 Linuxeden开源社区
Linuxeden开源社区
本系列中关于人工智能和机器学习的上一篇文章在很多方面都至关重要。首先,我们开始使用 scikit-learn,这是一个非常强大的 Python 库,可用于开发基于人工智能和机器学习的应用程序。其次,我们部署了第一个训练有素的模型。但最重要的是,这篇文章介绍了 ChatGPT,这可能是印度印刷杂志第一次介绍 ChatGPT。这篇文章是人工智能系列的第八篇,它讲述了更多关于神经网络和无监督学习的内容,并介绍了 PyTorch,一个能够从数据中学习的非常强大的框架。
正如上一篇文章所述,ChatGPT 是 OpenAI 于 2022 年 11 月推出的一款聊天机器人。在短短两个月的时间里,ChatGPT 已经形成了两个对立的派别。一派支持像 ChatGPT 这样基于人工智能的工具,并等待着人工智能创造的乌托邦世界。另一派则对人工智能忧心忡忡,并做出了末日预言。他们担心会出现一个乌托邦式的未来–类似于 “终结者 “的场景,即机器控制人类,而不是相反。这一派中的一些人还认为 ChatGPT 将成为就业杀手。这些人认为,可能受到威胁的工作包括商业转录、医疗转录、文案写作、教学、法律工作等。但请记住,半个世纪前,许多人认为计算机是工作杀手,看看他们错得有多离谱。有些人还预言,像 ChatGPT 这样的工具可能是谷歌、必应、百度等传统搜索引擎末日的开始–我个人并不认同这种观点。
但 ChatGPT 的受欢迎程度如何呢?FaceBook 在 2004 年花了 10 个月的时间才获得 100 万用户。2006 年,Twitter 用了大约两年时间才获得一百万用户。Instagram 在 2010 年上市后的两个半月内,下载量就超过了 100 万。这些都是了不起的成就。但是,你知道 ChatGPT 在向公众开放后花了多少时间才获得一百万用户吗?不到一周!太不可思议了,不是吗?写这篇文章时,我还不知道确切的用户数量。但如今,由于用户数量庞大,ChatGPT 的服务经常无法使用。
同样由 OpenAI 提供的 DALL-E 2 也是一个能够根据描述生成图像的工具。为了艺术,我希望至少专家馆长能够区分两者,就像宝石学家能够轻松区分真假钻石一样,这对普通人来说并非易事。
我们还应该思考,像 ChatGPT 这样的突破性工具将如何影响人工智能相关的研究经费。它可能会为人工智能领域带来更多的资金,从而催生更多突破性的工具和发明。然而,这种期望值的提高也可能导致失望,并引起资助大部分研究的工业巨头的负面反应。在这种时候预测人工智能的未来并不安全。也许我们应该请 ChatGPT 来预测一下。不过,我建议大家阅读维基百科上题为 “人工智能的冬天 “的文章,以了解更多关于人工智能领域研究经费的信息,因为夸大的期望在现实中并没有得到回应。另外,如果你还没有使用过 ChatGPT 或 DALL-E 2,我再次恳请你尝试一下。你会被它们深深吸引的。现在,让我们回到基于人工智能和机器学习创建简单应用程序的卑微努力上来。
Keras 和神经网络
在上一篇文章中,我们使用 MNIST 手写数字数据库训练了第一个模型。我们还使用一些手写数字的扫描图像测试了我们的模型。在上一篇文章中,除了第 16、19 和 20 行外,我们对代码进行了逐行详细解释。这几行代码是模型的核心,我们在上一篇文章中只是简单地说明了这一点。这三行代码定义了模型中使用的神经网络的属性以及训练参数。在本文中,我们将详细讨论这三行代码,以便更清楚地了解神经网络及其训练。首先,请看下图中用于开发模型的第 16 行代码。请注意,虽然代码跨越了多行,但从语法上讲,它是一条单一的代码语句。
model = keras.Sequential( [keras.Input(shape=input_shape),layers.Conv2D(32, kernel_size=(3, 3), activation=”relu”),layers.MaxPooling2D(pool_size=(2, 2)),layers.Conv2D(64, kernel_size=(3, 3), activation=”relu”),layers.MaxPooling2D(pool_size=(2, 2)),layers.Flatten(),layers.Dropout(0.5),layers.Dense(num_classes, activation=”softmax”), ] ) |
