Linux 主导着大多数互联网、大部分云计算和几乎所有的超级计算机。我也喜欢在 Linux 上进行游戏、办公工作和发挥创造力。
当你习惯于一个操作系统时,很容易将其他操作系统看作是“应用程序”。如果你在桌面上使用一种操作系统,你可能会认为另一种操作系统是人们用来运行服务器的应用程序,而又一种操作系统是用来玩游戏的应用程序,依此类推。有时我们会忘记操作系统是计算机管理无数任务的部分(从技术上讲,每秒数百万个任务),它们通常设计成能够执行各种任务。当有人问我 Linux 能做什么 时,我通常会问他们想让它做什么。这没有一个单一的答案,所以这里有五个让我惊讶的 Linux 用途。
由 MSRaynsford 制作的蓝图
在离我最近的创客空间里,有一台巨大的工业机器,大约和一张沙发一样大小,可以根据一个简单的线条图设计文件来切割各种材料。这是一台强大的激光切割机,令我惊讶的是,我第一次使用它时发现它只需要通过 USB 线连接到我的 Linux 笔记本电脑上。事实上,在许多方面,与许多台式打印机相比,连接这台激光切割机更容易,因为许多台式打印机需要过于复杂和臃肿的驱动程序。
使用 Inkscape 和 一个简单的插件,你可以为这台工业激光切割机设计切割线条。你可以为你的树莓派笔记本设计一个外壳,使用这些知识共享的设计方案来建造 一个密码锁盒、切割一个店面标牌,或者你心目中的其他任何想法。而且,你可以完全使用开源软件来完成这些操作。
Lutris 桌面客户端
开源游戏一直都有,最近一段时间也有一些备受瞩目的 Linux 游戏。我建造的第一台游戏电脑就是一台 Linux 电脑,我觉得我邀请过来一起玩沙发合作游戏的人们都没有意识到他们是在 Linux 上进行游戏。这是一种流畅顺滑的体验,而且取决于你愿意在硬件上花费多少,可能上无止境吧。
