 Linuxeden开源社区
Linuxeden开源社区NoSQL 数据库最近一段时间都是很受追捧的,也许已经是 Node.js 应用程序的首选后端了。不过,你不应该只是根据潮流来选择拿什么技术构建下一个项目,使用什么数据库类型要取决于项目的特定需求。如果你的项目涉及到动态表的创建,实时的插入等等,那么 NoSQL 就是不错的技术路线,而另一方面,如果项目中要处理复杂的查询和事务,那么 SQL 数据库就更加合适了。 在本教程中,我们会向你介绍如何使用 MySQL 模块 – 这是一个用 JavaScript 编写的运行在 Node.js 之上的 MySQL 驱动程序。我会向你解释如何使用该模块连接到 MySQL 数据库,执行常规的 CRUD 操作,之后就是对存储的过程进行检查,以及对用户的输入进行转义这些技术。
这个颇受欢迎的教程在 2017 年 11 月 07 日进行了更新。其中的修改包括将语法更新到了 ES6,解决了node-mysql 模块被重新命名的问题,增加了更多对初学者友好的文字说明,并在 ORM 上新增加了一个部分。
快速入门:如何在 Node 中使用 MySQL
也许你来这是就是为了找到一个快速的法门。如果你是想用尽可能少的时间在 Node 中启动并运行 MySQL,我们能满足你的需求! 以下5个简单步骤告诉你如何在 Node 中使用 MySQL:
- 创建一个新项目:mkdir mysql-test && cd mysql-test
- 创建一个 package.json 文件:npm init -y
- 安装mysql模块: npm install mysql –save
- 创建一个app.js文件并将下面的代码段复制进去。
- 运行该文件: node app.js。会看到一条 “Connected!”(已连接上了)消息。
//app.jsconst mysql = require('mysql');const connection = mysql.createConnection({
host: 'localhost',
user: 'user',
password: 'password',
database: 'database name'});connection.connect((err) => {
if (err) throw err;
console.log('Connected!');});
安装 mysql 模块
现在让我们来仔细看看这些步骤。首先。我们使用命令行创建了一个新目录并且进入到了这个目录底下。然后我们使用命令 npm init -y 创建出了一个 package.json 文件。 -y 标志表示 npm 将仅使用默认值,并且不会提示要你选择任何选项。 此步骤还假设你的系统上已经安装好了 Node 和 npm。如果该假设不成立的话,就去看看 SitePoint 上的这篇文章了解如何继续操作吧:《使用 nvm 安装多个版本的 Node.js》。 之后,我们利用 npm 来安装 mysql 模块,并将其保存为项目的依赖关系。项目依赖关系(类似于开发的依赖关系)就是应用程序运行所需的那些包。 你可以了解到更多关于这两者之间所存在的差异。
mkdir mysql-test cd mysql-test npm install mysql -y
入门
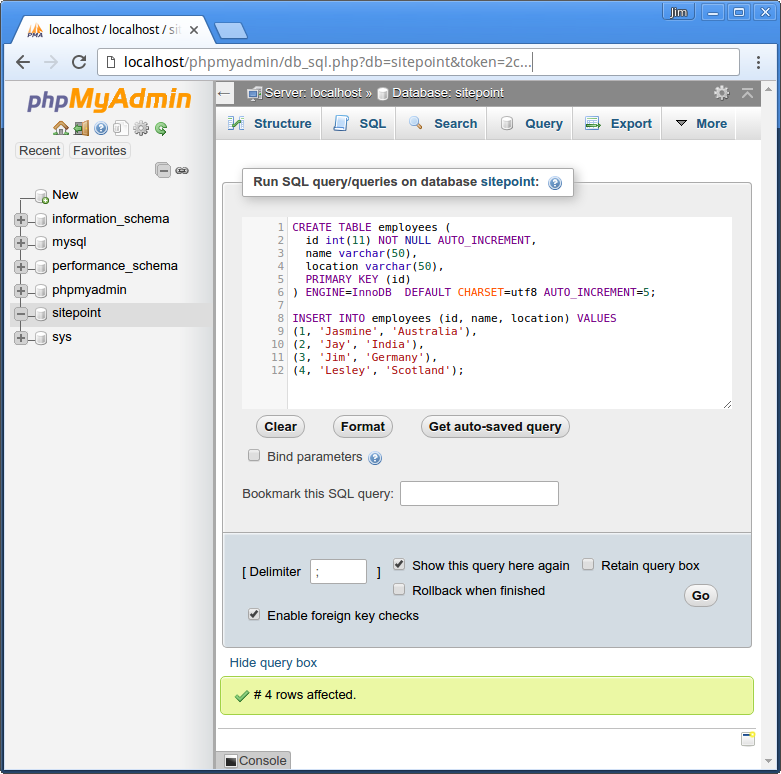
在我们连接到数据库之前,有一件重要的事情就是要在你的机器上安装和配置 MySQL。如果这件事情还没做完,那就看看软件主页上的安装说明自己去装一个吧。 接下来我们需要做的就是创建一个数据库和一个数据库表。你可以使用一个图形用户界面来做到这一点,比如说 phpMyAdmin,或者就使用命令行。 对于我们这篇文章,使用的是一个名为 sitepoint 的数据库和一个名为 employees 的表。如果你希望跟着一起操作的话,这里有一个数据库的转储文件,方便你可以快速地启动并运行起来:
//app.js
const mysql = require('mysql');
const connection = mysql.createConnection({
host: 'localhost',
user: 'user',
password: 'password',
database: 'database name'
});
connection.connect((err) => {
if (err) throw err;
console.log('Connected!');
});
连接到数据库
现在,我们在 mysql-test 目录下创建一个名为 app.js 的文件,来看看如何从 Node.js 连接到 MySQL。
// app.js
const mysql = require('mysql');
// First you need to create a connection to the db
const con = mysql.createConnection({
