 Linuxeden开源社区
Linuxeden开源社区使用 Python 开展数据科学为你提供了无限的潜力,使你能够以有意义和启发性的方式解析、解释和组织数据。
数据科学是计算领域一个令人兴奋的新领域,它围绕分析、可视化和关联以解释我们的计算机收集的有关世界的无限信息而建立。当然,称其为“新”领域有点不诚实,因为该学科是统计学、数据分析和普通而古老的科学观察派生而来的。
但是数据科学是这些学科的形式化分支,拥有自己的流程和工具,并且可以广泛应用于以前从未产生过大量不可管理数据的学科(例如视觉效果)。数据科学是一个新的机会,可以重新审视海洋学、气象学、地理学、制图学、生物学、医学和健康以及娱乐行业的数据,并更好地了解其中的模式、影响和因果关系。
像其他看似包罗万象的大型领域一样,知道从哪里开始探索数据科学可能会令人生畏。有很多资源可以帮助数据科学家使用自己喜欢的编程语言来实现其目标,其中包括最流行的编程语言之一:Python。使用 Pandas、Matplotlib 和 Seaborn 这些库,你可以学习数据科学的基本工具集。
如果你对 Python 的基本用法不是很熟悉,请在继续之前先阅读我的 Python 介绍。
创建 Python 虚拟环境
程序员有时会忘记在开发计算机上安装了哪些库,这可能导致他们提供了在自己计算机上可以运行,但由于缺少库而无法在所有其它电脑上运行的代码。Python 有一个系统旨在避免这种令人不快的意外:虚拟环境。虚拟环境会故意忽略你已安装的所有 Python 库,从而有效地迫使你一开始使用通常的 Python 进行开发。
为了用 venv 激活虚拟环境, 为你的环境取个名字 (我会用 example) 并且用下面的指令创建它:
$ python3 -m venv example
导入该环境的 bin 目录里的 activate 文件以激活它:
$ source ./example/bin/activate(example) $
你现在“位于”你的虚拟环境中。这是一个干净的状态,你可以在其中构建针对该问题的自定义解决方案,但是额外增加了需要有意识地安装依赖库的负担。
安装 Pandas 和 NumPy
你必须在新环境中首先安装的库是 Pandas 和 NumPy。这些库在数据科学中很常见,因此你肯定要时不时安装它们。它们也不是你在数据科学中唯一需要的库,但是它们是一个好的开始。
Pandas 是使用 BSD 许可证的开源库,可轻松处理数据结构以进行分析。它依赖于 NumPy,这是一个提供多维数组、线性代数和傅立叶变换等等的科学库。使用 pip3 安装两者:
(example) $ pip3 install pandas
安装 Pandas 还会安装 NumPy,因此你无需同时指定两者。一旦将它们安装到虚拟环境中,安装包就会被缓存,这样,当你再次安装它们时,就不必从互联网上下载它们。
这些是你现在仅需的库。接下来,你需要一些样本数据。
生成样本数据集
数据科学都是关于数据的,幸运的是,科学、计算和政府组织可以提供许多免费和开放的数据集。虽然这些数据集是用于教育的重要资源,但它们具有比这个简单示例所需的数据更多的数据。你可以使用 Python 快速创建示例和可管理的数据集:
#!/usr/bin/env python3import randomdef rgb():NUMBER=random.randint(0,255)/255return NUMBERFILE = open('sample.csv','w')FILE.write('"red","green","blue"')for COUNT in range(10):FILE.write('\n{:0.2f},{:0.2f},{:0.2f}'.format(rgb(),rgb(),rgb()))
这将生成一个名为 sample.csv 的文件,该文件由随机生成的浮点数组成,这些浮点数在本示例中表示 RGB 值(在视觉效果中通常是数百个跟踪值)。你可以将 CSV 文件用作 Pandas 的数据源。
使用 Pandas 提取数据
Pandas 的基本功能之一是可以提取数据和处理数据,而无需程序员编写仅用于解析输入的新函数。如果你习惯于自动执行此操作的应用程序,那么这似乎不是很特别,但请想象一下在 LibreOffice 中打开 CSV 并且必须编写公式以在每个逗号处拆分值。Pandas 可以让你免受此类低级操作的影响。以下是一些简单的代码,可用于提取和打印以逗号分隔的值的文件:
#!/usr/bin/env python3from pandas import read_csv, DataFrameimport pandas as pdFILE = open('sample.csv','r')DATAFRAME = pd.read_csv(FILE)print(DATAFRAME)
一开始的几行导入 Pandas 库的组件。Pandas 库功能丰富,因此在寻找除本文中基本功能以外的功能时,你会经常参考它的文档。
接下来,通过打开你创建的 sample.csv 文件创建变量 FILE。Pandas 模块 read_csv(在第二行中导入)使用该变量来创建数据帧。在 Pandas 中,数据帧是二维数组,通常可以认为是表格。数据放入数据帧中后,你可以按列和行进行操作,查询其范围,然后执行更多操作。目前,示例代码仅将该数据帧输出到终端。
运行代码。你的输出会和下面的输出有些许不同,因为这些数字都是随机生成的,但是格式都是一样的。
(example) $ python3 ./parse.pyred green blue0 0.31 0.96 0.471 0.95 0.17 0.642 0.00 0.23 0.593 0.22 0.16 0.424 0.53 0.52 0.185 0.76 0.80 0.286 0.68 0.69 0.467 0.75 0.52 0.278 0.53 0.76 0.969 0.01 0.81 0.79
假设你只需要数据集中的红色值(red),你可以通过声明数据帧的列名称并有选择地仅打印你感兴趣的列来做到这一点:
from pandas import read_csv, DataFrameimport pandas as pdFILE = open('sample.csv','r')DATAFRAME = pd.read_csv(FILE)# define columnsDATAFRAME.columns = [ 'red','green','blue' ]print(DATAFRAME['red'])
现在运行代码,你只会得到红色列:
(example) $ python3 ./parse.py0 0.311 0.952 0.003 0.224 0.535 0.766 0.687 0.758 0.539 0.01Name: red, dtype: float64
处理数据表是经常使用 Pandas 解析数据的好方法。从数据帧中选择数据的方法有很多,你尝试的次数越多就越习惯。
可视化你的数据
很多人偏爱可视化信息已不是什么秘密,这是图表和图形成为与高层管理人员开会的主要内容的原因,也是“信息图”在新闻界如此流行的原因。数据科学家的工作之一是帮助其他人理解大量数据样本,并且有一些库可以帮助你完成这项任务。将 Pandas 与可视化库结合使用可以对数据进行可视化解释。一个流行的可视化开源库是 Seaborn,它基于开源的 Matplotlib。
安装 Seaborn 和 Matplotlib
你的 Python 虚拟环境还没有 Seaborn 和 Matplotlib,所以用 pip3 安装它们。安装 Seaborn 的时候,也会安装 Matplotlib 和很多其它的库。
(example) $ pip3 install seaborn
为了使 Matplotlib 显示图形,你还必须安装 PyGObject 和 Pycairo。这涉及到编译代码,只要你安装了必需的头文件和库,pip3 便可以为你执行此操作。你的 Python 虚拟环境不了解这些依赖库,因此你可以在环境内部或外部执行安装命令。
在 Fedora 和 CentOS 上:
(example) $ sudo dnf install -y gcc zlib-devel bzip2 bzip2-devel readline-devel \sqlite sqlite-devel openssl-devel tk-devel git python3-cairo-devel \cairo-gobject-devel gobject-introspection-devel
在 Ubuntu 和 Debian 上:
(example) $ sudo apt install -y libgirepository1.0-dev build-essential \libbz2-dev libreadline-dev libssl-dev zlib1g-dev libsqlite3-dev wget \curl llvm libncurses5-dev libncursesw5-dev xz-utils tk-dev libcairo2-dev
