 3G Eden
3G Eden RSS
RSS写在之前
当Spotify的用户打开客户端听歌或者搜索音乐人,用户的任何一个触发的事件都会传送回Spotify的服务器。事件传输系统(也即,日志收集系统)是个有趣的项目,确保全球用户使用Spotify客户端所产生的事件都完全、安全的发送到数据中心。在本系列文章中,将讲述Spotify在这方面所做过的工作,而且会详细解说Spotify新的事件传输系统架构,并回答“为什么Spotify会基于Google云平台管理建立自己的新系统?”。
在本文章中,首先会阐述当前事件传输系统是如何工作,并分享一些在此架构下的实践经验;在下篇文章里,将描述新事件传输系统的架构设计,更进一步的,解释Spotify为什么会选择Google云平台的Cloud Pub/Sub服务作为所有事件的传输机制;在第三篇,将展示Spotify公司如何消费从Google的DataFlow订阅的事件数据,并分享Spotify技术团队采用这一方案的经验总结。
Spotify的事件传输系统有很多用途,Spotify大部分产品的设计策略是基于A/B test的结果,而这些A/B test得依赖于海量、精确的用户数据。Spotify 2015年发布最受欢迎的特色功能之一是“Discover Weekly”播放列表,它是基于Spotify用户播放数据。“Year in music”、“Spotify Party”等其他特色的模块都是对用户播放数据进行数据分析的结果,同时Soptify的用户数据也是Billboard榜单的数据源。
事件传输系统是Spotify公司数据基础设施,它能保证数据以预期的延迟时间完整的传输,并且通过事先定义好的接口发送数据给开发者。用户数据是开发者事先埋点用户点击后产生的结构化数据。
Spotify大部分事件都是响应用户在Spotify客户端的行为而触发的事件,事件在客户端发生后通过日志收集系统syslog发送到Spotify网关,这些数据通过事件传输系统时都会记录时间戳。为了能监测事件传输和事件传输的完整性,事件记录采用syslog时间戳而不是事件在客户端发生的时间戳,因为在事件传到Spotify服务器前是无法控制事件。
在Spotify公司,所有的用户数据需要发送到中心的Hadoop集群。Spotify收集数据的服务器位于两个州的多个数据中心,但是数据中心之间的带宽是紧缺的资源,因此需要时刻监控带宽的占用情况。
数据接口是根据存储数据的Hadoop的位置和存储的格式来定义的,Soptify所有通过事件传输服务传输的数据都是以Avro格式存储在HDFS上。传输的数据都是以小时来分桶,这么做的原因是系统遗留问题:Spotify公司第一个事件传输系统是简单的用scp命令,然后按小时从所有的服务器上把syslog文件复制到Hadoop集群。现在Spotify公司所有的数据任务还是按小时分片的,这种接口形式预期将来一段时间还是不会变。
Spotify的大部分数据读取任务是从小时桶里读取一次。一个job的输出会作为另外一个job的输入,这样形成一个长的转运job链。中间传输的job每小时传输一次,并且不做任何数据检查,即使在数据操作的过程中数据源发生了变化。一般出现小时桶里的数据发生变化需要手动去强制启动整个job链,相应的下游job就会按指定的时间运行。显然地,这是一个耗时耗力的处理过程,并且没有数据回滚的机制,因此需要一个事件传输服务来解决这个问题。数据完整性问题同时也带来的数据传输的延迟,你可以从Google的Dataflow论文里看到对数据完整性问题的有意思的看法。
当前使用的事件传输系统
系统设计
现在Spotify公司生产环境上使用的系统是基于Kafka 0.7版本。
(点击放大图像)
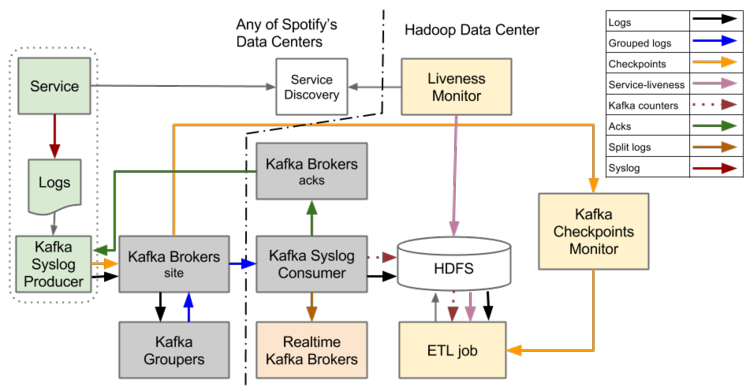
图1:基于Kafka 0.7点事件传输系统架构图
Spotify线上运行的事件传输系统是按每小时文件抽象所设计的,它支持从服务器到HDFS的流式日志文件,包含事件数据。当所有的日志文件按小时传输到HDFS上的过程中会做一个日志格式转化,将原始的Tab键分隔的文本转化成Avro格式。
