 Linuxeden开源社区
Linuxeden开源社区作者 ,译者
本文要点
- 当我们的团队规模更大、过程更为繁多并采用了微服务架构时,系统测试的难度增加了。
- 测试的推进过程也截然不同。相比于单元测试环境中,我们缺乏测试特定功能点的手段。
- 我们受困于代价非常大的网络调用。除非将技术栈均质化并从中抽出网络调用,否则我们无法摆脱该问题。
- 处理状态机需要新的工具。
- 我们应该用好这些天生丽质的状态机。
在过去……
生活就是一个不断面对障碍的过程。我们跳过了一个障碍,紧接着就要去面对下一个障碍。IT行业尤为如此,这一行业仅用了二十到三十年时间就步入了成熟。当然在此期间,每个从业人员也都步入了“敏捷”时代。“测试”概念是敏捷的基本组件,是当前处于成熟状态的IT行业中的关键创新之所在。
在我刚开始从事开发时,我经常会为了如何避免在代码中引入缺陷,而呆呆地面对各代码块。害怕引入了软件缺陷,我就会名誉扫地,更不用说在物质上的损失了。另一方面,如果我经过一番努力正确地实现了改进,那么只能说我适合于完成份内的工作。问题在于,要无任何风险地实现改进,开发人员必须对系统中的方方面面了如指掌。在团队工作的情况下,此要求绝对是难以企及的。一种可行的做法是在交付功能中尽可能少地做出更改,即完全避免重构!毕竟,虽然开发人员可能会在重构问题上表现出谢天谢地,但是如果出了任何差错,尽管你会向产品负责人(Product Owner)解释说重构能改进代码的质量,只是对产品交付的底线有负面的影响,这时开发人员就会将像碰上瘟疫一样对你敬而远之。
做一些测试如何?
现在我们添加一些测试
编写测试是为了寻求一种方法去验证我们代码的工作情况。测试为我们提供了很好的框架或方法,允许我们在并不具备完整知识的情况下做出改进。如果在我们之前的开发人员已经将他们的知识适当地抽取到测试中,那么通过运行这些测试就可以确认我们的编码工作并未破坏任何事情。这听上去很好,但是测试的效能远非如此。测试因为其更多的特性而被开发人员赏识。首先,测试可用于教学目的。测试不仅能告诉我们代码是可以工作的,而且给出了如何使用代码的例子!我们现在具有了对代码中的需求文档化的天然之所,这些文档将与代码并存。其次,测试可与代码共存,并可重复使用。我们可以在每次更改后运行测试。我们可以将开发从某一个稳定点处开始,进而引入一些改进,并结束于另一个稳定点处。这并非是一个新理念。在我学习计算机科学时,那些最聪明的学生就很快地学会了一种称为“迭代开发”的开发方法,即从细微之处着手,让事情工作起来,进而迭代地做扩展。永远不要试图一次性地编写完成整个解决方案。现在我们具有测试,并且我们的测试能自动地告知开发已处于一个稳定点处。我们可以称完成了一个“绿色”的构建,这意味着一个代码块版本已经可接受,并被共享,或是部署和使用。
但是运行测试是可选
代码开发的情况相对要好一些。我们可以更改并重构代码,极大地改进代码库的质量。因此我们不可避免地会陷入下一个系列的问题中:尽管我们可以处理开发人员在过去所做出的更改,但是如何对待开发人员当前所做的更改呢?
