 Linuxeden开源社区
Linuxeden开源社区作者
网上商场大促时,快速发现问题并精准定位根因所在是保障活动顺利进行的关键任务。HIRO 调用链监控系统在 818 苏宁发烧节期间为商城系统保驾护航,抗住了压力,这其中的设计经验值得借鉴。
当顾客在苏宁易购下单出现异常时,问题究竟出在会员系统、价格系统、库存系统、支付系统……?技术人员面对复杂的系统构成与系统交互,如果在缺乏有效的监控机制情况下,想准确高效的定位问题是很困难的。
我们可以想象到一般大促保障的场景:系统负责人和技术人员在现场通过拉取业务 / 系统日志进行问题排查,耗费大量工时后才发现根因,仅仅是一条 SQL 语句迟迟没有返回导致。
但究竟是什么原因导致的呢?是网络问题、数据库服务端问题、还是客户端问题?……由于大促保障需要的是 时效性,如何能够 快速发现问题并精准定位根因所在 成为关键,因此苏宁云迹调用链监控系统(以下简称 HIRO)应运而生。
调用链监控系统
简介
把用户发起的每次请求生成一个全局 ID(以下统称为 TraceId),通过它们将不同系统采集的日志按照时序和调用逻辑串起来,组成一条条链路,这就是 调用链。调用链监控系统就是用这种技术来理解系统行为用于分析性能问题的一种工具。
作用
调用链监控系统是基于网络调用日志的分布式跟踪系统,它可以分析网络请求在各个分布式系统之间的调用情况,从而得到处理请求的调用链上的入口 URL、应用、服务的调用关系,从而找到请求处理瓶颈,定位错误异常的根源位置。