让我们简要回顾一下第 1 行至第 15 行对我们的模型所做的工作。首先,我们导入了必要的 Python 库,如 NumPy、Keras 等。然后,我们固定了类的数量、输入形状等。接着,我们加载了 MNIST 数据集,并将其分为训练数据和测试数据。之后,我们检查系统中是否存在训练过的模型。如果已经存在训练有素的模型,我们这样做是为了避免耗费时间和资源的模型训练过程。如果不存在经过训练的模型,那么用于训练的模型的属性由第 16 行代码定义。
现在,让我们来详细看看上面显示的那行代码。首先,确定使用的神经网络类型。回想一下,神经网络有一个输入层、若干个隐藏层和一个输出层。此外,每一层都有若干节点(神经元)。我们使用 Keras 的序列 API 提供的类 Sequential( ) 定义了一个序列模型。顺序模型是层的堆叠,其中每一层都有一个输入张量和一个输出张量。通过该模型,我们可以逐层创建神经网络。顺序模型是一个相对简单的神经网络模型。如果想创建更复杂的神经网络,可以使用 Keras 的函数式 API 提供的 Model( ) 类。如果需要,函数式 API 可以处理具有共享层和多个输入或输出的模型。不过,我更喜欢更简单的顺序模型。
现在,让我们试着了解给顺序模型提供的输入参数。代码 “keras.Input(shape=input_shape) “定义了输入层的输入形状。在本例中,形状为 (28, 28, 1),因为我们用于训练的 MNIST 数据集由一组 28×28 像素的手写数字灰度图像组成。代码 “layers.Conv2D(32, kernel_size=(3, 3), activation=”relu”) “定义了一个二维卷积层。
顺便问一下,什么是卷积层?卷积层将滤波器应用于输入,从而产生激活。代码中的整数 32 指定了参数 filters,它定义了卷积中输出滤波器的数量。第二个参数 kernel_size 指定了二维卷积层的高度和宽度。记得我们在本系列的第六篇文章中已经讨论过一般的激活函数,特别是名为 “relu”(整流线性单元)的激活函数。请注意,二维卷积层还可以指定很多其他参数。但我们的简单示例只指定了我们已经讨论过的三个参数。代码 “layers.MaxPooling2D(pool_size=(2, 2)) “会生成一个用于处理二维空间数据的最大池化层。它通过为输入的每个通道提取输入窗口中的最大值,对输入数据沿空间维度进行向下采样。输入窗口的大小由参数 pool_size 指定,在本例中为 (2, 2)。现在,让我们通过一个简单的例子来了解最大值池的工作原理。请看图 1 所示的代码。

图 1:二维最大池化层的效果
第 1 行导入 TensorFlow。第 2 行定义了一个名为 data 的二维张量。第 3 行将 data 的维度重塑为 (1,2,2,1)。第 4 行使用 MaxPooling2D 类创建对象 max_pool。请注意,参数 pool_size 为 (2,2)。第 5 行对名为 data 的张量执行最大池化操作并打印结果。由于 data 是一个二维张量,因此 max_pool 只返回一个元素。图 1 也显示了脚本的输出结果。可以看到,返回的值是 44.4,即名为 data 的张量中存储的最大值。
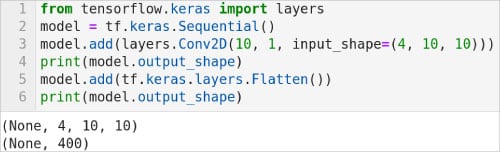
现在,让我们回到模型中第 16 行代码的剩余部分。layer.Conv2D(64,kernel_size=(3,3),activation=”relu”) “代码定义了神经网络的另一个二维卷积层,但这次指定的参数过滤器为 64。同样,代码 “layers.MaxPooling2D(pool_size=(2, 2)) “再次生成了一个最大池化层。layer.Flatten() “代码会生成一个图层,将多维张量作为输入,并将其转换为单维张量。为了更好地理解该层的工作原理,请参考图 2 所示的代码。
第 1 行导入了 Keras 的层 API。第 2 行定义了一个顺序模型。第 3 行使用 add( ) 方法为该模型添加了一个二维卷积层。这行代码还演示了如何逐层构建顺序模型。第 4 行打印该层的输出形状。图 2 显示当前的输出形状为(None, 4, 10, 10)。第 5 行添加了一个扁平层。第 6 行打印扁平化图层的输出形状。图 2 显示该层的输出形状为(无,400)。请注意,该层并不影响数据值,它只是对数据进行了重塑。