我们必须作为一个团队开展工作。只要我们在每次更改后就运行测试,并只将好的代码提及给源代码控制系统,那么不会出现任何问题。但是问题在于,开发人员或者是永恒的乐观主义者,或者仅是懒惰。我们可能会认为,这么微小的更改当然不会造成任何破坏,所以让我们直接跳过本机测试,提交到源代码控制系统吧。当然,这种做法不可避免地引入了一些并未构建的更改,进而导致失败的测试。其它开发人员也会看到所做的更改并犯了所有同样的错误。更糟的是,他们是在毫不知情的情况下犯了同样的错误。为此,他们将不得不深挖源代码控制系统,分析测试的失败。每位采用了更新的开发人员不得不做这些工作。因此由我们所引入的软件缺陷会被多次的修正。如果团队就此文件进行一次交流,那么只需要一名开发人员去修正问题,而其它开发人员等待修正后结果即可。
持续集成通过设置系统而改变了这种状况,系统被设置为无论开发人员是否提交代码都自动运行测试。代码将在所有的代码更改后得以验证,并且不再依赖于那些约束开发人员的纪律。具体做法类似于多线程软件开发,我们将一个“编码信号灯”引入到开发方法中,该信号灯将协调多位开发人员对代码的并发更改。当构建给出“绿灯”时,开发人员可以更新代码块。而当构建给出“红灯”时,最后的更改产生了一些破坏,因此最好避免如此。
但事实上信号灯并未起作用。问题在于还存在着第三种状态,即一个构建可以是“当前正在构建”的状态。这是一个灰色地带,开发人员并不了解有事情出错了。禁止将构建提交到红灯状态的最初考虑是降低修复被破坏构建的复杂度,而非意在最大化开发人员的生产力。是否可以做一次更新?如果你愿意去面对任何潜在的问题,那当然可以。是否可以提交代码?当然可以,只要正在进行构建并非处于红灯状态。这些策略是逐渐形成的,是由那些寻求以合作方式开展工作的团队所制定的,而非预先设计好的。
因此,构建所占用的时间越来越长。
破坏规则的魔掌
假定我们当前正在构建一个应用,并承诺遵循降低构建时间这一理念。但是过了六个月后,测试就拖垮了我们。现在构建时间从半个小时变成了一个小时。我们的团队具有十名开发人员,幸运的是我们每天只做一次提交。每个人都开始认识到,他们的大部分时间消耗在诸如将代码加入项目等事情上,而非用于实际的代码开发。在每次构建变成绿灯状态时,就会发生一次竞争!开发人员放任自流并犬牙交错地相互提交。构建会变成红灯状态,这时不会有人想到通过深挖最近五次的提交而发现问题。噢,我说错了,现在已经是六次的提交了,深挖六次提交去发现问题。每个人都认识到这在方法上是存在问题的。Scrum Master不愿认同在红灯状态构建上的提交是不可避免的。他们会停止编码信号灯,选定一位开发人员用一周的时间去将红灯状态的构建转变为绿灯状态。当临近发布时,他们就对主代码做一个分支,然后开发人员和测试人员再用一周时间,力图给出一些按说是可以“交付”并工作的代码。
究竟是哪里完全做错了?
我们看一下最新进展,当前很多团队都在经历这样的问题。那么潜在的解决方案是什么?让我们将问题从组成上分解为两个子问题:
- 过多的开发人员试图去访问同一代码块。
- 代码验证需要过长的时间,信号灯不能尽快地清空。
如果能缓解其中任一子问题,那么该问题就会迎刃而解。
将开发人员分为团队
让我们首先看一下第一个子问题:过多的开发人员工作于同一个代码库上。首先,我们当然完全有理由雇用很多的开发人员。这是出于加快开发的考虑。将开发人员遣送回家无助于我们解决问题。这在某种方式上回避了问题。我们需要的是在保持生产效率的同时,降低对代码库或持续集成流水线的争用。我们想要减少的是开发人员之间的相互等待问题。