更重要的是,不仅游戏正在进入 Linux,整个平台也在进一步发展。Valve 推出的 Steam Deck 是一款非常受欢迎的掌上游戏机,它运行的是 Linux。更好的是,许多开源软件也在 Steam 上发布,包括 Blender 和 Krita,这鼓励了更广泛的采用。
Calligra Words
Linux,就像生活一样,并不总是刺激的。有时,你需要一台计算机来完成一些普通的事情,比如支付账单、制定预算,或者为学校写论文或工作写报告。无论任务是什么,Linux 都可以作为一台日常的桌面电脑。你可以在 Linux 上进行“平常”的工作。
不仅局限于知名的应用程序。我在优秀的 LibreOffice 套件中做了很多工作,但在我最旧的电脑上,我使用更简洁的 Abiword。有时,我喜欢试试 KDE 的官方套件 Calligra,当需要进行精确的 设计工作(包括 专门的过程式设计工作)时,我使用 Scribus。
使用 Linux 进行日常任务最好的地方在于,最终没有人知道你用了什么工具来完成最终产品。你的工具链和工作流程属于你自己,结果和封闭的、非开源软件产生的结果一样好,甚至更好。我发现,使用 Linux 进行日常任务让这些任务对我来说更有趣,因为开源软件本质上允许我开发达到自己预期结果的路径。我可以尝试创建解决方案,帮助我 高效完成工作,或者帮助我 自动化重要任务,但我也享受系统的灵活性。我不想去适应我的工具链,而是调整我的工具,使它们为我工作。
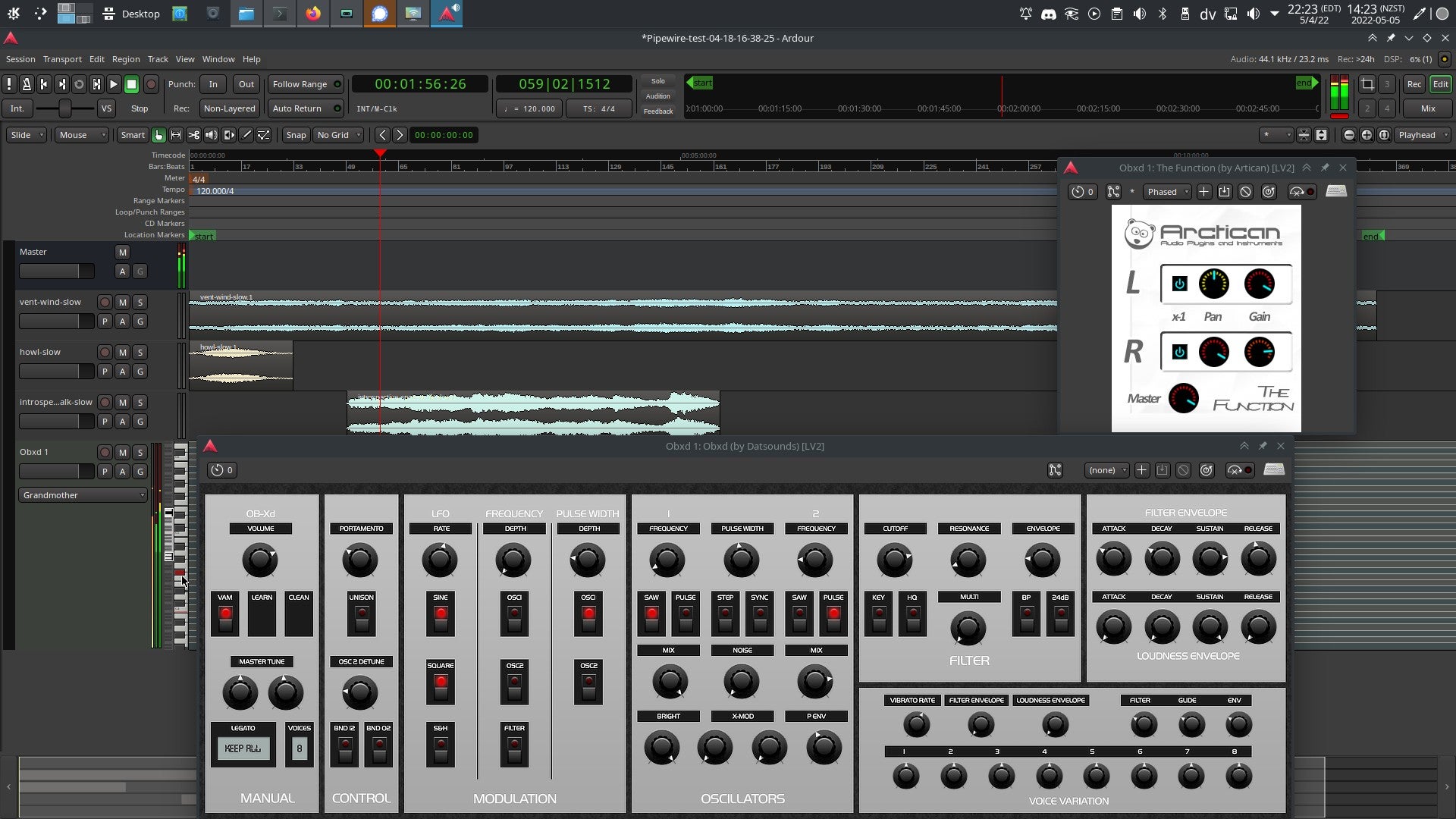
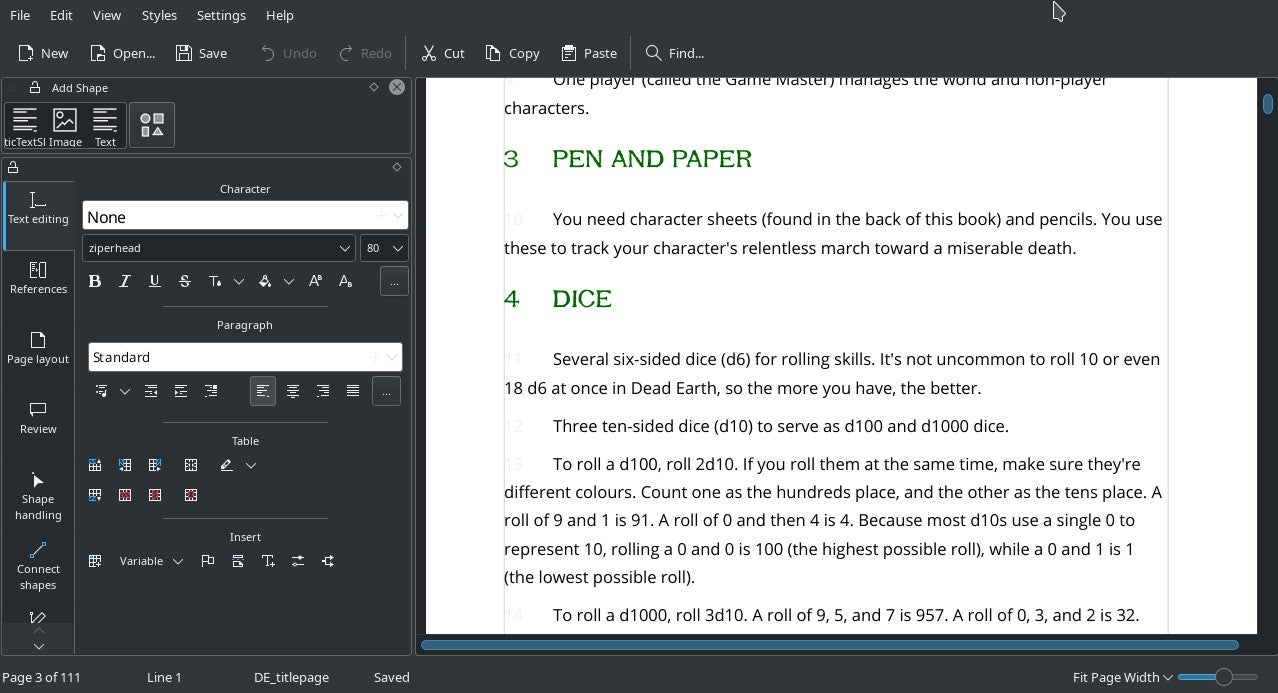
Ardour
我是一个业余音乐家,在开始将所有制作工作转移到计算机之前,我拥有几台合成器、音序器和多轨录音机。我转向计算机音乐之所以用了比较长的时间,是因为我觉得它对我来说不够模块化。当你习惯于将物理设备互相连接,通过滤波器、效果器、混音器和辅助混音器来路由声音时,全功能应用程序看起来有点令人失望。
