 3G Eden
3G Eden RSS
RSSǰ�����ڰٶ��������ϣ��ٶ���ϯ��ѧ��������״���������Űٶ����ѧϰƽ̨�����ƶ��˹����ܼ����Ŀ����ռ�������������ͼ��ʶ������ʶ����Ȼ���Դ������û�������з������˹������������������������Ϊ�������ṩ��һ�����ܸ�ȫ��Ч�����õ����ѧϰ��ܡ�
��ʵ���ٶȺ����Ӷ��ڿ�Դ������ʹ�ã�ҲԸ����ڲ��ļ����Կ�Դ����ʽ���׳�����������10��22���ɰٶȿ��������ġ��ٶȿ�ԴίԱ�����Ͼٰ�ĵ�67��“�ٶȿ�Դר��”����ɳ���ϣ����ٶȵĹ���ʦ��������������ֱ�����˰ٶȿ�Դ������������Ŀ��PaddlePaddle �ٶ����ѧϰ��ܺͰٶ������ܹ���Դ��Ʒ�ߣ����� Tera��BFS��Galaxy �ȣ�������Ͼ���IJ�Ʒ�����������ٶȿ�Դ��������ʵ�����顣Ŀǰ��Щ��Ŀ���Ѿ��� github/baidu �Ͽ�Դ��
ʲô�� PaddlePaddle ���ѧϰƽ̨��
���������Ľ��ܣ�PaddlePaddle �ǰٶ������з����������ȡ�������õ����ѧϰƽ̨����һ���Ѿ�����ͽ�Ҫ���һЩʵ�������ƽ̨��Ŀǰ�ٶ��г���30����Ҫ��Ʒ����ʹ�� PaddlePaddle�����ڻ���ѧϰ�����ѧϰ��dz��ѧϰ�����ݾͲ���ϸ�����ˣ��������ص㽲��һ�� PaddlePaddle ������ܹ���
���� PaddlePaddle ����ܹ�
˵�� PaddlePaddle ������ܹ�����Ҫ���⼸���������֣�������мܹ����� GPU ���мܹ���Sequence ����ģ�ͺʹ��ģϡ��ѵ��������IJ��мܹ�������ģ�͵�ʵ�ֶ���ʵ����������ӵĶ�������ô������ôʵ��ȫ���ӣ�
PaddlePaddle ��2013������ʱ�Ƚ����еļܹ��� Pserver �� Trainer �ļܹ����ڶ�����мܹ������ݷ��䵽��ͬ�ڵ㣬��ͼ���ɫ���ֱ�ʾ�������������ʾһ�����̣�Pserver �� Trainer �Ƿֲ�������������м�IJ���������ͨѶ���ӡ�

����������һ��ʲô�Ǵ��ģϡ��ģ��ѵ����ϡ��ģ��ѵ����˵����������ϡ��ģ�����ϡ�����룬��ô��ɫ����Ԫ��������ѵ���ж�û�����ã���ɫ��Ԫ�������0����ɫ���ӵ��ݶ���0���ݶ���0�Ļ����� SGD ������Ȩ�ء�����ֻ����ɫ�������м�ֵ����Ҫ�� PServer ������������²�������Ҫ�����ݶȣ������ݶȴ��ͻز�����������������ͼ��

�����������ᵽ�ģ�����������������µ�ϡ��ģ�ͣ�
- ���ģϡ��ģ�ͣ��������——ÿ�� Trainer Prefetch ��������Ҫ�IJ����ͷ�����ͨ�š�
- ���ģϡ��ģ�ͣ�����——�� SGD ȷʵ���ݶ�Ϊ0��ʱ��ȥ���²��������Ǽ������Ͳ�һ���ˣ�����L2������Ҫ�������2����������С��
PaddlePaddle ʵ��ʱ��һЩ˼��
���� OP�����������ǻ��� Layer���㣩��
- ���� OP——�Ӿ���˷�����һ��һ����Ӧһ��һ����ѧ���㡣
- ���ڲ�——ֱ��дһ��ȫ���Ӳ㣬LSTM �㡣
- ���� OP ������ Tensorflow——�������������о���Ա�����µĶ���
- ���� Layer ������ Caffe——�����ã���ϸ�ڱ�¶�ĸ��٣��������Ż���
���� OP ���ǻ��� Layer��——֧�ִ� Layer������Ҳ֧�ִ� OP ��ʼ�����磨����˷����ӷ�������ȵȣ������ڳ��͵� Layer��LSTM��ʹ�� C++�����Ż���ԭ�����ڣ�PaddlePaddle ����ҵ�����������Ŀ�ܣ����Ǵ���Ŀ��п�ܣ���ҵ��Ҫ���ܣ�Ҳ��Ҫ����ԡ�
���ͨ�Ż��� MPI ���� Spark ���� K8s + Docker��PaddlePaddle �ײ�ͨ�Ų��������κ������ܣ�PaddlePaddle ����������������Լ���Դ�����������ڶ̣��������м��ܣ����������ʧ�ܣ����checkpoint����ͬʱ��PaddlePaddle ��������Ҫ�����ܣ���ͷ��д�������������ܵ��ţ�RDMA ���Ը��õ�֧�֡�ͬ����PaddlePaddle �ײ㲻�����κ� GPU ͨ�ſ�ܡ�
�ٶ�������Դ�����ܹ�
�������ǰٶ����������ܹ������ˣ������ɳ���Ͻ����˰ٶȵ�ǰ�������������棬�Լ��������汳����¼����ص㲿���ǰٶ�����Դ�Ļ����ܹ�����վ���������ֲ�ʽ���ݿ⡢�ļ�ϵͳ������ϵͳ���ֲ�ʽЭ����������ͨ�ſ�ܡ�������һһ���ܡ�
��ǰ���û�ͨ����������������������ڲ��ϵı仯���������������������֮ǰ�ļ��ܱ�����ڵļ����ӣ�֮ǰ����֮�ڿ��Դ��������ڵ����ݣ�����Ҫ�ڼ�����֮�ڴ��������ڵ����ݣ����Ǹ�������ì�ܡ���ʵ����������ǹ���һ�������ݴ���ƽ̨��Ҳ��֮Ϊ“�����ܹ�ϵͳ”����������ܹ�ϵͳĿ�������Ǻ�����Ŀ�����ݡ���ξ������ڼ�Ⱥ�����ʵı�֤����������ʿ����� CPU �����ʣ�����Ϊ���ʡ�ɱ���

������Լ���һ�°ٶ��ڴ��¿�����ƽ̨——baidu stack������ͼ�������ƽ̨�����㣬��ĵײ�������ͨѶ����һ�������ܵ� RPC ��ܣ���������е������������ε������ϲ��ϵͳ�ڿ����в���Ҫ�����������ˡ��м�һ���ǻ����������ֲ�ʽ�ļ�ϵͳ������������ݴ������ڶ����Ǽ�Ⱥ����ϵͳ�������������ݿ����ó������ô��ۺ�С�������Ƿֲ�ʽ��Э������һ�������������֣�������Ƿֲ�ʽ�����ϲ��Ǻ������ݿ�����ݴ���ϵͳ���������Ͽ��Խ�����ϵͳ�� Hadoop ��ص�ϵͳ��ȡ����м����˵��Hadoop �� HDPS��Hadoop �ڷֲ�ʽ�������ʹ�� Cukaber������Ҳ�� Storm��Spark ��Щ�����������ܹ�ϵͳ�����˼������������һ�Ƿֲ㡣������ Hadoop ϵ���ǹȸ裬���Ƕ�ʹ�����Ƶ�˼�룬���˼����Ҫ�Ƿֹ��ͽ��ã��ò�ͬ�ֹ������ͬ���⡣����һ��˼����Ǹ�Ч������û��Դ����ٶȵ��������ٶ���Ҫʹ�� SSD���������������ֲ�ʽ�����ܹ���ȫ���� C++ʵ�ֵġ������Ǻ��ĵ����ݿ� Tera���������� Tera ���ݿ�ĺ��Ĺ��ܣ�����ȫ�������Զ����ѡ��ϲ���֧�ֿ��ա�
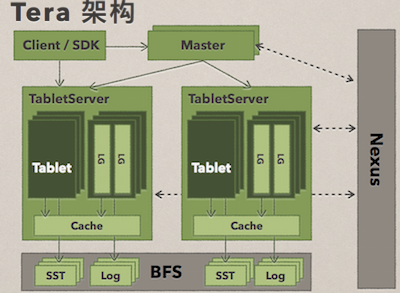
Tera �ļܹ����Կ������ϼ�ͼ������ͼ�����ǿ��Կ������к��ľ�����ɫ�����֣��� Master �� TableServer���ṩ�������ݽڵ㶼�� TableServer�����еķ��ʾ��� Master��������չ����ǧ̨�������С���ɫ�ĵײ����ݶ����ڷֲ�ʽ�ļ�ϵͳ�ϣ�����û���κ����ݣ�����Ƴ���״̬����һ�� TableServer 崻��������һ��������ȡ���ݣ��������κ���ʧ��ͬ���ײ�ķֲ�ʽ�ļ�ϵͳ�����ṩ�ܴ�İ���������ͨ�� Nexus ���ġ�
�������һ�� Tera �ĺ��ļ�����⽔ˮƽ��չ�������������㣻���߷��ѡ��ϲ���⾃�Զ����ؾ��⣻ͨ�� LSM-Tree ����ʵʱͬ�������� Tera �����ж�����֧�ֵ��ص㡣Tera �ڰٶ��ڲ��зdz��㷺��Ӧ�ã�����ٶȵ���ҳ��, �ٶȽ�������������ҳ�洢�� Tera �С�
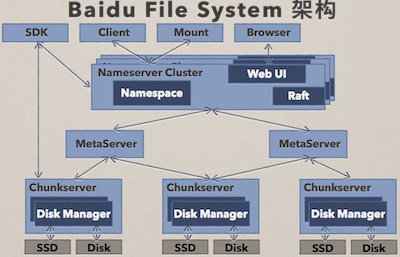
�����ٽ���һ������ͼ�İٶ��ļ�����ϵͳ��BFS���������ڰٶȣ�BFS ���ⲿ��ʹ�ü�ֵҲ�Ǻܸߵġ���ô BFS ������Щ�ص��أ������dz�����⽤���ֲ�ʽ Master��������������ࡣ��ξ���ʵʱ�����£����ڵ㴦理��Ԫ���ݹ�理��
��Ϊƪ������ԭ������ͽ�����ô�࣬������ϸ�����ݣ���ҿ���������λ��ʦ���ݽ� PPT��Ҳ���Թۿ����������������ݽ���Ƶ��