同时,业务方也可以在调用链上添加自己的业务埋点日志,使各个系统的网络调用与实际业务内容得到关联。
在实际应用中,每一个请求过来后,会经过多个业务系统并留下足迹,并产生对各种 Cache 或 DB 的访问,但是这些分散的数据对于问题排查,或是流程优化都帮助有限。
对于这么一个跨进程 / 跨线程的场景,汇总收集 并 分析海量日志 就显得尤为重要。具体要求能够做到:
- 追踪每个请求的完整调用链路
- 收集调用链路上每个服务的性能数据
- 计算性能数据和比对性能指标(SLA)
- 在出现故障后能精确的给出有问题的链路详情并且精确报警甚至给出解决此故障的一般性方法。
使用场景
- 应用运行时突然发现执行某一个服务耗时很长,此时希望能够有一种方式定位运行时代码各个部分的耗时,以确定耗时点在什么地方
- 应用运行时一切正常,绝大部分情况下服务运行都非常顺畅,但有用户反馈,当传入 xxx 参数时,服务响应非常缓慢,此时希望能够有一种方式针对特定的方法入参来观察代码执行情况
- 一个业务逻辑比较复杂的程序方法,在运行时无法确定具体调用了哪些逻辑以及调用时序,此时希望能够有一种方式详细地展现出方法执行的具体逻辑、时序等
苏宁 HIRO 实现原理
中间件研发中心从 2015 年开始着手研究调用链的相关技术,截至 2017 年 7 月底 HIRO 已经承载了 530 个系统,其中核心系统超过 60 个。