并不是说全功能应用程序没有受到欣赏。我喜欢能够打开一个应用程序,如 LMMS,它恰好拥有我想要的一切。然而,在实际使用中,似乎没有一个计算机音乐应用程序真正拥有我所需要的一切。
当我转向 Linux 时,我发现它以模块化为基本原则构建了一个庞大的音乐制作环境。我找到了 音序器、合成器、混音器、录音器、补丁台等的应用程序。我可以在计算机上建立自己的工作室,就像我在现实生活中建立自己的工作室一样。在 Linux 上,音频制作得到了飞速发展,今天,开源 应用程序 可以作为统一的控制中心,同时保留了从系统其他位置提取声音的可扩展性。对于像我这样的拼贴式制作人来说,这是一个梦幻般的工作室。
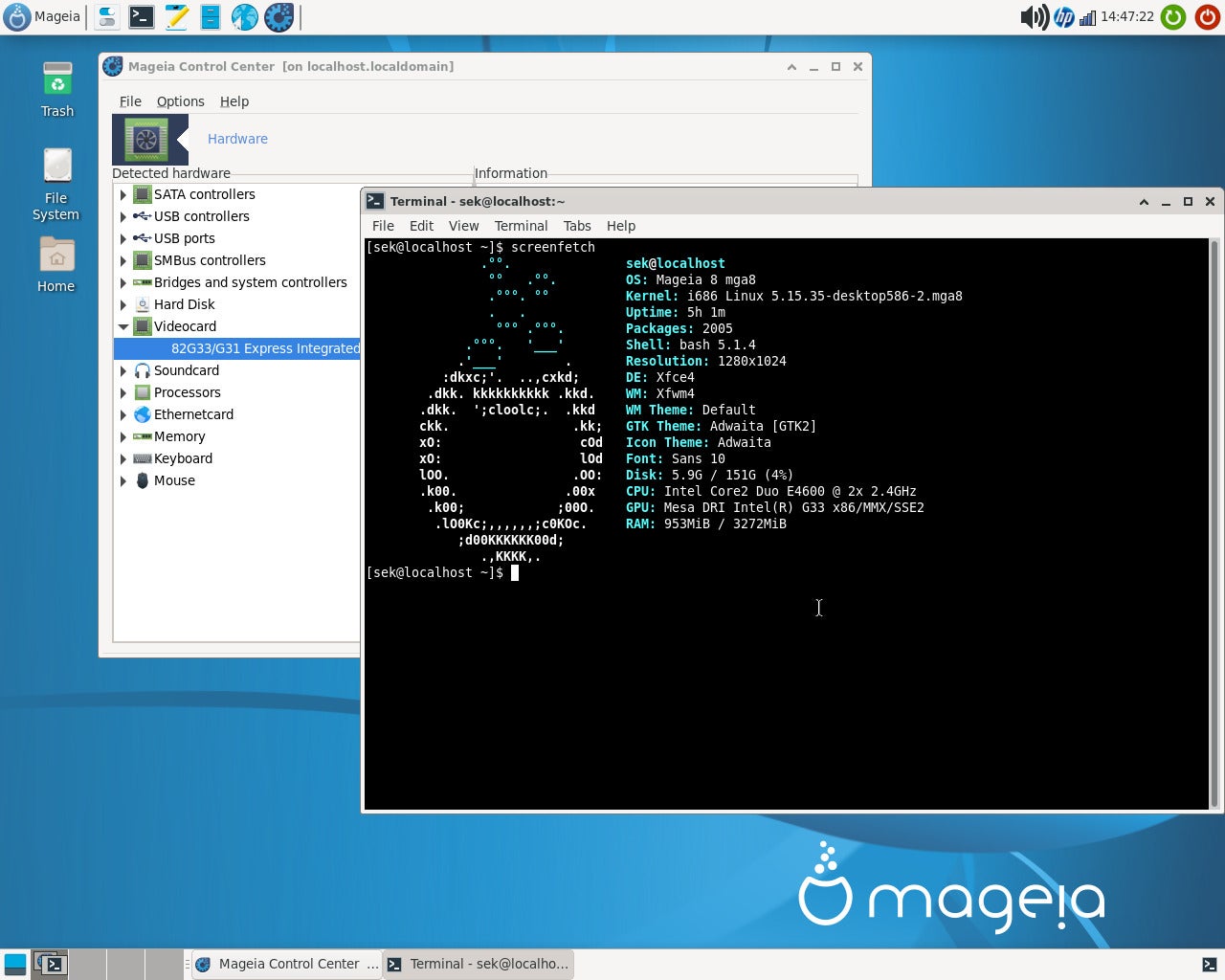
Mageia 8
我不喜欢扔掉旧电脑,因为很少有旧电脑是真正报废的。通常,旧电脑只是被世界其他部分“超越”了。操作系统变得过于臃肿,旧电脑无法处理,因此你不再能获得操作系统和安全更新,应用程序开始要求你的旧电脑没有的资源,等等。
我倾向于 收留旧电脑,将它们用作实验室机器或家庭服务器。最近,我发现在旧电脑上添加一块固态硬盘作为根分区,并使用 XFCE 或类似的轻量级桌面环境,使得即使是十年前的电脑,也可以愉快地用于期望的工作。平面设计、网页设计、编程、定格动画等任务在低配置机器上都是小菜一碟,更不用说简单的办公工作了。有了 Linux 驱动的机器,真不知道为什么企业还要升级。
每个人都有自己喜欢的“救援”发行版。我个人喜欢 Slackware 和 Mageia,它们都还发布了 32 位的安装镜像。Mageia 也是基于 RPM 的,所以你可以使用像 dnf 和 rpmbuild 这样的现代打包工具。