现在,让我们来看看模型第 16 行代码中的剩余代码。layer.Dropout(0.5) “代码创建了一个 Dropout 层。在训练过程中,该层每一步都会以一定的频率将输入单位随机设置为 0。这有助于防止过度拟合。简单来说,过度拟合是数学模型从训练数据中学习过多时面临的问题。这会导致模型无法根据新数据进行预测。在 Dropout 层中,未设置为 0 的输入数据会按 1/(1 – 速率)的系数进行缩放,从而使所有输入数据的总和保持不变。在我们的模型中,参数 rate 被指定为 0.5。layers.Dense(num_classes,activation=”softmax”) “代码创建了一个密集连接的神经网络层。第一个参数称为单位(在我们的示例中由变量 num_classes 提供),定义了这一层的输出维度。请注意,在我们的模型中,变量 num_classes 的值是 10,因为我们要对 0 到 9 的十进制数字进行分类。此外,我们使用的激活函数不是 “relu”,而是 “softmax”,这是一个稍微复杂的激活函数。请阅读维基百科上题为 “Softmax 函数 “的文章,以便更好地理解这个激活函数。最后,第 16 行代码中的 Sequential 类返回的生成模型被存储在一个名为 model 的对象中。因此,我们的模型总共有七层。代码的第 17 和 18 行定义了模型的批量大小和历时大小。
现在,请看用于开发模型的第 19 行代码,如下所示。
model.compile(loss=”categorical_crossentropy”, optimizer=”adam”, metrics=[“accuracy”])
])
让我们试着理解一下上面这行代码。在开始训练模型之前,我们需要使用方法 compile( ) 配置训练过程。编译( )方法有三个参数。它们是:损失、优化器和度量。损失函数是模型试图最小化的目标。损失函数包括均方误差(mean_squared_error)、绝对均方误差(mean_absolute_error)、绝对均方误差百分比(mean_absolute_percentage_error)、对数均方误差(mean_squared_logarithmic_error)、铰链(hinge)、二元交叉熵(binary_crossentropy)、分类交叉熵(categorical_crossentropy)、泊松(poisson)、余弦接近度(cosine_proximity)等。在我们的模型中,我们使用了名为分类交叉熵的目标函数。它用于优化分类模型。可供选择的优化器包括 SGD、RMSprop、Adagrad、Adadelta、Adam、Adamax、Nadam 等。在我们的模型中,我们使用了名为 “adam”(亚当)的优化器。Adam 是一种基于梯度的一阶优化算法,适用于随机目标函数。关于 Adam 的详细讨论超出了本教程的范围。最后,度量是用来衡量模型性能的函数。在我们的模型中,我们将 “准确度 “作为衡量指标。该指标计算的是预测结果与标签结果相等的频率。正是因为包含了这一指标,我们才能在处理测试数据时打印出模型的准确度。除了准确度指标,还有其他指标,如概率指标、回归指标、图像分割指标等。
现在,请看下图中用于开发模型的第 20 行代码。
model.fit(x_train, y_train, batch_size=batch_size, epochs=epochs, validation_split=0.1)
让我们试着理解上面这行代码。以下参数会传递给 fit( ) 方法。变量 x_train 包含训练数据。训练数据可以是 NumPy 数组或 TensorFlow 张量。变量 y_train 包含目标数据。目标数据也可以是一个 NumPy 数组或一个 TensorFlow 张量。指定批次大小和历时次数的参数也会传递给 fit( ) 方法。参数 validation_split 用于确定训练数据中用作验证数据的部分。在我们的模型中,该参数的指定值为 0.1。训练完成后,该模型会保存在我们的系统中,这样就可以避免将来不必要的训练。之后,我们会使用测试数据来检验训练出的模型的准确性。最后,我们的模型可用于对新的手写数字图像进行预测。至此,关于第一个训练好的模型的讨论就结束了。
使用 scikit-learn 进行无监督学习
我们知道,机器学习的两个重要范式是监督学习和无监督学习。虽然没有这两种模式流行,但还有其他范式,如半监督学习和强化学习。但到目前为止,我们在本系列中的讨论完全基于监督学习和无监督学习。虽然我们讨论了无监督学习,但迄今为止,我们一直非常重视线性回归和分类等有监督学习算法。