HIRO 能够分析分布式系统的每一次系统调用、消息发送和数据库访问,从而精准发现系统的瓶颈和隐患。目前每天经过 HIRO 分析的链路总量超过亿条,监控日志峰值达 500 万消息 / 秒。
HIRO 有如下特性:
- 它是基于字节码、日志的分布式跟踪系统
- 侵入性低,安全稳定
- 基于大数据分析
- 安装部署简单,Agent 自动升级
- 每次请求都生成全局唯一的 TraceId,通过 TraceId 将不同系统采集的日志串在一起,组成调用链
- 支持对部分 C/C++ 系统场景的调用穿透
- 支持业界主流的 Java 应用服务器,包括:WildFly、WebSphere Application Server、WebLogic、Tomcat 等
- 支持多种数据库和缓存,包括:MySQL、Oracle、DB2、Redis 等
- 支持消息中间件 Kafka,MQ(JMS Base)
- 支持苏宁内部 RPC 框架(RSF)
架构
HIRO 整体分为四层,从底层到前端分别是:
- 第一层:在各应用服务器上埋点 Agent 并用 Flume 采集所有埋点的日志
- 第二层:用 Spark 对日志进行分析和统计
- 第三层:把计算结果保存在 Elasticsearch 中
- 第四层:前端 Portal 的展示
具体架构如下图所示:
(点击放大图像)
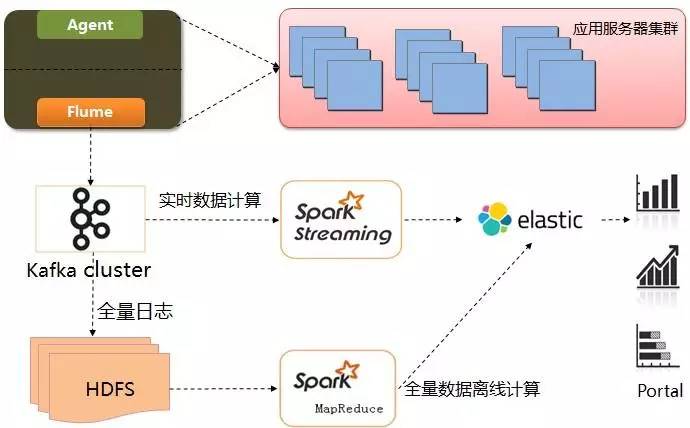
与之相对应的,HIRO 内部共分为三大块,分别是 Agent、Spark 实时计算和 Spark 离线计算。其各部组件如图所示:
(点击放大图像)
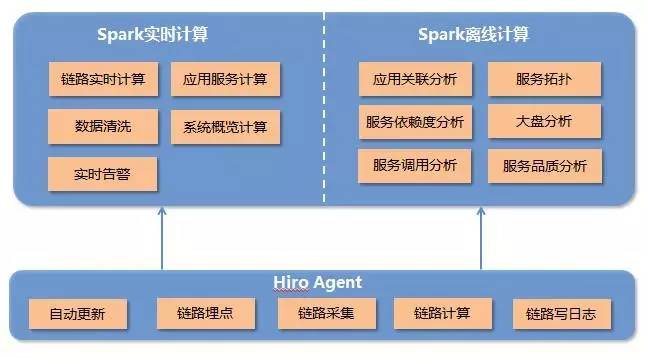
埋点和输出日志
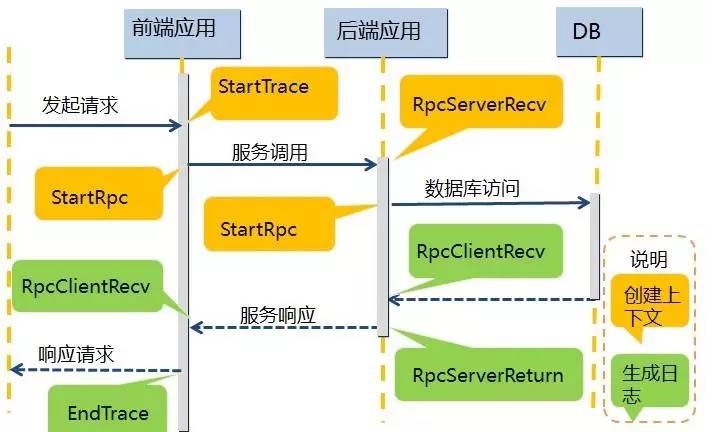
在前端请求到达服务器时,应用容器在执行实际业务处理之前,会先执行埋点逻辑。埋点逻辑为这个前端请求分配一个全局唯一的 TraceId,然后把它放在一个调用上下文对象中,该对象会存储在 ThreadLocal 里面。
调用上下文里还有一个 ID 非常重要,在 HIRO 中被称作 RpcId,它用于区分同一个调用链下的 多个网络调用 的发生顺序和嵌套层次关系。
当执行业务处理时需要发起 RPC 调用时,苏宁 RPC 远程服务框架 (以下简称 RSF) 会首先从当前线程 ThreadLocal 上面获取之前 HIRO 设置的调用上下文。
然后,把 RpcId 递增一个序号。在 HIRO 里使用多级序号来表示 RpcId,比如前端刚接到请求之后的 RpcId 是 0,那么它第一次调用 RPC 服务 A 时,会把 RpcId 改成 0.1。之后,调用上下文会作为附件随这次请求一起发送到远程的 RSF 服务器。
RSF 服务端收到这个请求之后,会从请求附件里取出调用上下文,并放到当前线程 ThreadLocal 上面。
如果服务 A 在处理时,需要调用另一个服务,这个时候它会重复之前提到的操作,唯一的差别就是 RpcId 会先改成 0.1.1 再传过去。
