 Linuxeden开源社区
Linuxeden开源社区InfluxData 是一个开源的时间序列数据库平台。下面介绍了它是如何被用于边缘应用案例的。
收集到的随时间变化的数据称为时间序列数据。今天,它已经成为每个行业和生态系统的一部分。它是不断增长的物联网行业的一大组成部分,将成为人们日常生活的重要部分。但时间序列数据及其需求很难处理。这是因为没有专门为处理时间序列数据而构建的工具。在这篇文章中,我将详细介绍这些问题,以及过去 10 年来 InfluxData 如何解决这些问题。
InfluxData
InfluxData 是一个开源的时间序列数据库平台。你可能通过 InfluxDB 了解该公司,但你可能不知道它专门从事时间序列数据库开发。这很重要,因为在管理时间序列数据时,你要处理两个问题:存储生命周期和查询。
在存储生命周期中,开发人员通常首先收集和分析非常详细的数据。但开发人员希望存储较小的、降低采样率的数据集,以描述其趋势,而不占用太多的存储空间。
查询数据库时,你不希望基于 ID 查询数据,而是希望基于时间范围进行查询。使用时间序列数据最常见的一件事是在一段时间内对其进行汇总。在典型的关系型数据库中存储数据时,这种查询是很慢的,这种数据库使用行和列来描述不同数据点的关系。专门为处理时间序列数据而设计的数据库可以更快地处理这类查询。InfluxDB 有自己的内置查询语言:Flux,这是专门为查询时间序列数据集而构建的。
Telegraf 如何工作的图像
数据采集
数据采集和数据处理都有一些很棒的工具。InfluxData 有 12 个以上的客户端库,允许你使用自己选择的编程语言编写和查询数据。这是自定义用法的一个很好的工具。开源摄取代理 Telegraf 包括 300 多个输入和输出插件。如果你是一个开发者,你也可以贡献自己的插件。
InfluxDB 还可以接受上传小体积历史数据集的 CSV 文件,以及大数据集的批量导入。
import mathbicycles3 = from(bucket: "smartcity")|> range(start:2021-03-01T00:00:00z, stop: 2021-04-01T00:00:00z)|> filter(fn: (r) => r._measurement == "city_IoT")|> filter(fn: (r) => r._field == "counter")|> filter(fn: (r) => r.source == "bicycle")|> filter(fn: (r) => r.neighborhood_id == "3")|> aggregateWindow(every: 1h, fn: mean, createEmpty:false)bicycles4 = from(bucket: "smartcity")|> range(start:2021-03-01T00:00:00z, stop: 2021-04-01T00:00:00z)|> filter(fn: (r) => r._measurement == "city_IoT")|> filter(fn: (r) => r._field == "counter")|> filter(fn: (r) => r.source == "bicycle")|> filter(fn: (r) => r.neighborhood_id == "4")|> aggregateWindow(every: 1h, fn: mean, createEmpty:false)join(tables: {neighborhood_3: bicycles3, neighborhood_4: bicycles4}, on ["_time"], method: "inner")|> keep(columns: ["_time", "_value_neighborhood_3","_value_neighborhood_4"])|> map(fn: (r) => ({r withdifference_value : math.abs(x: (r._value_neighborhood_3 - r._value_neighborhood_4))}))
Flux
Flux 是我们的内部查询语言,从零开始建立,用于处理时间序列数据。它也是我们一些工具的基础动力,包括 任务、警报 和 通知。要剖析上面的 Flux 查询,需要定义一些东西。首先,“桶”就是我们所说的数据库。你可以配置存储桶,然后将数据流添加到其中。查询会调用 smartcity 存储桶,其范围为特定的一天(准确地说是 24 小时)。你可以从存储桶中获取所有数据,但大多数用户都包含一个数据范围。这是你能做的最基本的 Flux 查询。
接下来,我添加过滤器,将数据过滤到更精确、更易于管理的地方。例如,我过滤分配给 id 为 3 的社区中的自行车数量。从那里,我使用 aggregateWindow 获取每小时的平均值。这意味着我希望收到一个包含 24 列的表,每小时一列。我也对 id 为 4 的社区进行同样的查询。最后,我将这两张表相叠加,得出这两个社区自行车使用量的差异。