现在,是时候更多地讨论无监督学习了,它是一种使用无标签数据的学习方法。与有监督学习一样,无监督学习也有聚类、降维等不同算法。在本文中,我们将重点讨论聚类。聚类是对一组对象进行分组,使同组对象之间的关联度高于其他组对象。有许多不同的聚类算法–K-Means 聚类、亲和传播聚类、均值移动聚类、光谱聚类、分层聚类、DBSCAN 聚类、OPTICS 聚类等。本文将使用 scikit-learn 库实现 K-Means 聚类。
K-Means 聚类算法首先选择 K 个随机点作为聚类中心。待分组的对象会被分配到随机选择的 K 个聚类中的一个。根据分配给每个聚类的对象数量,反复计算新的聚类中心,直到对象的分组趋于稳定。现在,让我们熟悉一下使用 scikit-learn 实现 K-Means 聚类的 Python 脚本(如下所示)。由于程序比较庞大,为了更好地理解,这里将逐部分进行解释。为了便于解释,在程序中添加了行号。
1. import numpy as np2. from matplotlib import pyplot as plt3. from sklearn.datasets import make_ blobs4. from sklearn.cluster import KMeans5. X, y = make_blobs(n_samples=200, centers=2, n_features=2, cluster_ std=0.5, random_state=0)6. plt.scatter(X[:,0], X[:,1])7. plt.show( ) |
让我们试着理解上述几行代码。第 1 和第 2 行导入了 NumPy 和 Matplotlib。第 3 行导入 make_blobs() 方法。第 4 行导入 KMeans() 类。第 5 行调用 make_blobs( ) 方法生成用于聚类的各向同性高斯 Blobs。以单个实体形式存储的二进制数据集合称为 blob(二进制大对象)。前面两句话是什么意思呢?在这个例子中,我们没有使用实际数据,而是生成样本数据来测试 K-Means 聚类算法。但与本系列中的许多其他场合不同的是,我们这次生成的不是随机数据。生成的样本数据取决于我们传递给 make_blob( ) 方法的参数。在这个示例中,我们采集了 200 个样本(参数 n_samples),只有两个中心(参数 centers)。参数 n_features 决定了生成数据集的列数或特征数。由于我们要在二维平面上绘制生成的数据,因此 n_features 至少应为 2。 参数 cluster_std 用于确定聚类的标准偏差。本例中为 0.5。参数 random_state 决定了创建数据集的随机数生成方式。方法 make_blob( ) 返回生成的样本(本例中存储在数组 X 中)和每个样本的聚类成员身份的整数标签(本例中存储在 y 中)。最后,第 6 和第 7 行将生成的样本数据绘制并显示在二维平面上。
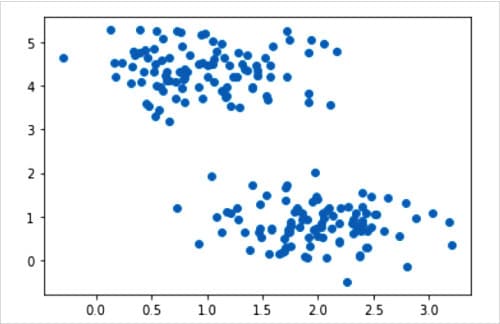
图 3 显示了生成的样本数据图。
现在我们有了必要的数据,让我们试着从这些数据中识别群集。下面几行代码就可以做到这一点。
8. kmeans = KMeans(n_clusters=2, init=’k-means++’, max_iter=1000, random_state=0)9. predict_y = kmeans.fit_predict(X)10. plt.scatter(X[:,0], X[:,1])11. plt.scatter(kmeans.cluster_centers_ [:, 0], kmeans.cluster_centers_ [:, 1], s=500, c=’green’)12. plt.show( ) |
现在,让我们试着理解上述几行代码。第 8 行调用 KMeans 类创建了一个名为 kmeans 的对象。让我们讨论一下传递给该类的参数。参数 n_clusters 固定了要形成的聚类数量以及要生成的聚类中心数量。参数 init 决定初始化的方法。参数 init 有两个选项,分别是 “k-means++”和 “随机”。该参数决定如何确定聚类中心。我们选择了 “k-means++”,因为它在寻找聚类中心时收敛速度更快。参数 max_iter 决定 K-Means 算法单次执行的最大迭代次数。本例中为 1000 次。参数 random_state 决定初始化聚类中心时生成的随机数。第 9 行使用 KMeans() 类的 fit_predict( ) 方法计算聚类中心,并预测样本数据中每个样本所属的聚类。第 10 行再次绘制生成的样本数据。第 11 行用绿色绘制聚类中心。最后,第 12 行显示绘制的图像。图 4 显示了生成的样本数据和确定的聚类中心。这样,我们就实现了第一个简单的无监督学习算法。