host: 'localhost',
user: 'user',
password: 'password',
});
con.connect((err) => {
if(err){
console.log('Error connecting to Db');
return;
}
console.log('Connection established');
});
con.end((err) => {
// The connection is terminated gracefully
// Ensures all previously enqueued queries are still
// before sending a COM_QUIT packet to the MySQL server.
});
现在打开一个终端并输入 node app.js。在连接成功建立之后,你应该能够在控制台中看到“Connection established”(连接已经建立好了)这条消息了。 如果出现了什么问题(例如输入了错误的密码),程序就会触发一个回调,该事件会传递出一个 JavaScript Error 对象(err)的实例。 你可以尝试将其打印到控制台以查看其中包含的有用信息以调试程序。
使用 Grunt 来监视文件的更改
每当我们对代码进行更改时,手动运行 node app.js 命令会变得有点乏味,所以让我们来把这个操作自动化吧。 这一节并不需要跟本教程的其余部分并没有依赖关系,不过如果照着做的话肯定会为你节省一些麻烦事儿。 我们首先得安装几个包:
npm install --save-dev grunt grunt-contrib-watch grunt-execute
Grunt 是有名的 JavaScript 任务执行程序,每当监听到有文件发生修改时,grunt-contrib-watch 都会运行已经预定义好的任务,并且会使用 grunt-execute 来运行 node app.js 命令。 安装完成之后,在项目根中创建一个名为Gruntfile.js的文件,然后在里面添加上如下代码。
// Gruntfile.js
module.exports = (grunt) => {
grunt.initConfig({
execute: {
target: {
src: ['app.js']
}
},
watch: {
scripts: {
files: ['app.js'],
tasks: ['execute'],
},
}
});
grunt.loadNpmTasks('grunt-contrib-watch');
grunt.loadNpmTasks('grunt-execute');
};
现在运行 grunt watch 然后修改一下 app.js 文件。Grunt 就应该会检测到我们修改了文件并重新运行 node app.js 命令。
执行查询
读取
现在你知道如何在 Node.js 中建立 MySQL 连接了,再来看看如何执行 SQL 查询。我们从这里开始:建立使用 createConnection 命令连接到名为 sitepoint 的数据库。
const con = mysql.createConnection({
host: 'localhost',
user: 'user',
password: 'password',
database: 'sitepoint'
});
连接建立后我们要使用连接变量来对数据库中的 employees 表进行查询。
con.query('SELECT * FROM employees', (err,rows) => {
if(err) throw err;
console.log('Data received from Db:\n');
console.log(rows);
});
现在运行 app.js (通过 grunt-watch 或者在终端输入 node app.js),你可以看到终端输出从数据库返回的数据。
[ { id: 1, name: 'Jasmine', location: 'Australia' },
{ id: 2, name: 'Jay', location: 'India' },
{ id: 3, name: 'Jim', location: 'Germany' },
{ id: 4, name: 'Lesley', location: 'Scotland' } ]
从 MySQL 数据库返回的数据可以通过遍历 rows 对象来进行解析。
rows.forEach( (row) => {
console.log(`${row.name} is in ${row.location}`);
});
创建
你可以在数据库中执行 insert 查询,像这样:
const employee = { name: 'Winnie', location: 'Australia' };
con.query('INSERT INTO employees SET ?', employee, (err, res) => {
