 3G Eden
3G Eden RSS
RSSGFS:一种根本的设计思想转变,还是一个古怪的例子?
正如大多读者所了解的那样,我认为企业现有的存储模型有很严重的弊端。当看到了跟现有存储模型不一样的模型之时,我就很想了解的更多。特别的,我会评估这些创新模型的市场前景。所以,遇到类似于GFS或者压缩备份的好的技术,我就会去考虑客户是否会以及以何种方式去购买它。
本文将会通过评估GFS商业可行性的方式来笼统的描述它,如果你需要关于GFS的技术文章,我只能推荐Ghemawat、Gobioff 和 Leung 合著的《The Google File System》。本文内容也很多取自于那篇论文的描述。至于维基百科的文章,则并没有很好的介绍GFS。
从太空看谷歌
GFS是实现有史以来最强大通用机群的关键技术之一。当大多数IT人为了备份有几千个用户的邮件服务器而损失睡眠时间的时候,谷歌的基础平台却既可以支持大规模用户群,又可以定期推出计算和数据密集型应用,这让竞争对手非常恐惧。谷歌员工是怎么做到的呢?
这一方面可能是因为谷歌员工比你聪明,谷歌招募了数以百计的计算机科学博士生以及更多的聪明人。一方面是由于他们的经历:穷博士根本负担不起用高性能硬件来运行他们的实验技术,所以他们一开始就成本很低而且越来越低。最后,聪明又贫穷的他们反思了整个IT平台搭建规范。
他们卓越的洞察力(insight):与其将平台可用性建立在昂贵的高性能机器上,不如使用廉价的机器,而将平台可用性建立在这些廉价机器组成的系统上面。这完全改变了IT产业的经济学,正如上个世纪70年代的小型机以及上个世纪80年代的个人电脑以及90年代的局域网那样。当处理器、带宽以及存储都很廉价的时候,你就可以花费很多资源来实现IBM所提倡的自动计算。精心设计而且代价低廉的系统,其性能以及经济性都可以获得扩展。
所有这一切都表明,谷歌并没有用他们的平台来完成其他人都没有做过的任务。谷歌只是将很多技术拼接在一起并且将其扩展到一个前所未有的高度。
提醒首席信息官:您公司的用户们用不了多久就会发现谷歌可以做到,而您的公司不可以。您的日子将不会很轻松的。
从地球轨道上看GFS
尽管GFS被称为谷歌文件系统(不要和Sistina的GFS混淆(尽管怎么混淆我不知道)- 或许我们应该称之为GoogleFS),可是它可不仅仅是一个文件系统而已。它还包含数据冗余、支持低成本的数据快照,除了提供常规的创建、删除、打开、关闭、读、写文件操作,GFS还提供附加记录的操作。
那个附加记录的操作折射出谷歌工作任务独特的一面:通过数以百计的网页爬虫,谷歌的数据通过大规模序列写操作的方式得以持续更新。跟通过同步和协调来修改现有数据的方式相比,只将新数据附加在现有数据后面要方便的多。
谷歌工作任务另一个独特的方面是它经常包含两种读操作:大规模流读取和小规模随机读取。因为大规模读写操作非常常见,GFS注重对持续的高带宽而不是低延迟或者每秒输入输出量做出优化。因为许多文件大小达到几个GB,GFS针对数百万的文件处理进行优化,这也就是说一个单独的文件系统应当能够处理几个PB的数据。
而所有的这些都是建立在廉价的组件上面,考虑到机群的规模,可以理解故障是经常发生的。系统检测其本身,发现、承受并从组件错误中恢复过来,错误包括磁盘错误、网络错误以及服务器错误。
从SR-71黑鸟战机看GFS
GFS机群包含了一个master和许多chunkserver,并且会被许多客户访问。每个部件一般都是非常便宜的运行linux系统的机器(最新的一般具备2GHZ xeons处理器、2GB内存以及800GB左右的磁盘)。
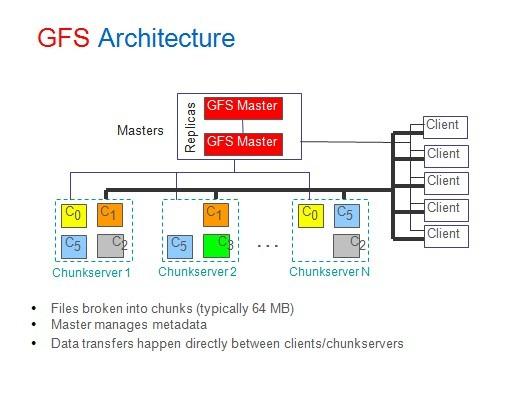
文件被分割成了许多chunk,每一个chunk被一个64位的handle唯一标识,chunk被当做普通的文件存储在linux系统中。每个chunk至少会在另一个chunkserver上有备份,而默认会为每个chunk做三个备份。Chunk跟它们组成的文件一样,非常的大,标准大小是64MB。Chunkserver一般不会缓存数据,因为chunk都是存储在本地,故而linux已经将经常被访问的数据缓存在内存中了。
或许跟我一样,当你看到单一master之后会认为存在瓶颈或者单点故障,那么你需要像我一样多了解一下背后的架构。Master仅仅通过几个字节的信息来告诉客户端哪个chunkserver具有它所需要的chunk。现在可以直观的知道chunk size很大的一个好处:客户端不必跟master有很多交互就可以哦获得大量数据。
这解决了性能瓶颈问题,但是当master会不会成为单点故障呢?我们知道普通数据是被拷贝三次(因为磁盘很便宜,所以可以这样做),但是那些至关重要的存储包括chunk位置在内的元数据呢。
Master处于性能考虑在内存中主要存储了三种元数据:
- 文件和chunk的名称(也即是程序员术语中的命名空间)
- 文件和chunk之间的映射关系,比如说每个文件是由哪些chunk共同组成
- 每个chunk备份的位置
那么,如果master宕机了,其存储的数据必须很快被替代。前两种元数据——命名空间和映射——通过在master机器磁盘中存储日志以及在其他机器上备份的方式被确保安全。日志文件会被经常检查更新以便在需要新master的时候快速恢复数据。多快呢?由于shadow master(在后台跟master保持同步)的存在,读取操作几乎可以立刻执行。写操作会被暂停30秒到60秒以便新的master和chunkserver之间同步数据。许多廉价磁盘冗余阵列的恢复不会比这个速度更快。
最后一种元数据,chunk备份的位置,是在各个chunkserver上面存储的(且在临近的机器上有备份),当master重启或者一个新的chunkserver加入机群的时候会将这个元数据告知 master。由于是master控制chunk的放置位置的,所以它也可以在行chunk创建的时候自行更新自己的元数据。
Master也通过和chunkserver“握手“的方式来追踪机群机器的健康状况。通过checksum(译者注:一种被用来校验数据完整性的方法)来检测数据损坏。即便如此,数据还是可能会被混杂。于是,GFS依靠附加新数据的方式而不是重写现有数据的方式来完成写操作。再通过经常性的检查更新、快照、以及备份,使得数据损失的概率非常的低,而且即便数据损失了也只是导致数据不可访问而不是获得损坏的数据。
GFS 廉价磁盘冗余阵列(RAID)
谷歌员工并没有这样去称呼它,但是本网站非常关心存储,而且我发现这一部分特别的有趣。GFS并没有使用任何的RAID控制、光纤通道、iSCSI、HBAs、 FC 或者SCSI磁盘、双端口或者其它在wide-awake数据中心常见的昂贵设备。然而,它却可以工作并且工作的还很好。
拿创建备份(你我称之为镜像)做个例子。机群中的所有机器通过全通以太网光纤管道连接,可以并行传输数据。这意味着只要新的chunk数据传输到chunkserver,chunkserver就可以立刻以全部网路带宽(大约12MB/秒)开始传输数据到备份chunk,而不用降低接收数据速率。而第一个备份所在的chunkserver一旦接收到数据也重复这个操作,所以两个备份chunk可以与第一个chunk同时完成数据传输。
除了可以快速创建备份,master的备份防止规则还会降备份放置在不同的机器以及不同的机架上面,以便降低因为电源或者网络转换损失导致的数据不可用的概率。
池和均衡
也许虚拟化存储正处在该技术运用的hype cycle(炒作周期)下降阶段,而通过GFS你可以看到当虚拟化被建立在文件系统中的时候是有多么的简单。与其采用一个复杂的软件层来在RAID阵列之间管理数据块,GFS的master将新chunk备份放置在磁盘利用率低于平均水平的磁盘中。所以在没有使用任何棘手而昂贵的软件的情况下,经过一段时间,各个chunkserver的磁盘利用率也会相差无几。
Master也会周期性的对chunk备份位置做再均衡处理,主要考虑的因素是磁盘的空间利用率以及负载均衡。这个过程也避免了新加入机群的chunkserver在加入的一刻被大量数据搞崩溃。Master会逐渐向这个行chunkserver中添加数据。Master也会将chunk从高磁盘利用率的chunkserver上面转移到其他chunkserver上面。
释放存储空间的过程会很慢。Master会让旧的chunk继续存在几天然后批量释放空间,而不是立即删除释放空间。释放操作会在master不忙的时候在后台执行,这也减少了对机群的影响。此外,因为被删除的chunk一开始仅仅是被重命名了,故而系统也提供了针对意外数据丢失的一层保障。
我们知道这一定是在现实世界中可行的,毕竟我们天天都会使用谷歌。但是它工作效果有多好?在论文中作者提供了基于一些谷歌GFS机群实验而来的统计结果。
Ghemawat、Gobioff 和 Leung 合著的《The Google File System》包含了一些有意思的性能信息。这些例子不能被当做是有代表性的,毕竟我们并没有充分了解谷歌使用的GFS机群规模,所以他们得到的结论只能被认为是初步结论。
我们来看下面描述的两个GFS机群:
| Cluster | A | B |
| Chunkservers | 342 | 227 |
| Available Disk Cap. | 72 TB | 180 TB |
| Used Disk Cap | 55 TB | 155 TB |
| Number of Files | 735 k | 737 k |
| Number of Dead Files | 22 k | 232 k |