当线上正运行的事件传输系统上线时,Kafka 0.7版本的Kafka Broker集群还未能实现稳定的持久化,这导致数据生产者、Kafka Syslog生产者和Hadoop集群之间不能进行持久化。所以等到事件数据写入文件或者HDFS才能认为数据已经持久化了。
事件数据到达Hadoop集群并不能达到可靠的持久化,这里又面临一个问题:事件传输系统中Hadoop集群的单点问题,如果Hadoop集群宕机则事件传输系统即挂掉。为了解决这一问题,Spotify公司确保所有收集事件数据的服务器上有足够多的磁盘空间,当Hadoop集群挂掉了,事件数据先缓存到服务器上,等Hadoop集群恢复后立即传输所有数据,这种传输策略到恢复时间主要受限于两个数据中心的带宽。
每个服务主机上都有一个Producer守护进程,它监控这日志文件并按行批量发送日志数据到Kafka Syslog消费者。Producer并不会关注事件类型或者事件属性,它仅仅把区分日志文件的行数据,并且把所有数据发送到相同的channel。这意味着所有的事件类型都包含在相同的日志文件里,并且发到同一个channel里。Producer发送日志到Consumer后,需要等到Consumer成功的把日志持久化到HDFS,并返回ACK给Producer。当Producer收到成功的ACK后继续发送后面的日志。
Producer上的事件数据传到Consumer需要经过Kafka Brokers和Kafka Groupers。Kafka Brokers是Kafka的标准组件,而Kafka Groupers是由Spotify工程师开发的,Grouper消费本地数据中心的所有事件数据,并进行压缩、批量的发送到Consumer的单个topic。
接下来是数据清洗(ETL)的过程,将Tab分隔的文本文件转化成Avro格式。这个job只是一个常规的Hadoop MapReduce任务,采用Crunch框架开发。
所有的Producer都会持续发送文件结束标记的检查点信息(checkpoint),当一个文件全部持久化到Hadoop集群后,Producer会有且仅有发送一次文件结束标记。生命周期监控持续不断的去查询各数据中心的服务发现系统,探测在某个小时内服务器是否在线。为了确定某个小时的数据是否全部传送到数据中心,ETL任务会去校验服务器文件的结束标记,如果ETL的job探测到数据未全部收到,它会延迟处理当前小时到数据。
为了最大化利用mapper和reducer,ETL的job需要知道如何共享输入数据,并且基于Consumer传过来的事件数来优化共享。
总结
上述事件传输系统的设计主要缺点之一:本地Producer需要确认发送的数据被持久化存储的数据中心位置。在美国西海岸的服务器,Producer需要知道数据什么时间写入到London数据中心。大部分情况下系统工作正常,一旦传输变慢将引起传输延迟并很难恢复。
对比这个问题,需要将转移点放在本地数据中心,这简化里Producer的设计,只要数据中心的网络正常即可。
暂且放下这些问题,接下来计划构件一个事件传输系统能够可靠的每秒钟推送70万个事件。重新设计这个事件传输系统同时给Spotify团队一个机会提高软件的开发过程。
所有的事件一起发送到相同的channel,这会失去对不同QoS的事件流的灵活管理。同时也会限制实时数据使用,因为任何实时的消费者需要过滤数据,仅仅获取有用的信息。
发送非结构化数据会带来不必要的延迟,因为清洗任务会带来额外的数据转移,当前运行的事件传输系统,清洗任务在处理非结构化数据会多好使大概30分钟。如果发送的数据是结构化的Avro格式,当被写入HDFS会立即处理完。
跟踪处理的数据要按小时完整的数据会引起问题,例如,当机器挂掉,不能发送文件结束的标记。如果有一个缺失的文件结束标记,其他任务需要等到人为的处理才会继续工作。当机器的数量增长时,这个问题变得更明显。
下一步要做的
在Spotify公司,传输的事件数据在不断的增长。同时系统的负载也在不断的增加,开始经历机器掉电,掉电掉数目开始警告大家,并且意识到系统在负载不断增加的情况下不能维持太久,见图2。
(点击放大图像)
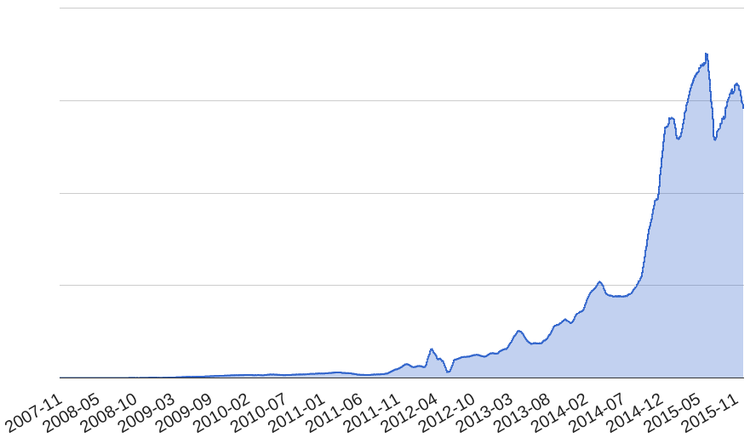
图2
不幸的是,当前线上的事件传输系统已不能再通过迭代开发的方式得到提高了。留在前面唯一能解决问题的方法是重写事件传输系统。