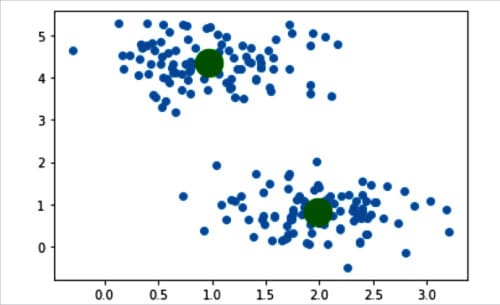
图 4:通过 K-Means 聚类确定的聚类中心
PyTorch 简介
现在让我们来熟悉一下 PyTorch,这是一个基于 Torch 库的强大机器学习框架。Torch 是一个开源机器学习库,也是一个基于 Lua 编程语言的科学计算框架。PyTorch 是在修改后的 BSD 许可下发布的免费开源软件。PyTorch 可以在 CPU 模式和 GPU 模式下工作。但为了使用 PyTorch 的 GPU 模式,我们需要在系统中安装 Nvidia 显卡和 CUDA 平台。和以前一样,PyTorch 的安装将由 Anaconda Navigator 负责。让我们先讨论一个使用 PyTorch 的简单 Python 脚本。请看图 5 所示的 Python 脚本。
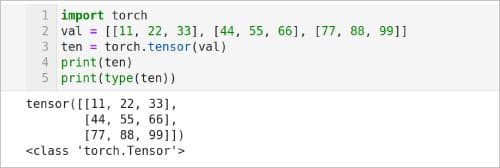
图 5:PyTorch 的初步介绍
我们已经讨论过张量以及如何使用 TensorFlow 创建张量。我们也可以使用 PyTorch 创建张量。现在,让我们试着理解图 5 所示的 Python 脚本,它使用 PyTorch 创建了一个张量。第 1 行导入了 PyTorch 库。第 2 行定义了一个名为 val 的二维列表。第 3 行将列表 val 转换为名为 ten 的张量。第 4 行打印张量 ten 的内容。图 5 也显示了脚本的输出。请注意,即使转换为张量 ten 后,列表 val 中的值仍保持不变。最后,第 5 行打印了张量 ten 的类型,其类型为 torch.Tensor
图 6 显示了一个用随机值生成张量的 Python 脚本。脚本的第 1 行使用方法 rand( ) 生成一个 3×3 矩阵,并将其存储在名为 random_tensor 的张量中。第 2 行打印张量 random_tensor 的内容。脚本的输出也如图 6 所示。请注意,由于我们使用 rand( ) 方法生成随机张量,因此每次迭代时张量的内容都会发生变化。最后,第 3 行显示 random_tensor 的类型也是 torch.Tensor。
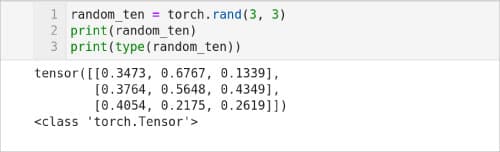
图 6:随机张量
也可以将 NumPy 数组转换为 PyTorch 张量。第 1 行导入 NumPy。第 2 行创建一个二维 NumPy 数组,并将其存储在名为 val 的变量中。第 3 行打印 val 的类型。图 7 也显示了脚本的输出。可以看出,val 的类型是 numpy.ndarray(NumPy 数组)。第 4 行使用 from_numpy( ) 方法将数组 val 转换为 PyTorch 张量,并将其存储在名为 ten 的变量中。第 5 行打印变量 ten 的类型。注意 ten 的类型是 torch.Tensor。最后,第 6 行打印了张量 ten 的内容。张量 ten 中的值与数组 val 中的值相同。在本系列的下一篇讨论自然语言处理的文章中,我们将再次讨论 PyTorch。
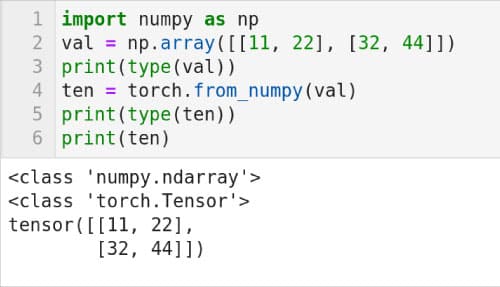
图 7:数组到张量的转换
现在,是时候结束本文了。在本文中,我们对神经网络有了更多的直观认识。此外,我们还使用 scikit-learn 学习了更多关于无监督学习的知识。我们还与 PyTorch 进行了首次互动。在本系列有关人工智能和机器学习的下一篇文章中,我们将继续探索模型训练和神经网络。自然语言处理(NLP)是人工智能和机器学习的一个重要领域。不过,在本系列文章中,我们还没有讨论任何有关基于人工智能的 NLP 的内容。因此,在下一篇文章中,我们将讨论使用 PyTorch 的 NLP,并熟悉 NLTK(自然语言工具包),这是一个专门用于 NLP 的 Python 库。
转自 AI: More About Neural Networks and an Introduction to PyTorch (opensourceforu.com)