还有另一种方法。我们可以将一个代码库分解为多个代码库,每个代码库对应不同的工作团队。在并发编程的情况下,这种做法可以移除单一互斥锁,并以多重锁取而代之,进而降低了竞争,减少了开发人员的等待。虽然我们解决了一个问题,但是又引入了另一个问题。我们现在有多个不同的可交付软件,它们可以是微服务或是软件库,但都是经过独立测试的。这些可交付软件共享同一个合约。但是测试无法看到整体的视图。我们无法确定这些组件间的相互交互情况,因为它们现在都是独立的系统,具有独立的测试集。现在我们的测试的包容性和可枚举性更低,作为验收测试(Acceptance Test)最终对产品负责人(Product Owner)和用户的用处更低。
因此我们引入了第二阶段的持续集成流水线。该流水线将可交付软件组合在一起,给出试验系统运行的测试。为管理这些测试,我们引入了一个新的团队,并对测试起了新的名字,称为“端到端的测试”、“烟雾测试”或“验收测试”。
现在问题所有改变,应该说发生了相当大的改变。我们试图去集成的组件现在更像是一些黑箱组件。对于能在何种程度上控制这些测试的内在运行机制,我们现在失去了控制。在此层面上,我们的测试是更高层级的测试,它实现代价比我们以前使用的单元测试更大,并需要很长的运行时间。
现在我们切分了代码库,并发现不同的团队再次具有了组件开发的能力,但是在将各个组件集成在一起时,我们又回到了老问题上。测试需要很长的运行时间。可以说,我们只是推迟了这个问题的发生。顺此思路,将系统组件化正是微服务的特点。这本身是一个好做法,但是对于解决我们的问题有些画蛇添足,因此我们又再次回到了同一问题上。
面对房间中动作迟缓的大象
那么构建为什么会如此之慢?问题的核心在于网络调用(或磁盘访问)要比方法调用要慢很多。一次网络调用至少用时20毫秒,但是方法调用代价非常低,以至于可以在同样的时间中做上百万次的方法调用。因此不少人认为,应使用单元测试替代集成测试(这里我指的是所有采用网络调用的测试)。虽然这一做法可以解决问题,但是我们还应该看到,房间里面还塞入了另外一头大象。单元测试并非集成测试,其差别在于单元测试遗留下大部分的最终系统未测试。但是,单元测试的确对开发人员编写的代码做了测试。考虑到“配置也是一种代码”,那么在配置Spring、数据库、Nginx等时,为什么我们会很高兴不用对配置做测试,但却一贯坚持应测试开发人员所编写的所有Java代码?为什么语言是针对特定关注的,而配置却不是呢?要是这样的话,我们需要一种能确保语言中类型安全的编译器。事实上并不存在用于配置的编译器,如果有需要做测试,那么它必须是无类型配置吗?要将集成测试替换为单元测试的想法,就是想要做更少的测试。单元测试具有其自身的功能,其中最重要的就是用于良好软件开发过程的开发工具。从最终用户的价值上看,它们是不可替代的。
争论还存在另一个方面。在单元测试环境中,我们可以从任一开始状态设置测试。我们可以访问模拟对象(Mock)和桩程序(Stub),并可以操纵测试的流程,使之聚焦于想要测试的特定功能点上。这种能力可以通过使用控制反转(IoC)承担,也可以通过重载方法(例如,抽象工厂方法模式)实现。使用集成测试时,我们的控制能力很少。虽然我们可以通过在网络层使用WireMock等工具访问Mock和Stub,但是我们不能注入代码到这些组件中。因此我们强制以状态机方式与系统交互。必须遍历多个系统状态才能到达所需测试的特定需求阶段,并必须反复地做网络调用。毫无疑问,这些测试的代价非常之大!