如果你想知道什么时候是交通高峰,这是不错的选择。显然,这只是 Flux 查询功能的一个小例子。但它提供了一个很好的例子,使用了 Flux 附带的一些工具。我还有很多的数据分析和统计功能。但对于这一点,我建议查看 Flux 文档。
import "influxdata/influxdb/tasks"option task = {name: PB_downsample, every: 1h, offset: 10s}from(bucket: "plantbuddy")|>range(start: tasks.lastSuccess(orTime: -task.every))|>filter(fn: (r) => r["_measurement"] == "sensor_data")|>aggregateWindow(every: 10m, fn:last, createEmpty:false)|>yield(name: "last")|>to(bucket: "downsampled")
任务
InfluxDB 任务 是一个定时 Flux 脚本,它接收输入数据流并以某种方式修改或分析它。然后,它将修改后的数据存储在新的存储桶中或执行其他操作。将较小的数据集存储到新的存储桶中,称为“降采样”,这是数据库的核心功能,也是时间序列数据生命周期的核心部分。
你可以在当前任务示例中看到,我已经对数据进行了降采样。我得到每 10 分钟增量的最后一个值,并将该值存储在降采样桶中。原始数据集在这 10 分钟内可能有数千个数据点,但现在降采样桶只有 60 个新值。需要注意的一点是,我还使用了范围内的 lastSuccess 函数。这会告诉 InfluxDB 从上次成功运行的时间开始运行此任务,以防它在过去 2 小时内失败,在这种情况下,它可以追溯 3 个小时内的最后一次成功运行。这对于内置错误处理非常有用。
检查和警报通知系统的图像
检查和警报
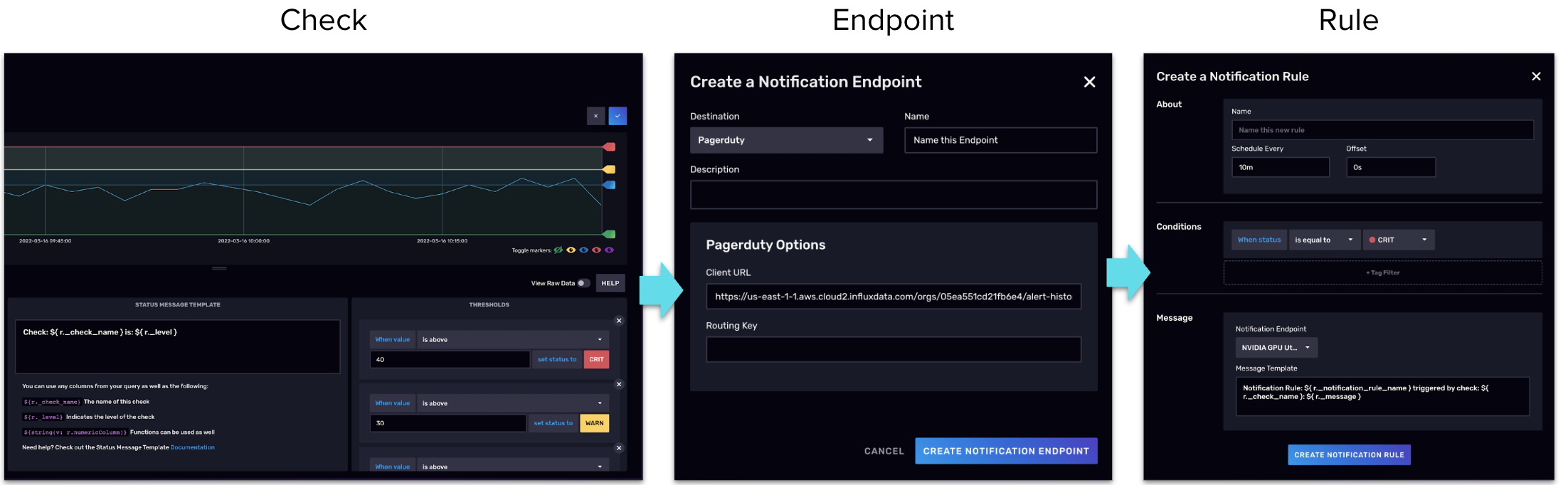
InfluxDB 包含一个 警报 或 检查 和 通知 系统。这个系统非常简单直白。首先进行检查,定期查看数据以查找你定义的异常。通常,这是用阈值定义的。例如,任何低于 32°F 的温度值都被指定为“WARN”值,高于 32°F 都被分配为“OK”值,低于 0°F 都被赋予“CRITICAL”值。从那开始,你的检查可以按你认为必要的频率运行。你的检查以及每个检查的当前状态都有历史记录。在不需要的时候,你不需要设置通知。你可以根据需要参考你的警报历史记录。
