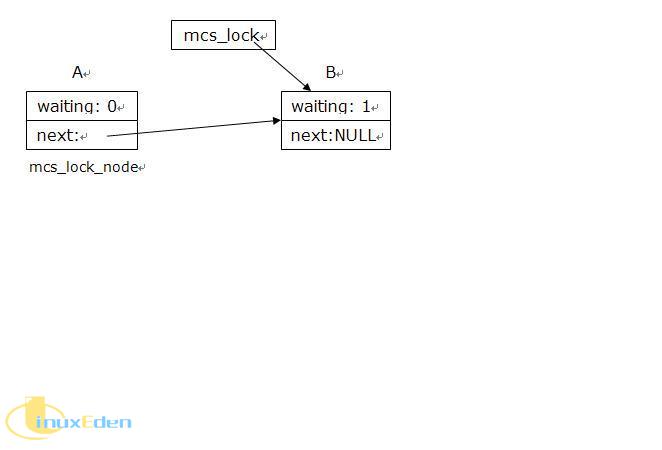
MCS Spinlock 申请操作描述如下:
- 申请者 B 使用原子交换操作将自旋锁 mcs_lock 指向自己的mcs_lock_node 结构以确定在链表中的位置,并返回 mcs_lock原来的值 pre_mcs_lock。即使多个执行线程同时申请锁,由于交换操作的原子性,每个执行线程的申请顺序将会被唯一确定,不会出现不一致的现象。
- 如果 pre_mcs_lock 为 NULL,表明锁无人使用,B 立即成为锁的拥有者,申请过程结束。
- 如果 pre_mcs_lock 不为 NULL,则表明 pre_mcs_lock 指向申请者的直接前驱 A 的 mcs_lock_node 结构,因此必须通过pre_mcs_lock 来修改 A 的 next 域指向自己,从而将链表构建完整。
- 最后 B 在自己的mcs_lock_node 结构的 waiting 域上自旋。当 B 的直接前驱 A 释放自旋锁时,A 只须将 B 的 waiting 域修改为 0 即可。
MCS Spinlock 释放操作描述如下:
- 释放自旋锁时,锁的拥有者 A 必须十分小心。如果有直接后继 B,即 A 的 mcs_lock_node 结构的 next 域不为 NULL,那么只须将 B 的 waiting 域置为 0 即可。
- 如果 A 此时没有直接后继,那么说明 A “可能”是最后一个申请者(因为判断是否有直接后继和是否是最后一个申请者的这两个子操作无法原子完成,因此有可能在操作中间来了新的申请者),这可以通过使用原子比较-交换操作来完成,该操作原子地判断 mcs_lock 是否指向 A 的 mcs_lock_node 结构,如果指向的话表明 A 是最后一个申请者,则将mcs_lock 置为 NULL;否则不改变 mcs_lock 的值。无论哪种情况,原子比较-交换操作都返回 mcs_lock 的原值。
- 如果A 不是最后一个申请者,说明中途来了新的申请者 B,那么 A必须一直等待 B 将链表构建完整,即 A 的 mcs_lock_node 结构的 next 域不再为 NULL。最后 A 将 B 的 waiting 域置为 0。
三、MCS Spinlock 的实现
目前 Linux 内核尚未使用 MCS Spinlock。根据上节的算法描述,我们可以很容易地实现 MCS Spinlock。本文的实现针对x86 体系结构(包括 IA32 和 x86_64)。原子交换、比较-交换操作可以使用带 LOCK 前缀的 xchg(q),cmpxchg(q)[3] 指令实现。
为了尽量减少工作量,我们应该重用现有的自旋锁接口[4]。下面详细介绍 raw_spinlock_t 数据结构,函数__raw_spin_lock、__raw_spin_unlock、 __raw_spin_is_locked 和 __raw_spin_trylock 的实现。
1. raw_spinlock_t 数据结构
由于 MCS Spinlock 的申请和释放操作需要涉及同一个mcs_lock_node 结构,而且这个结构在现有的接口函数中并不存在,因此不适合使用接口函数的局部变量或是调用接口的外层函数的局部变量。一个简单的方法是在raw_spinlock_t 数据结构中为每个处理器预备一个 mcs_lock_node 结构(因为申请自旋锁的时候会关闭内核抢占,每个处理器上至多只有一个执行线程参与锁操作,所以只需要一个 mcs_lock_node)。在 NUMA 系统中,mcs_lock_node 结构可以在处理器所处节点的内存中分配,从而加快访问速度。为简化代码,本文的实现使用 mcs_lock_node 数组。
清单 1. raw_spinlock_t 数据结构
typedef struct mcs_lock_node {
volatile int waiting;
volatile struct mcs_lock_node *next;
} mcs_lock_node;
typedef volatile mcs_lock_node *mcs_lock_node_ptr;
typedef mcs_lock_node_ptr mcs_lock;
typedef struct {
mcs_lock slock;
mcs_lock_node nodes[NR_CPUS];
} raw_spinlock_t;
|
因为 waiting 和 next 会被其它线程异步修改,因此必须使用 volatile 关键字修饰,这样可以确保它们在任何时间呈现的都是最新的值。
2. __raw_spin_lock 函数
清单 2. __raw_spin_lock 函数
static __always_inline void __raw_spin_lock(raw_spinlock_t *lock)
{
int cpu;
mcs_lock_node *me;
mcs_lock_node *tmp;