现在我们有了完整的测试循环。开发团队也具有了生产力,但是我们所分享的合约上具有了更多的风险。不同的可交付软件组合现在落在了另一个的团队上,无法运行于可做方法调用的单元测试环境中。我们必须要做网络调用并测试状态机。当前在流水线中,软件开发中的阻塞之处只是向下移动了,但是依然存在。
现在让我们转向“旅程”方法
让我们再看一下这些测试。我们自一开始以来,就已在很大程度上改进了整体过程。我们构建了我们可以做的所有单元测试,这些单一测试运行快速。但是现在我们具有了微服务和多个不同的团队,并集成了第三方组件和商业软件,现在我们想要证明所有这一切都工作正常。我们知道,要证明所有系统集成在一起工作正常,这并非能像对单一功能点那样是可以验证的事情。我们必须通过一系列不同的步骤将这一联邦系统运行一遍。
举个例子,假定我们正在为网店开发一个结算过程。我们采用了不同的微服务处理不同的功能,譬如一个微服务处理购物车,另一个微服务处理产品在网店中的展示,还有一个微服务处理广告等。所有这些组件共享同一个合约,但是开发是独立的。我们需要编写一个执行整个过程的测试。在单元测试场景下,我们可以独立测试每个特性。例如,我们可以测试一个商品是否可以放入到购物车中,或是可以测试购物车中的所有商品的总价是否适当。但是现在我们需要测试的是微服务和Web门户。例如,在测试购物车的功能是否完全正确前,我们要将商品置于购物车中。这意味着,我们需要浏览网站定点击商品条目,将它们添加到购物车中。上述所有操作一并构成了一种新类型的测试,我将其称为“旅程”测试(Journey Test)。通常我们必须将这些组件看作是黑箱,并采用实现代价很大的过程。
在下表中,我们并排列出了一些“旅程”。其中的每个步骤使用一个字母表示,大致表示了访问一个Web网页并做点击的操作。表中列出了五个不同的“旅程”,除了“旅程5”之外,其它都是从A页面开始,并跳转到C页面。依此类推……
(点击放大图像)
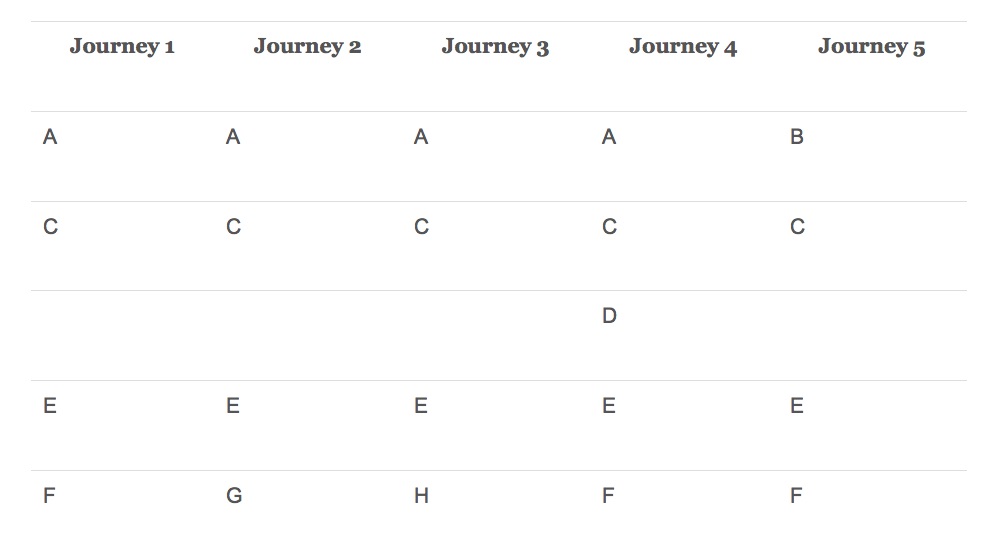
这些“旅程”的运行大约需要30秒时间。
那好,下面让我们仔细查看这些“旅程”,其中将会揭示出如下重要特性。
- 它们是高度重复的。这主要是由于所有“旅程”在结束时的步骤激增,即步骤F、G和H。
- 步骤B和D相比于步骤F,它们的开始方式不同,或是受影响的方式不同,但是终止的方式一样。
其中显然存在一些低效之处。我们可以整合“旅程”测试。在下表中,我就将五个“旅程”减少为三个。
(点击放大图像)

通过明确各“旅程”的测试范畴,我们实现了与上表同样的功能覆盖。这可节省约40%的时间。如果能在整个测试集上获得同样的性能增益,潜在可将30秒的构建优化为22秒。以我个人经验看,可做智能组合的“旅程”测试能给出更加显著的性能增益。
因此,测试者的工作现在变成将测试整合为一个有效的测试脚本并加以管理。但是依然有一些问题需要考虑:
- 如何调用这些测试?测试不再聚集于特定的需求,而是一趟运行就适合多个需求。
- 如何识别间隙?如何知道有哪些遗漏?