服务 A 的逻辑全部处理完毕之后,RSF 在返回响应对象之前,会把这次调用情况以及 TraceId、RpcId 都打印到它的访问日志之中,同时会从 ThreadLocal 清理掉调用上下文。
下图展示的是埋点和生成日志的时序关系:
(点击放大图像)
下图展示的是多个系统间的调用关系:
(点击放大图像)
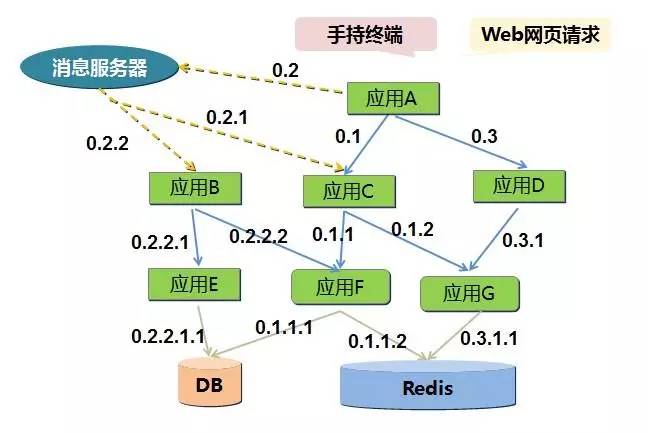
输出日志时面临如下挑战:
- 需要减少对业务线程的影响,降低资源消耗
- QPS 越高日志产生越快,监控数据就越多
对此,HIRO 的解决方案如下:
- 异步线程写日志
- 无锁循环日志,按秒刷新
- 对日志大小做限制,对调用链做采样,不破坏调用链构成
- 日志文件按大小滚动,自动清理
收集和存储日志
调用链的日志分散在调用经过的各个服务器上,离线分析需要将同一条链路上的日志汇总在一起。HIRO 用 Flume 去采集全量的日志,经过 Kafka 集群,最终全量存储在 HDFS 中。
汇总和重组链路
由于实时收集的日志上的链路都是分散的、断断续续的,这时需要通过 SparkStreaming 的计算功能,把相同的 TraceId 的链路分拣出来,组装成一条完整的链路。
下面给出了一个典型的调用链图示(由于链路太过庞大只能截取一小部分):
(点击放大图像)
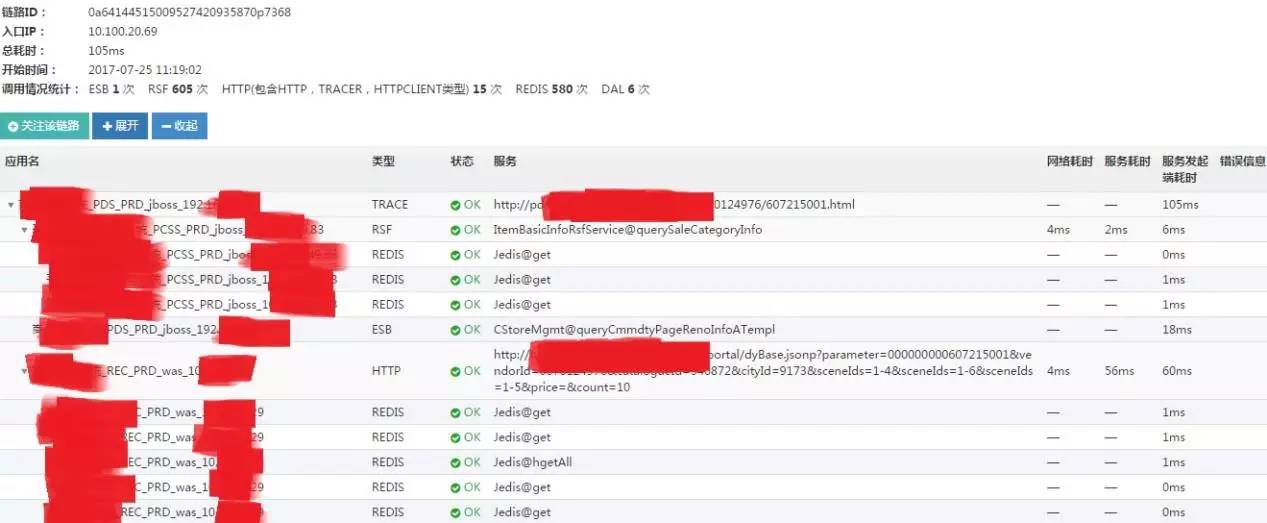
分析和统计调用链
根据重组后链路中的应用、服务以及相互间关系进行数据建模,将分析出来的数据在应用层面和服务层面上统计出错误数、访问量、最大耗时和平均耗时、依赖度等。