许多人选择设置通知。为此,你需要定义一个 通知端点。例如,聊天应用程序可以进行 HTTP 调用以接收通知。然后你定义何时接收通知,例如,你可以每小时运行一次检查。你可以每 24 小时运行一次通知。你可以让通知响应值更改,例如,“WARN”更改为“CRITICAL”,或者当值为“CRITICAL”时,无论如何都从“OK”更改为“WARN”。这是一个高度可定制的系统。从这个系统创建的 Flux 代码也可以编辑。
新 Edge 功能的图像
边缘
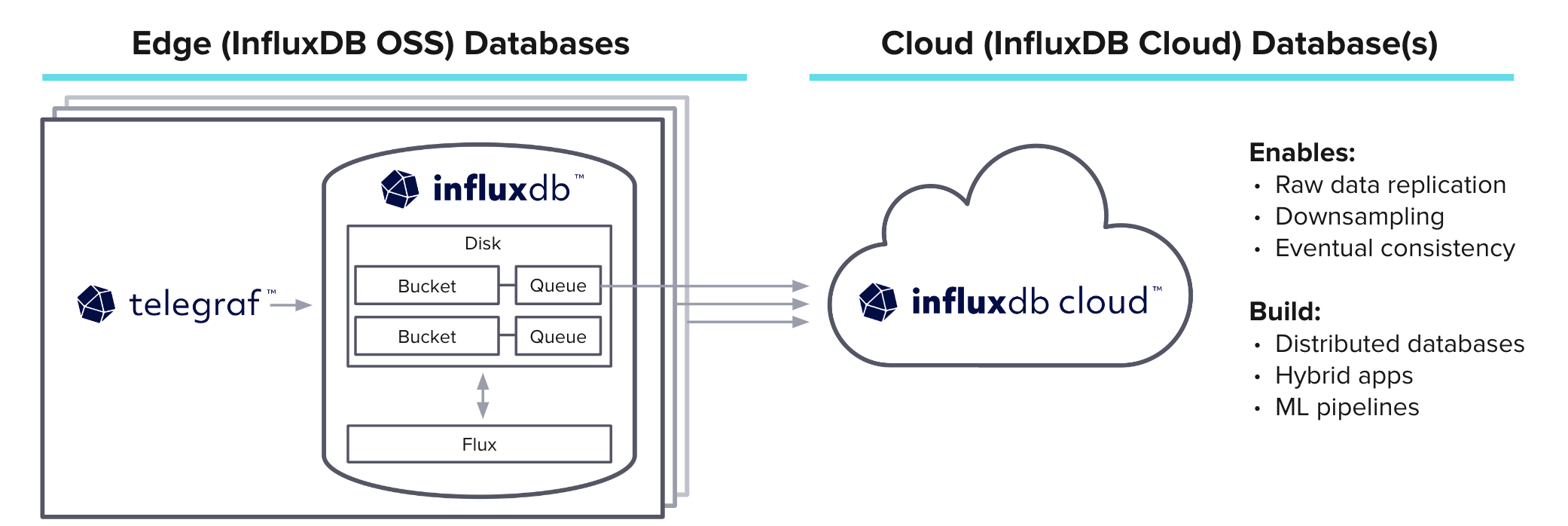
最后,我想把所有的核心功能放在一起,包括最近发布的一个非常特别的新功能。“Edge to cloud” 是一个非常强大的工具,允许你运行开源 InfluxDB,并在出现连接问题时在本地存储数据。连接修复后,它会将数据流传输到 InfluxData 云平台。
这对于边缘设备和重要数据非常重要,因为任何数据丢失都是有害的。你定义一个要复制到云的存储桶,然后该存储桶有一个磁盘支持的队列来本地存储数据。然后定义云存储桶应该复制到的内容。在连接到云端之前,数据都存储在本地。
InfluxDB 和物联网边缘
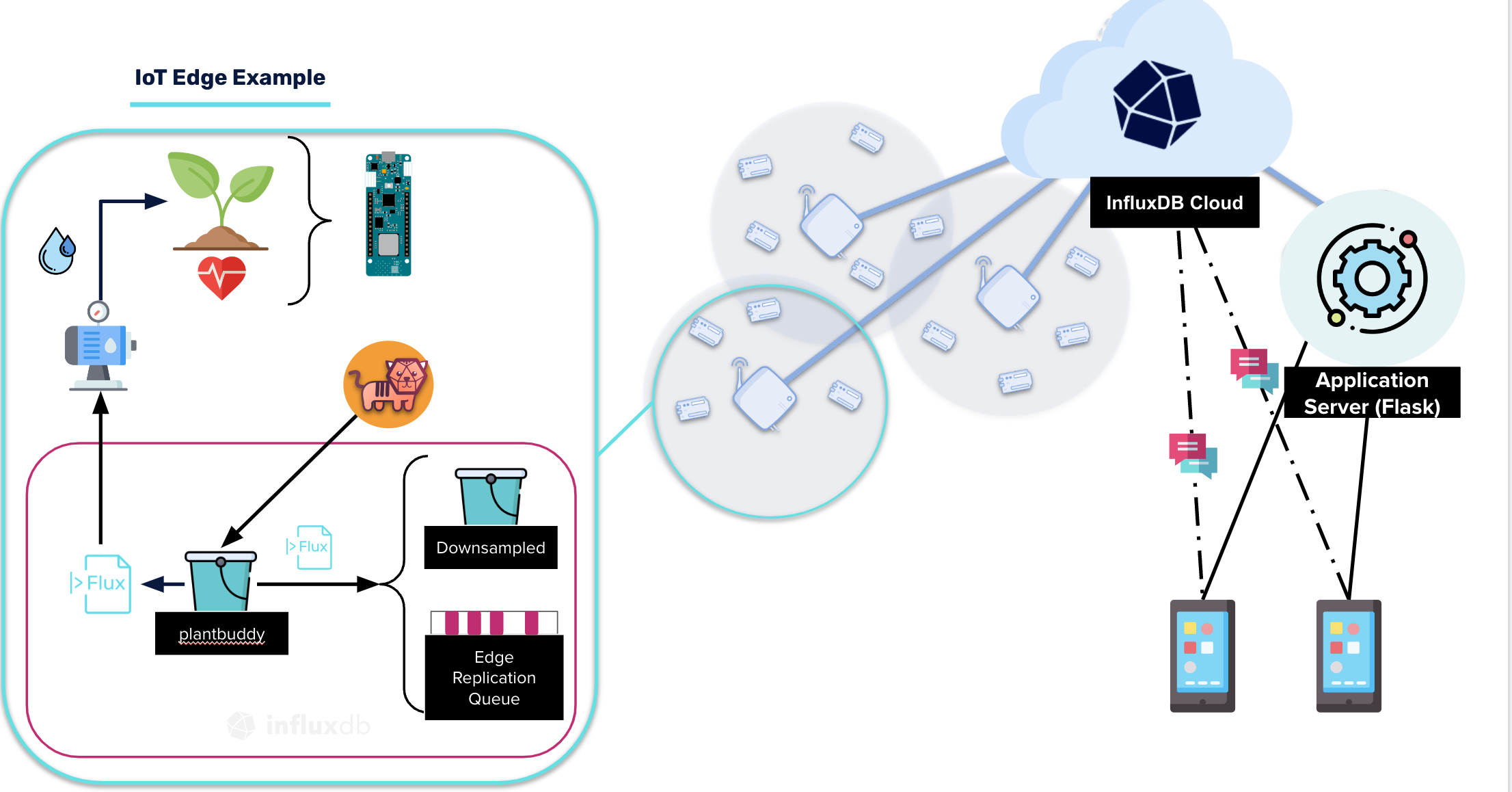
假设你有一个项目,你想使用连接到植物上的物联网传感器 监测家里植物的健康状况。该项目是使用你的笔记本电脑作为边缘设备设置的。当你的笔记本电脑合上或关闭时,它会在本地存储数据,然后在重新连接时将数据流传到我的云存储桶。
图片展示了 Plant buddy 的工作方式
需要注意的一点是,在将数据存储到复制桶之前,这会对本地设备上的数据进行降采样。你的植物传感器每秒提供一个数据点。但它将数据压缩为一分钟的平均数,因此存储的数据更少了。在云账户中,你可以添加一些警报和通知,让你知道植物的水分何时低于某个水平,需要浇水。也可以在网站上使用视觉效果来告诉用户植物的健康状况。
数据库是许多应用程序的主干。在像 InfluxDB 的时间序列数据库平台中使用带有时间戳的数据可以节省开发人员的时间,并使他们能够访问各种工具和服务。InfluxDB 的维护者喜欢看到人们在我们的开源社区中构建什么,所以请与我们联系,并与其他人共享你的项目和代码!
via: https://opensource.com/article/23/1/time-series-data-edge-open-source-tools
作者:Zoe Steinkamp 选题:lkxed 译者:ZhangZhanhaoxiang 校对:wxy
本文由 LCTT 原创编译,Linux中国 荣誉推出