- 如何识别冗余的脚本?如果出现了新的需求,我们如何知道应在哪里插入这些新断言?
为此,我编写了一个称为“Cascade”的测试框架,目的就是管理这些复杂性。
有新的问题?我们有新的工具!
那么Cascade是如何解决这些问题的?
我们将构成一个过程的每个步骤分别定义为独立的类。进而Cascade框架将可从中管理并生成测试。
在Cascade的源代码中,提供了一些关于如何使用的例子。第一个例子给出了如何使用Cascade测试一个网络银行网站。
我们必须选定测试开始点。在本例中,我们将打开浏览器加载登陆页面。在GitHub上可以查看工作代码例子。
@Step
public class OpenLandingPage {
@Supplies
private WebDriver webDriver;
@Given
public void given() {
webDriver = new ChromeDriver();
}
@When
public void when() {
webDriver.get("http://localhost:8080");
}
@Then
public void then() {
assertEquals("Tabby Banking", webDriver.getTitle());
}
}
注意:在Cascade框架中,广泛地使用了标注。步骤是维护在不同的文件中的,每个步骤文件用@Step标注。数据采用一种IoC形式在步骤间共享,使用了@Supplies和@Demands标注。生命周期方法标注为@Given、@When和@Then方法。
这里详细介绍一下生命周期方法。@Given用于标注一个将数据提供给测试的方法。测试数据在所有步骤文件间共享。在这一方式下,步骤文件相互协作,描述了各步骤所共同操作的数据。@When标注指示了在当前步骤动作的所使用的方法。该方法通常执行一个状态转移,例如点击按钮,或是提交一个表单。最后,@Then标注了执行验证的方法。
在本文中,我们初始启动Selenium的WebDriver,打开一个监听8080端口的Web服务器的索引页面。我们然后检查Web页面是否已经打开(OpenLandingPage步骤)。
OpenLandingPage步骤之后是Login步骤。代码如下:
@Step(OpenLandingPage.class)
public interface Login {
public class SuccessfulLogin implements Login {
@Supplies
private String username = "anne";
@Supplies
private String password = "other";
@Demands
private WebDriver webDriver;
@When
public void when() {
enterText(webDriver, "[test-field-username]", username);
enterText(webDriver, "[test-field-password]", password);
click(webDriver, "[test-cta-signin]");
}
@Then
public void then() {