同时利用 Elasticsearch 可以对 DB、Redis、RSF、ESB 做大盘分析,还可以统计出各个应用的报表和对比统计。
下图展示了一条链路分析后统计的数据:
(点击放大图像)
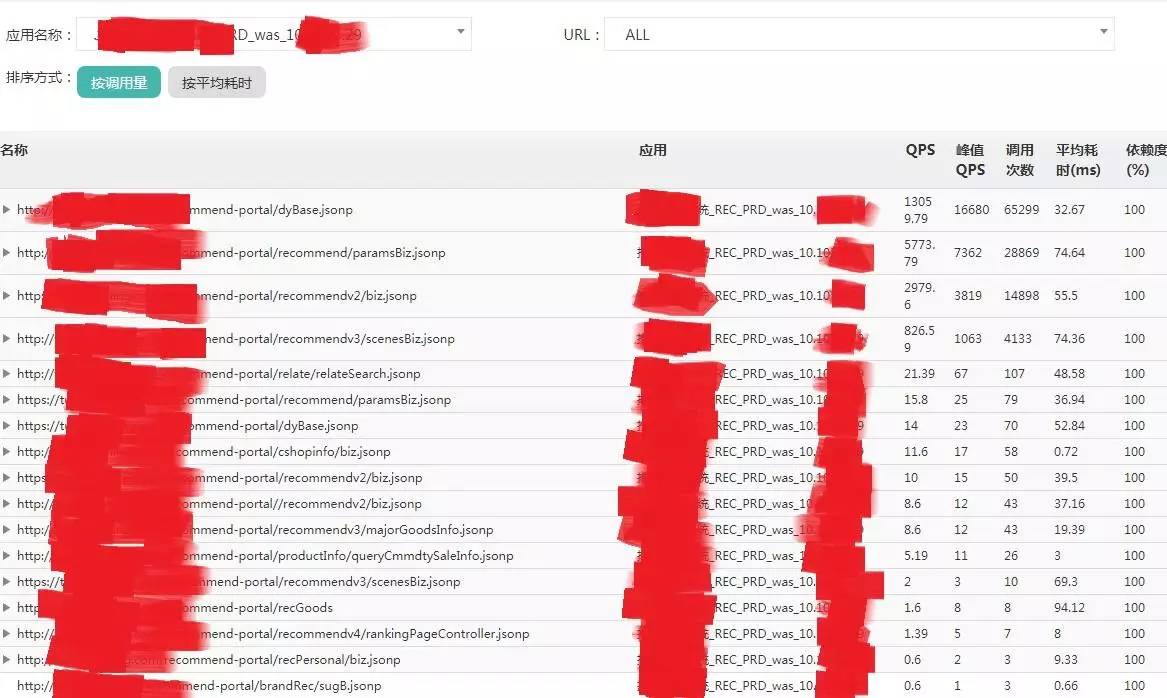
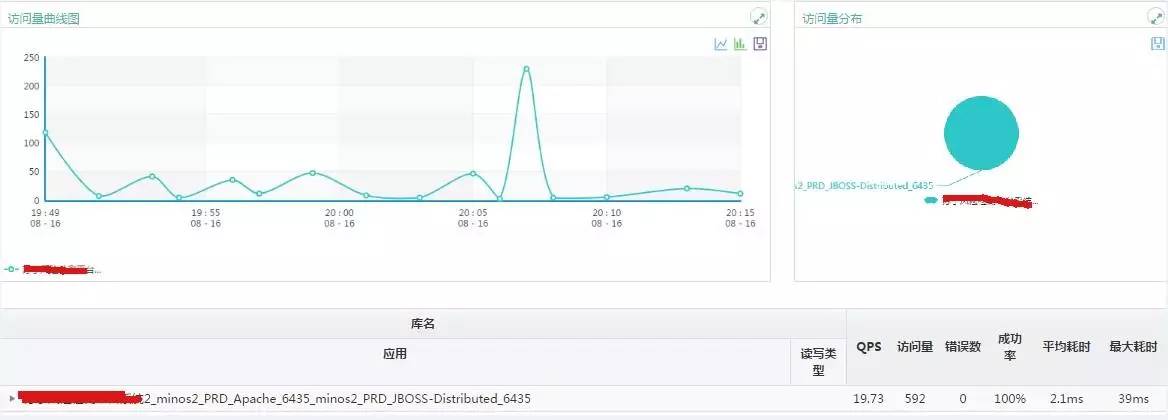
下图展示了 DB 分析的结果:
(点击放大图像)
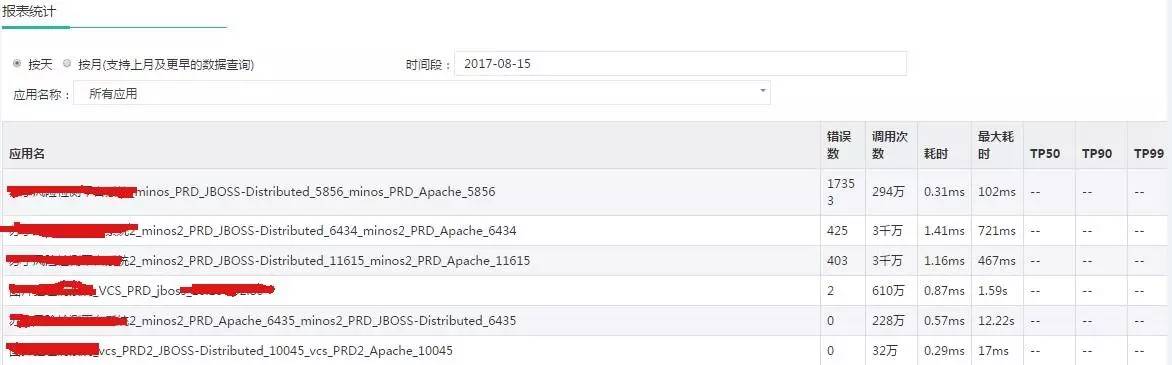
下图展示了应用数据报表统计的结果
(点击放大图像)
HIRO 应用
问题定位
(点击放大图像)
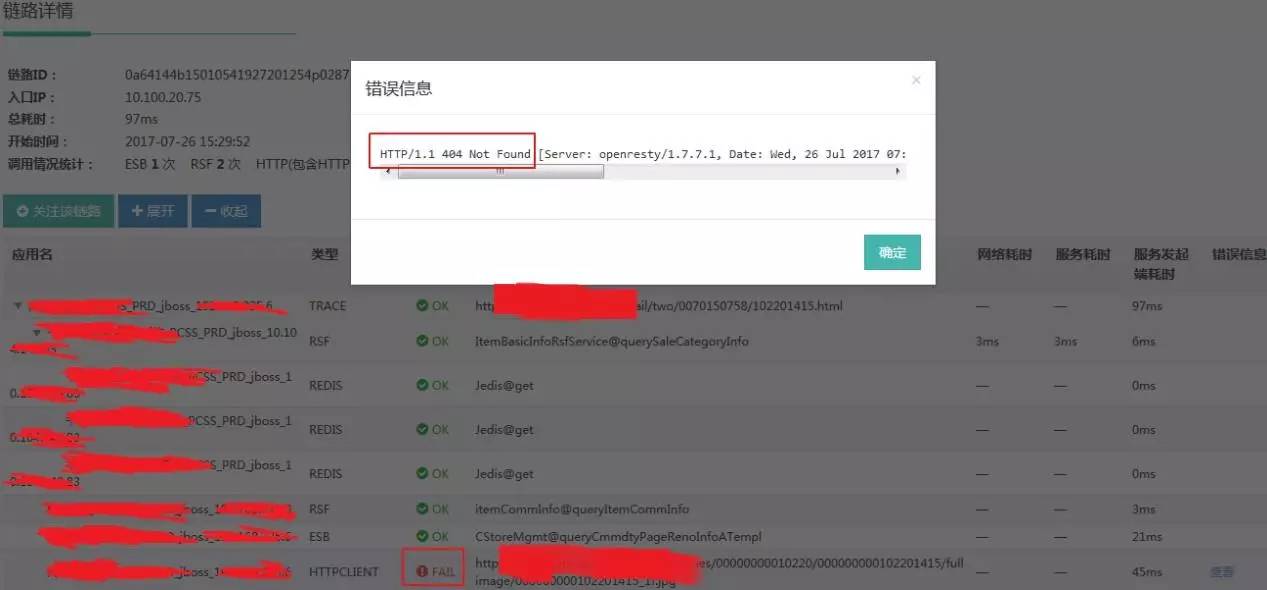
上图是苏宁生产环境的某一条实际链路。用户收到告警:某个应用访问失败。通过 HIRO,可以清晰地看到该应用当前一条链路的详情,这是因为底层的一个 HTTP 请求返回 404 导致访问失败。
系统分析
HIRO 不仅仅是用来做问题定位,还可以防范问题。如下图所示,HIRO 管理员发现易购上的一条交易耗时较长引起警觉,通过 HIRO 的深入排查 没有发现链路上有问题。
(点击放大图像)
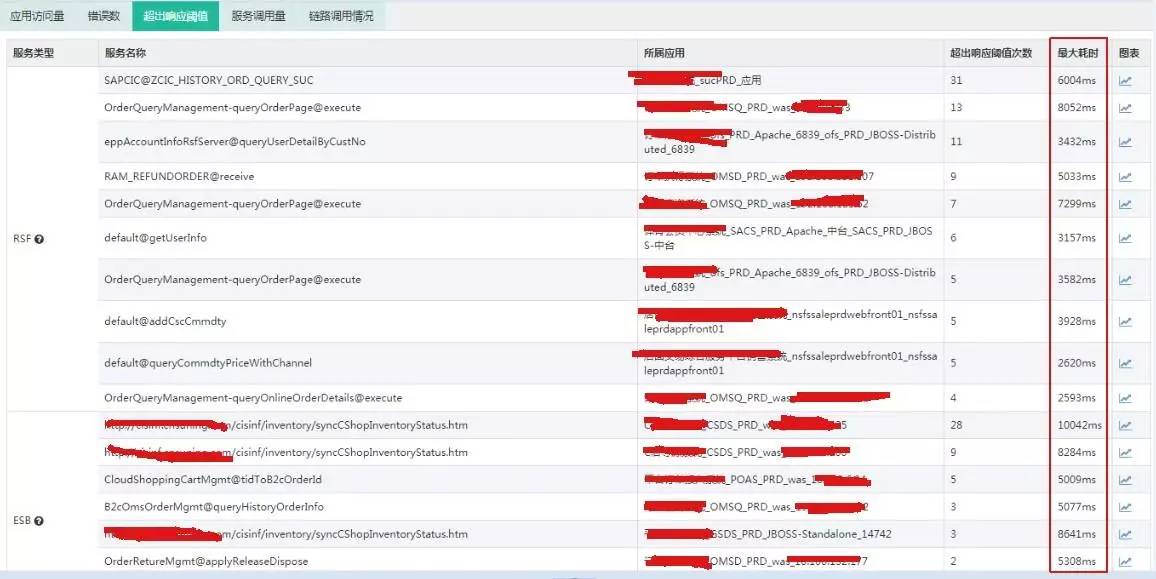
但是谨慎起见把该耗时数据发给业务方,并提出是否由于配置不当或者当前系统压力过大导致耗时过长的疑问,业务方根据此思路排查系统修改了相关参数后,耗时恢复到正常水平,避免了可能发生的系统故障。