if(err) throw err;
console.log('Last insert ID:', res.insertId);
});
请注意到我们是如何通过回调参数来获得刚插入那条记录的 ID 的。
更新
类似地,在执行 update 查询的时候,通过 result.affectedRows 可得到受影响的行数:
con.query(
'UPDATE employees SET location = ? Where ID = ?',
['South Africa', 5],
(err, result) => {
if (err) throw err;
console.log(`Changed ${result.changedRows} row(s)`);
}
);
删除
delete 查询的操作也差不多:
con.query(
'DELETE FROM employees WHERE id = ?', [5], (err, result) => {
if (err) throw err;
console.log(`Deleted ${result.affectedRows} row(s)`);
}
);
高级用法
我希望有办法通过 mysql 模块来处理存储过程,以及转义用户输入。
存储过程
简单的说,存储过程是存储在数据库中,可以由数据库引擎和连接上数据的程序语言调用的程序(例如,SQL 程序)。如果你需要复习,请看看这篇不错的文章。 先来为我们的 sitepoint 数据库创建一个存储过程,它用于获取所有员工的详情。我们把它命名为 sp_getall。为了做这件事,你需要某种数据库接操作界面。我使用 phpMyAdmin。在 sitepoint 数据库中运行下面的查询:
DELIMITER $$
CREATE DEFINER=`root`@`localhost` PROCEDURE `sp_getall`()
BEGIN
SELECT id, name, location FROM employees;
END
它会将程序保存在 information_schema 数据库的 ROUTINGS 表中。 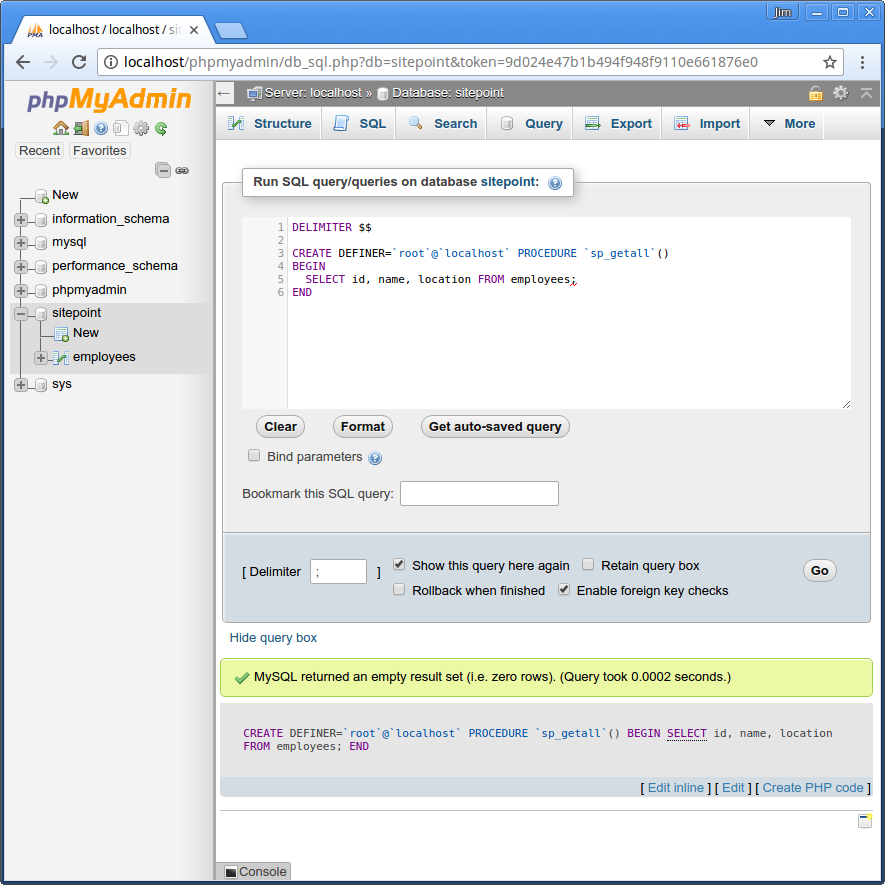
con.query('CALL sp_getall()',function(err, rows){
if (err) throw err;
console.log('Data received from Db:\n');
console.log(rows);
});
保存修改并运行。运行的时候你可以看到从数据库返回的数据。
[ [ { id: 1, name: 'Jasmine', location: 'Australia' },
{ id: 2, name: 'Jay', location: 'India' },
{ id: 3, name: 'Jim', location: 'Germany' },
{ id: 4, name: 'Lesley', location: 'Scotland' } ],
{ fieldCount: 0,
affectedRows: 0,
insertId: 0,
serverStatus: 34,
warningCount: 0,
message: '',
protocol41: true,
changedRows: 0 } ]
这些数据包括一些附加信息,比如影响的行数,insertId 等。你需要对返回数据的第 0 个元素进行遍历以获取员工详情信息。
rows[0].forEach( (row) => {
console.log(`${row.name} is in ${row.location}`);
});
现在考虑一个需要输入参数的存储过程。
DELIMITER $$ CREATE DEFINER=`root`@`localhost` PROCEDURE `sp_get_employee_detail`( in employee_id int ) BEGIN SELECT name, location FROM employees where id = employee_id; END
我们可以在调用存储过程的时候传入参数:
con.query('CALL sp_get_employee_detail(1)', (err, rows) => {
if(err) throw err;
console.log('Data received from Db:\n');
console.log(rows[0]);
});
多数时候,如果我们想在数据库中插入一条记录,需要将插入记录的 ID 作为输出参数返回出来。考虑接下来用于插入数据的存储过程,它有一个输出参数:
DELIMITER $$
CREATE DEFINER=`root`@`localhost` PROCEDURE `sp_insert_employee`(
out employee_id int,
in employee_name varchar(25),