mcs_lock_node *pre;
cpu = raw_smp_processor_id(); (a)
me = &(lock->nodes[cpu]);
tmp = me;
me->next = NULL;
pre = xchg(&lock->slock, tmp); (b)
if (pre == NULL) {
/* mcs_lock is free */
return; (c)
}
me->waiting = 1;
pre->next = me; (d)
while (me->waiting) { (e)
continue;
}
}
|
- raw_smp__processor_id() 函数获得所在处理器的编号,用以索引 mcs_lock_node 结构。但是此处直接使用 raw_smp__processor_id() 函数会有头文件循环依赖的问题。这是因为 raw_smp_processor_id 在 include/asm-x86/smp.h 中实现,该头文件最终会包含 include/asm-x86/spinlock.h,即 __raw_spin_lock 所在的头文件。我们可以简单地将 raw_smp__processor_id() 的代码复制一份到 spinlock.h 中来解决这个小问题。
- 将 lock->slock 指向本地的 mcs_lock_node 结构,使用原子交换操作。因为 me 变量随后还要使用,故用一局部变量 tmp 与 lock->slock 互换值。
- 锁处于空闲状态,直接返回。
- 设置前驱的 next 指针。
- 在本地 waiting 域上自旋。
3. __raw_spin_trylock 函数
清单 3. __raw_spin_trylock 函数
static __always_inline int __raw_spin_trylock(raw_spinlock_t *lock)
{
int cpu;
mcs_lock_node *me;
cpu = raw_smp_processor_id();
me = &(lock->nodes[cpu]);
me->next = NULL;
if (cmpxchg(&lock->slock, NULL, me) == NULL) (a)
return 1;
else
return 0;
}
|
(a) 该函数的语义是:如果锁空闲,则获得锁并返回 1;否则直接返回 0。当且仅当 lock->slock 为 NULL 时表明锁空闲,所以使用原子比较-交换操作测试lock->slock 是否为 NULL,如不是则与 me 变量交换值。
4. __raw_spin_unlock 函数
清单 4. __raw_spin_unlock 函数
static __always_inline void __raw_spin_unlock(raw_spinlock_t *lock)
{
int cpu;
mcs_lock_node *me;
mcs_lock_node *tmp;
cpu = raw_smp_processor_id();
me = &(lock->nodes[cpu]);
tmp = me;
if (me->next == NULL) { (a)
if (cmpxchg(&lock->slock, tmp, NULL) == me) { (b)
/* mcs_lock I am the last. */
return;
}
while (me->next == NULL) (c)
continue;
}
/* mcs_lock pass to next. */
me->next->waiting = 0; (d)
}
|
- 判断是否有后继申请者。
- 判断自己是否是最后一个申请者,若是的话就将 lock->slock 置为 NULL。
- 中途来了申请者,自旋等待后继申请者将链表构建完成。
- 通知直接后继结束自旋。
5. __raw_spin_is_locked 函数
清单 5. __raw_spin_is_locked 函数
static inline int __raw_spin_is_contended(raw_spinlock_t *lock)
{
return (lock->slock != NULL); (a)
}
|
- lock->slock 为 NULL 就表明锁处于空闲状态。
四、总结
MCS Spinlock 是一种基于链表的可扩展、高性能、公平的自旋锁,申请线程只在本地变量上自旋,直接前驱负责通知其结束自旋,从而极大地减少了不必要的处理器缓存同步的次数,降低了总线和内存的开销。笔者使用 Linux 内核开发者 Nick Piggin 的自旋锁测试程序对内核现有的排队自旋锁和 MCS Spinlock 进行性能评估,在 16 核 AMD 系统上,MCS Spinlock 的性能大约是排队自旋锁的 8.7 倍。随着大规模多核、NUMA 系统的广泛使用,MCS Spinlock 一定能大展宏图。(责任编辑:A6)