调用还原
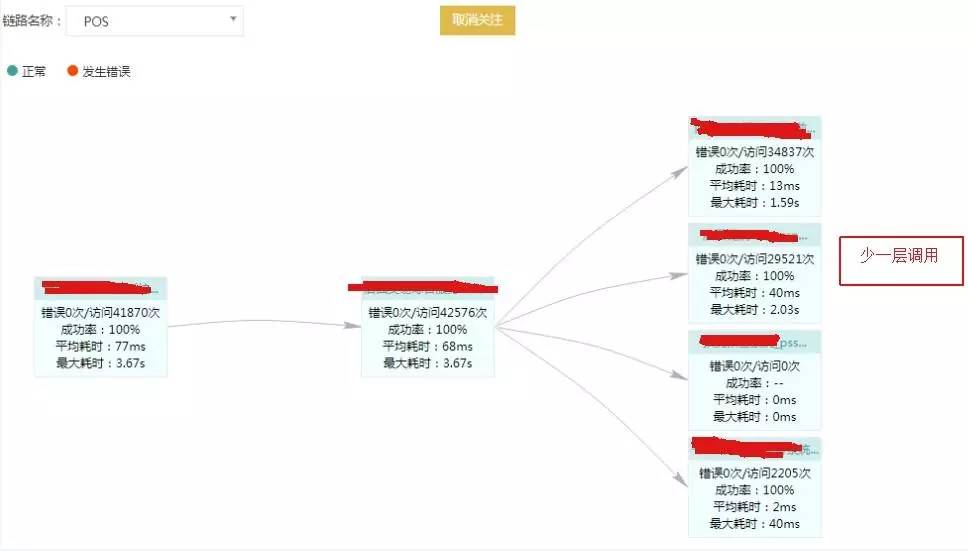
当用户怀疑系统的业务流程有问题或者不是用户预想的调用场景,HIRO 也可以派上用场。如下图所示,前台销售系统数据处理有问题,客户怀疑是否是调用流程出错,用 HIRO 查看拓扑后,发现调用少了一层,很快就定位到是哪段代码的 bug 并及时修复。
(点击放大图像)
品质分析
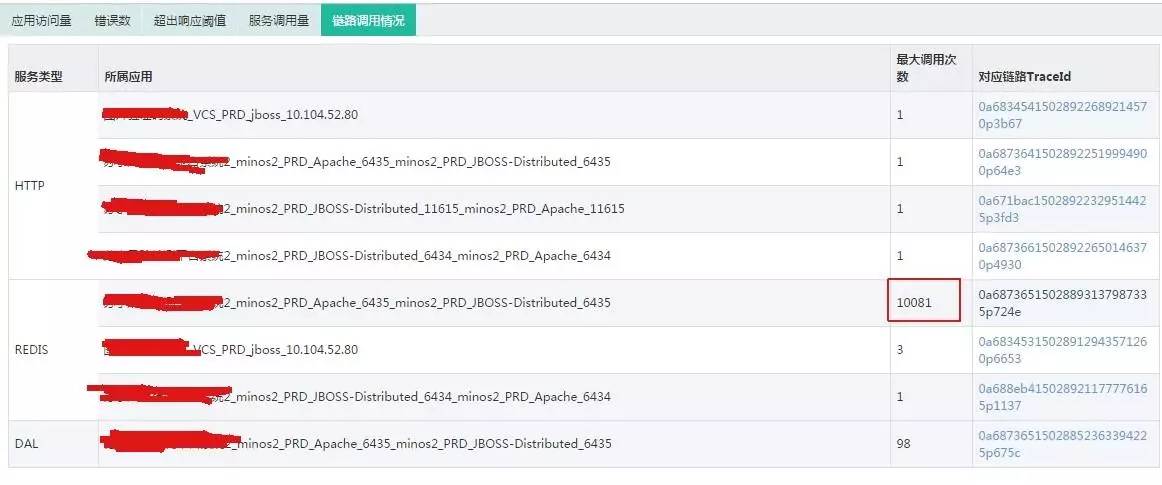
HIRO 可以统计出服务调用的次数,用户能看到应用是否有大量无用调用的情况,从而反向检查代码,提高代码的品质。
如下图所示,Redis 应用性能下降,经过 HIRO 的分析,发现是某个应用短期内频繁访问导致的,经过代码分析,最终找到根本原因:业务逻辑出错了,bug 修复后问题随之解决。
(点击放大图像)
容量评估
如果对同一个前端入口的多条调用链做汇总统计,也就是说,把这个入口 URL 下面的所有调用按照调用链的树形结构全部叠加在一起,就可以得到一个新的树形结构(如下图所示)。这就是入口下面所有依赖的调用路径的情况。
(点击放大图像)
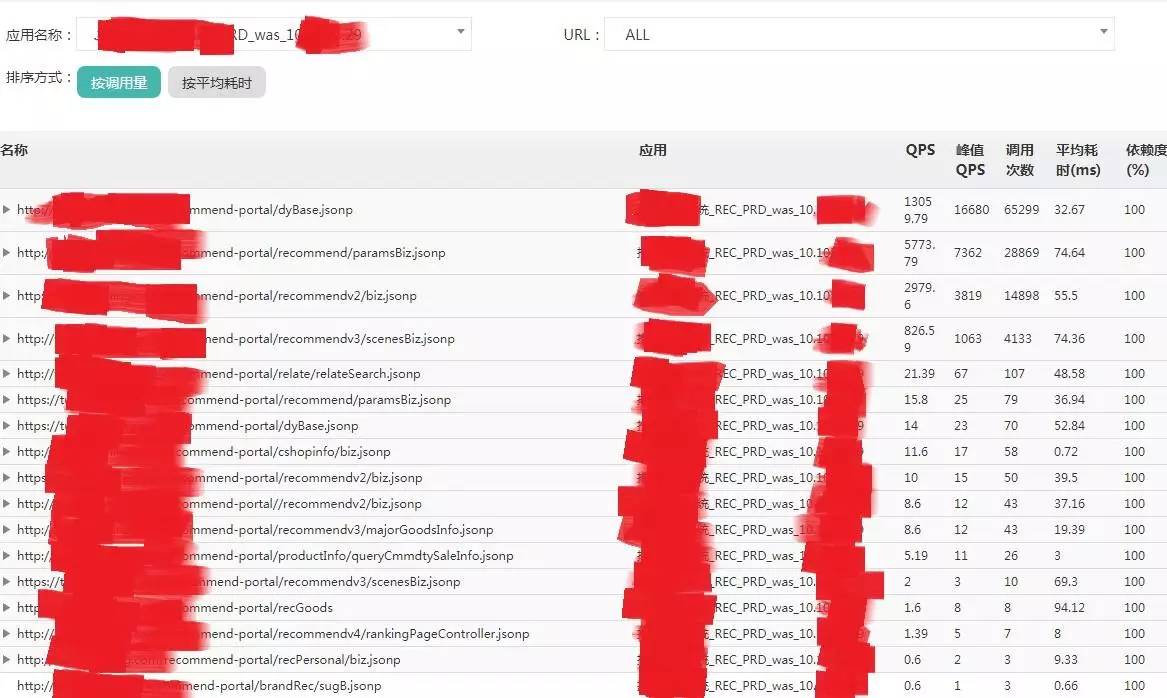
这种分析能力对于复杂的分布式环境调用关系的梳理尤为重要。传统的调用统计日志是按固定时间窗口预先做了统计的日志,上面缺少了链路细节导致没办法对超过两层以上的调用情况进行分析。