in employee_location varchar(25)
)
BEGIN
insert into employees(name, location)
values(employee_name, employee_location);
set employee_id = LAST_INSERT_ID();
END
为了调用含有输出参数的存储过程,我们需要在创建连接时调用多个程序。因此,修改连接,设置执行多个语句为 true。
const con = mysql.createConnection({
host: 'localhost',
user: 'user',
password: 'password',
database: 'sitepoint',
multipleStatements: true});
然后在调用存储过程的时候,设置并传入一个输出参数。
con.query(
"SET @employee_id = 0; CALL sp_insert_employee(@employee_id, 'Ron', 'USA'); SELECT @employee_id",
(err, rows) => {
if (err) throw err;
console.log('Data received from Db:\n');
console.log(rows);
}
);
在上面的代码中,我们设置了输出参数 @employee_id 并在调用存储过程的时候将其传入。一旦调用完成,我们需要使用 select 查询输出参数来获取返回的 ID。 运行 app.js。如果执行成功你可以看到 select 查询的输出参数和各种其它信息。通过 rows[2] 可获得输出参数的值。
[ { '@employee_id': 6 } ]
转义用户输入
为了避免 SQL 注入攻击,你应该总是转义来自用户的任何数据,然后再把它用于 SQL 查询。来演示一下为什么:
const userLandVariable = '4 ';
con.query(
`SELECT * FROM employees WHERE id = ${userLandVariable}`,
(err, rows) => {
if(err) throw err;
console.log(rows);
}
);
这看起来并没有什么问题,它会返回正确的结果:
{ id: 4, name: 'Lesley', location: 'Scotland' }
不过,如果我们将 userLandVariable 改为:
const userLandVariable = '4 OR 1=1';
居然访问了整个数据集。如果我们再改为这样:
const userLandVariable = '4; DROP TABLE employees';
这下麻烦大了! 好消息是有办法处理这类问题。你只需要使用 mysql.escape 方法:
con.query(
`SELECT * FROM employees WHERE id = ${mysql.escape(userLandVariable)}`,
function(err, rows){ ... }
);
或者使用问号占位符,就像我们在文章一开始提到的那个示例一样:
con.query(
'SELECT * FROM employees WHERE id = ?',
[userLandVariable],
(err, rows) => { ... }
);
为什么不简单地使用 ORM?
你可能注意到了,评论中有人建议使用 ORM。在详述这个方法的优缺点之前,我先看看 ORM 是什么。下面是来自 Stack Overflow 的回答。
对象关系映射(Object-Relational Mapping, ORM) 是一种允许人们使用面向对象范型来查询和操作数据库数据的技术。在谈到 ORM 的时候,多数人是指实现了 ORM 技术的某个库,所以会使用 “an ORM” 这样的短语。
因此,这种方法基本上意味着你会使用 ORM 领域相关的语言来编写数据库逻辑,而不是我们一直在讨论的普通方法。下面以 Sequelize 为例:
Employee.findAll().then(employees => {
console.log(employees);
});
对比:
con.query('SELECT * FROM employees', (err,rows) => {
if(err) throw err;
console.log('Data received from Db:\n');
console.log(rows);
});
小结
本教程中只涉及到了 MySQL 客户端的皮毛。我推荐你去阅读官方文档以了解更详细的信息。当然也有别的选择,比如 node-mysql2 和 node-mysql-libmysqlclient。
你是否已经在 Node.js 中用过这些库来连接到 MySQL?我很想听人说说这些库。请在下面的评论中告诉我们你的想法、建议以及更正意见!