好吧,我承认在服务器上使用 Linux 并不令人惊讶。实际上,对于那些了解 Linux 但自己不使用 Linux 的人来说,当提到 “Linux” 时,数据中心通常是他们首先想到的。然而,这种假设的问题在于它似乎明显地认为 Linux 在服务器上应该表现出色,好像 Linux 根本不需要努力一样。这是一种令人赞赏的情绪,但实际上,Linux 在服务器上表现出色是因为全球开发团队付出了巨大努力,让 Linux 在其所从事的工作上特别有效。
Linux 之所以成为强大的操作系统,主要是因为它驱动着大部分互联网、主导着大部分云计算、几乎所有现有的超级计算机以及更多应用领域。Linux 并非止步不前,尽管它有着丰富的历史,但它并没有深陷传统而无法进步。新技术正在不断发展,Linux 也是这一进步的一部分。现代 Linux 适应了不断变化的世界对增长需求的要求,使得系统管理员能够为全世界的人们提供网络服务。
这并不是 Linux 的全部能力,但也绝非小小的成就。
我还记得第一次遇到一个从小就使用 Linux 的人的事情。在我使用 Linux 的大部分时间里,这种情况似乎很少发生,但最近这种情况相对较为普遍。我记得最令人惊讶的一次是遇到一个年轻的女士,带着幼儿,看到我当时穿着的那件极客风格的 T 恤衫,她随意地提到她也使用 Linux,因为她从小就接触它。这实际上让我有点嫉妒,但随后我想起,在我成长的过程中,桌面电脑上根本没有 Unix 的 存在。然而,想到 Linux 在过去几十年里的轻松发展,确实令人愉快。成为其中的一员更是乐趣无穷。
(题图:MJ/e529833a-8ec1-4fff-997b-2ef3f107bc68)
via: https://opensource.com/article/22/5/surprising-things-i-do-linux
作者:Seth Kenlon 选题:lkxed 译者:ChatGPT 校对:wxy
本文由 LCTT 原创编译,Linux中国 荣誉推出
转自 观点|5 个令人惊讶的 Linux 用途
 Linuxeden开源社区
Linuxeden开源社区