例如,后端数据库就无法评估数据库访问是来源于最上层的哪些入口,每个前端系统也无法清楚确定当前入口由于大促活动流量翻倍,会对后端哪些系统造成多大的压力,需要分别准备多少机器。有了 HIRO,这些问题就会迎刃而解。
HIRO 未来规划
HIRO 在苏宁才刚刚起步,但是已经向用户展示了其强大的功能。为了进一步满足用户对 HIRO 的需求,未来 HIRO 将陆续完善和提供如下功能:
- 进一步优化实时数据的处理机制,使得时延更低,达到真正的实时
- 完善实时的错误发现及报警机制,进一步提高发现问题的及时性
- 接入更多的中间件,进一步丰富调用链内容,使调用链更长更完整
- 借助深度学习算法,充分运用数据挖掘技术把 HIRO 产出的数据价值化,力争在更多维度上提供出有价值的分析数据
- 提供各种 API 接口,将 HIRO 数据开放出来,方便用户可以构建自己的调用链系统,从而达到对业务监控的效果
作者介绍
朱健荣,现任职于苏宁云商 IT 总部。主要负责中心产品推广和技术保障工作。在苏宁,经历了多次 818、双 11 等大促保障工作,深知应用系统的稳定对电商平台的重要性。现正在和研发团队一起建设应用系统监控层整体解决方案,已经落地的产品有服务端和调用链监控、智能告警和决策分析平台等。
转自 http://www.infoq.com/cn/articles/suning-call-chain-monitoring-system-escort-818