assertElementPresent(webDriver, "[test-form-challenge]");
}
}
@Terminator
public class FailedLogin implements Login {
@Supplies
private String username = "anne";
@Supplies
private String password = "mykey";
@Demands
private WebDriver webDriver;
@When
public void when() {
enterText(webDriver, "[test-field-username]", username);
enterText(webDriver, "[test-field-password]", "invalidpassword");
click(webDriver, "[test-cta-signin]");
}
@Then
public void then() {
assertElementPresent(webDriver, "[test-form-login]");
assertElementDisplayed(webDriver, "[test-dialog-authentication-failure]");
}
}
}
从代码中首先应注意到的是,我们现在提供了两个实现接口的类。在Cascade的术语中,称Login步骤具有两个“场景”(Scenario)。一个场景针对Login步骤成功,另一个场景用于Login步骤失败。
其次,我们应注意的是@Step标注。代码中定义了各步骤间的接续关系。从这些信息点中,我们可以很好地了解Cascade做了什么。它扫描了类中标注@Step的类路径(Classpath),将类路径连接起来,加入到测试中。
下面,可以看到有的步骤需要数据。在本例中,就是Login步骤需要Selenium Webdriver的一个实例,以便驱动浏览器。
如果我们仔细地查看了每个“场景”中给出的值,就能注意到这些场景为同一用户设置了数据。如果我们读取@When方法的定义,就会发现向浏览器提供的密码是与所执行的特定“场景”相关的。换句话说,FailedLogin“场景”输入了错误的密码。
可预见的是,@Then方法会检查是否可到达给定“场景”的适当Web页面,否则就给出一个出错对话框。
最后,我们注意到@Terminator标注。该标注用于告知Cascade在该步骤之后没有接续任何步骤。因此,未通过认证的过程会在此标注处终止。
我在GitHub上提供的例子给出了一个扩展到更高层级的“旅程”,欢迎查看。
状态机的建模
到目前为止,我们已经完成了步骤文件的编写,并将步骤文件连接在一起,实现了一些非常有趣的事情。我们不再仅是具有一系列描述过程的独立脚本,而是具有了一个模型。我们建模了一个状态机,并描述了各状态间的转移情况。
一旦我们建立了状态机模型,使用它可以做很多有意思的事情,因为它是个天生丽质的数学系统,而非仅是一系列的脚本。
使用状态机模型,可以在测试报告中生成图
Cascade将生产状态机以图形表示。
(点击放大图像)

我们可以查看“旅程”中任一阶段的数据的汇总情况。通过点击图中对应的链接,我们可以看到如下图所示的细节内容:
(点击放大图像)
