 Linuxeden开源社区
Linuxeden开源社区Apache 软件基金会( Apache Software Foundation,ASF)于官网发文,正式宣布 Apache Hudi 晋升为 Apache 顶级项目(TLP)。
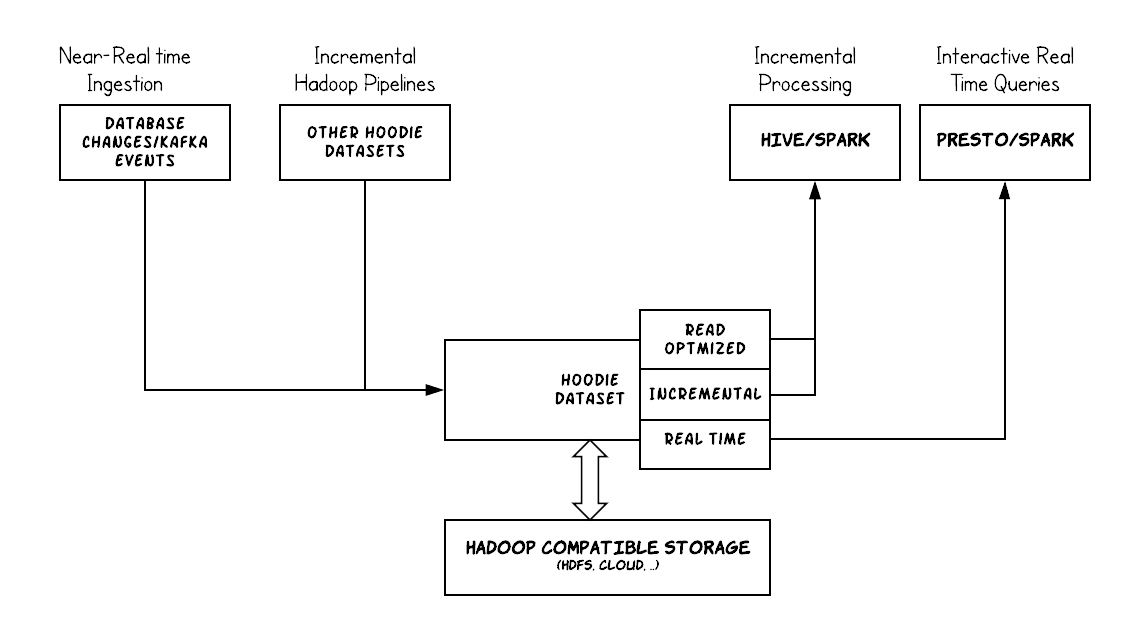
Apache Hudi(Hadoop Upserts Delete and Incremental)数据湖技术可在 Apache Hadoop 兼容的云存储和分布式文件系统之上进行流处理。该项目最初于 2016 年在 Uber 开发(代号和发音为”Hoodie”),于 2017 年开源,并于 2019 年 1 月提交给 Apache 孵化器。
它的核心功能包括:
- 可插拔式的索引支持快速 Upsert/Delete。
- 事务提交/回滚数据。
- 支持捕获Hudi表的变更进行流式处理。
- 支持 Apache Hive、Apache Spark、Apache Impala 和 Presto 查询引擎。
- 内置数据提取工具,支持 Apache Kafka、Apache Sqoop 和其他常见数据源。
- 通过管理文件大小,存储布局来优化查询性能。
- 基于行存快速提取模式,并支持异步压缩成列存格式。
- 用于审计跟踪的时间轴元数据。
转自 https://www.oschina.net/news/116198/apache-hudi-as-top-of-project-of-apache-foundation