| Number of Chunks | 992 k | 1550 k |
| Metadata at Chunkservers | 13 GB | 21 GB |
| Metadata at Master | 48 MB | 60 MB |
我们有了两个规模相当的存储系统,其中一个可用空间利用率大约为80%,另一个空间利用率接近90%。这对任何数据存储中心管理员来说都是一个可观的规模。我们也注意到chunk元数据的规模跟chunk的数目成线性关系。很好。机群A中的平均文件大小大约相当于B机群的1/3,。A机群的平均文件大小大约为75MB,而B机群的平均文件大小约为210MB。这远大于一般的数据中心的平均文件大小。
接下来我们来看这两个机群的性能数据:
| Cluster | A | B |
| Read Rate – last minute | 583 MB/s | 380 MB/s |
| Read Rate – last hour | 562 MB/s | 384 MB/s |
| Read Rate – since restart | 589 MB/s | 49 MB/s |
| Write Rate – last minute | 1 MB/s | 101 MB/s |
| Write Rate – last hour | 2 MB/s | 117 MB/s |
| Write Rate – since restart | 25 MB/s | 13 MB/s |
| Master Ops – last minute | 325 Op/s | 533 Op/s |
| Master Ops – last hour | 381 Op/s | 518 Op/s |
| Master Ops – since restart | 202 Op/s | 347 Op/s |
正如作者所说的那样,系统的序列读取操作性能是很卓越的,序列写操作性能是很棒的,而小规模写操作性能是一般的。通过观察A机群的性能数据,我推断最后一分钟它处理了125个小文件的写操作,这些文件平均大小为8KB。显然,这对于具有500个电话坐席的oracle客服中心来讲,全力埋头工作是不够的,这也不是所要设计的核心。对我而言,这样的性能可以轻而易举的超过EMC Centera或者用来处理大文件的新NetApp FAS6000系列。这对于一个三年前设计的由商业机器搭建起来的文件系统已经不错了。
我们这里看到的GFS实现具有许多有助于获胜的性质。
这些品质包括了:
- 可用性。冗余三份(用户可以选择更多)、chunk并行备份、master快速的故障转移、智能的备份放置措施、自动再备份以及低代价的快照拷贝。所有这些传递的特征,正如谷歌用户每天看到的那样:世界最大的数据中心之一提供的数据中心级别的可用性。
- 性能。大部分的工作量,即使是在数据库中,大约90%是读取任务。GFS在大规模序列读取操作上的性能堪称模仿。对于谷歌而言,将视频下载添加到他们的产品集中简直是小儿科,我怀疑他们的每字节花费的代价要比Youtube以及其他所有的视频分享服务低。
- 管理。系统提供了许多 “自动“管理。它通过多种失败模型来管理自己、提供自动的负载均衡以及存储池、也提供了许多特征,包括快照以及提供了对抗故障和错误功能的在系统中保留三天已删除文件的性质。我很乐意知道需要多少系统管理员来维护这个系统。
- 代价。没有比用ATA存储盒更便宜的存储了。
然而,作为一个一般意义上的商业产品,他也有一些严重的短处。
- 附加记录操作和“宽松“的一致性模型,即便对于谷歌来说非常好,并不一定适用于很多的企业工作任务。可能不适用于邮件系统,在那里SOX要求正推动保留,可能被重新设计,以消除删除。而附加操作在GFS多客户端同时写文件的时候发挥了关键作用,这也就是说在企业中GFS可能会丧失它的大部分优势,甚至于大规模序列读取操作的性能。
- 别忘了,GFS是NFS(not for sale),不是为了销售的。谷歌一定将它的平台技术视为核心竞争力,所以近期内它几乎不可能会开放源代码。
综合来看,及时假定GFS会被出售,这也是一个小众的产品,并不会在公开的市场上非常成功。
然而从可实现的能力上去评价这个模型,则是无价的。整个产业界在过去20年一直致力于通过搭建越来越昂贵的“防弹“设施来为受到越来越多挑战的基于块和卷的存储模型增加可用性和可扩展性。
GFS打破了那个模型,并且向我们展示,当反思整个存储模型时我们可以做什么。围绕设备去建立可用性,而不是在设备本身上,这将存储平台当做一个系统而不是一系列部件的集合,将文件系统功能扩展到了很多我们现在考虑的存储管理,包括虚拟化、持续的数据保护、负载均衡以及容量管理。
GFS不是未来。但是它给我们提供了未来的一种可能。