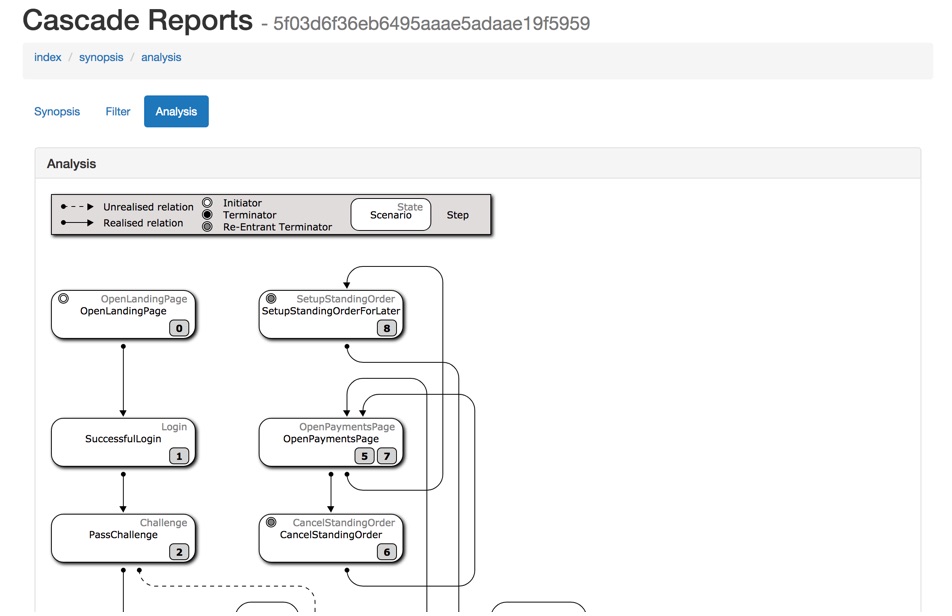
Cascase可以选择性地运行特定的测试或组测试
Cascade允许我们指定用于测试生成器的过滤器。过滤器将过滤掉不匹配指定条件的测试。
@FilterTests
Predicate filter = and(
withStep(Portfolio.CurrentAccountOnly.class),
withStep(SetupStandingOrder.SetupStandingOrderForLater.class)
);
Cascade可以使用算法最小化测试集
这是Cascade的最大亮点,也是我撰写本文的意图所在。我们可以使用算法计算每个“场景”的出现频次,并使用该信息生成最小化的过程测试集,其中包含每个“场景”至少出现一次。更好的是,所使用的算法可以给出每个“场景”的相对值,该信息可用于平衡测试中的“场景”。测试人员不再需要通过分析测试集才能减少测试的执行时间。Cascade自动实现了这一功能。
Cascade可以命名过程测试
Cascade将为每个过程生成一个名字。该名字使用了每个步骤在测试集整体中出现的相对频次,用于高亮指示各个“场景”。
(点击放大图像)
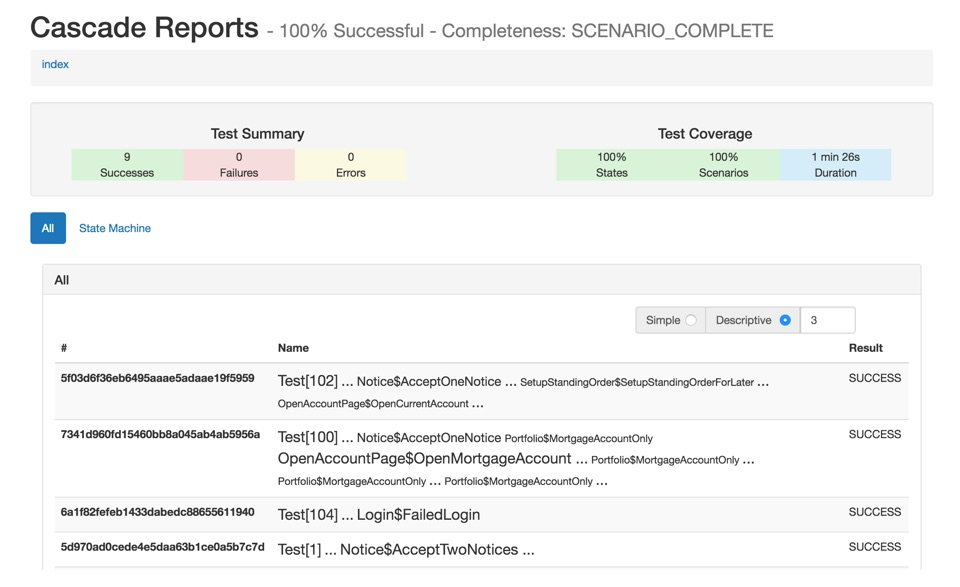
Cascade可使用多种方法最小化测试集
Cascade可以对算法稍作更改,以多种方式最小化测试集。最小测试集不仅可以是面向所有的“场景”给出,而且可以面向所有的步骤(或转换)给出。每个不同的集合以不同方式实现了一个完整的测试,并生成了不同数量的测试。这非常适合于烟雾测试等测试。
Cascade可以关注测试的覆盖情况
Cascade可以计算测试集对测试整体的覆盖情况。这完全不同于传统的代码覆盖报告。
那么我们失去了什么?
我们不再需要亲自去直接编写测试脚本,不再需要向系统提交脚本后才能知道脚本的运行情况。这是否需要付出过高的代价,在很大程度上取决于Cascade在实践中的可理解性和适应性。Cascade的所作所为可能在一开始看上去非常神奇或奇幻,但是它所生成的测试报告不仅仅解决了当前的问题。而且能以图形化的方式对状态机建模,进而提供了一种查看和分析系统的方式,我并不认为在Cascade出现之前,这些功能也能实现。
总结一下
在团队更大时,系统测试就变成了一个艰难的问题,因为系统中具有了更多的过程,并采用了微服务架构。如何推进测试在本质上变成了另一个迥异的问题。如果采用单元测试环境,那么很多特定的功能点将无法测试。在测试中,我们也会受困于代价非常大的网络调用。除非将技术栈均质化并抽象出网络调用,否则我们无法从这些问题中脱身。我们需要新的工具去处理这些状态机。我们应该用好这些天生丽质的状态机。
作者简介
Robin de Villiers是一名Java开发人员,在伦敦的Fluidity Solutions公司任经理。Robin在银行机构、游戏公司、电信行业和政府机构等具有17年的应用开发经验,并在开发一线工作多年。Robin热衷于解决实际问题,重在可使用的工具和方法。
查看英文原文: Automated Journey Testing with Cascade
转自 http://www.infoq.com/cn/articles/Cascade-Automated-Journey-Testing