一旦它们安装好了,你可以安装 Matplotlib 需要的 GUI 组件。
(example) $ pip3 install PyGObject pycairo
用 Seaborn 和 Matplotlib 显示图形
在你最喜欢的文本编辑器新建一个叫 vizualize.py 的文件。要创建数据的线形图可视化,首先,你必须导入必要的 Python 模块 —— 先前代码示例中使用的 Pandas 模块:
#!/usr/bin/env python3from pandas import read_csv, DataFrameimport pandas as pd
接下来,导入 Seaborn、Matplotlib 和 Matplotlib 的几个组件,以便你可以配置生成的图形:
import seaborn as snsimport matplotlibimport matplotlib.pyplot as pltfrom matplotlib import rcParams
Matplotlib 可以将其输出导出为多种格式,包括 PDF、SVG 和桌面上的 GUI 窗口。对于此示例,将输出发送到桌面很有意义,因此必须将 Matplotlib 后端设置为 GTK3Agg。如果你不使用 Linux,则可能需要使用 TkAgg 后端。
设置完 GUI 窗口以后,设置窗口大小和 Seaborn 预设样式:
matplotlib.use('GTK3Agg')rcParams['figure.figsize'] = 11,8sns.set_style('darkgrid')
现在,你的显示已配置完毕,代码已经很熟悉了。使用 Pandas 导入 sample.csv 文件,并定义数据帧的列:
FILE = open('sample.csv','r')DATAFRAME = pd.read_csv(FILE)DATAFRAME.columns = [ 'red','green','blue' ]
有了适当格式的数据,你可以将其绘制在图形中。将每一列用作绘图的输入,然后使用 plt.show() 在 GUI 窗口中绘制图形。plt.legend() 参数将列标题与图形上的每一行关联(loc 参数将图例放置在图表之外而不是在图表上方):
for i in DATAFRAME.columns:DATAFRAME[i].plot()plt.legend(bbox_to_anchor=(1, 1), loc=2, borderaxespad=1)plt.show()
运行代码以获得结果。
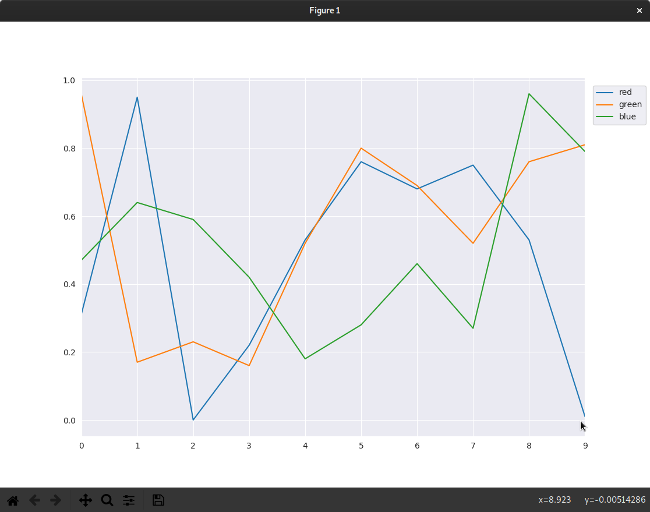
你的图形可以准确显示 CSV 文件中包含的所有信息:值在 Y 轴上,索引号在 X 轴上,并且图形中的线也被标识出来了,以便你知道它们代表什么。然而,由于此代码正在跟踪颜色值(至少是假装),所以线条的颜色不仅不直观,而且违反直觉。如果你永远不需要分析颜色数据,则可能永远不会遇到此问题,但是你一定会遇到类似的问题。在可视化数据时,你必须考虑呈现数据的最佳方法,以防止观看者从你呈现的内容中推断出虚假信息。
为了解决此问题(并展示一些可用的自定义设置),以下代码为每条绘制的线分配了特定的颜色:
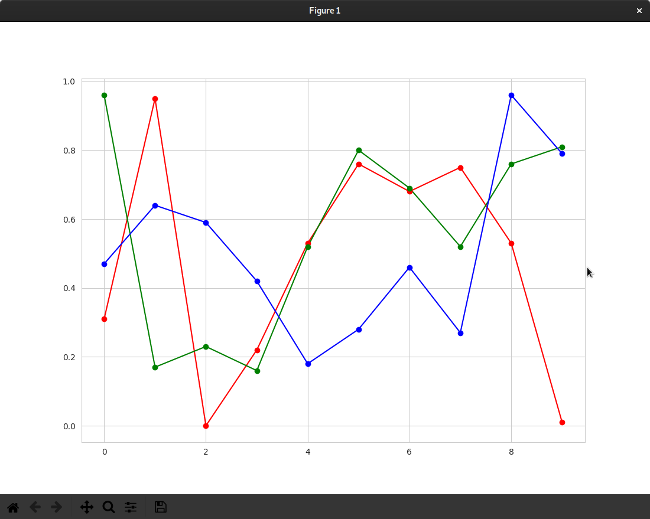
import matplotlibfrom pandas import read_csv, DataFrameimport pandas as pdimport seaborn as snsimport matplotlib.pyplot as pltfrom matplotlib import rcParamsmatplotlib.use('GTK3Agg')rcParams['figure.figsize'] = 11,8sns.set_style('whitegrid')FILE = open('sample.csv','r')DATAFRAME = pd.read_csv(FILE)DATAFRAME.columns = [ 'red','green','blue' ]plt.plot(DATAFRAME['red'],'r-')plt.plot(DATAFRAME['green'],'g-')plt.plot(DATAFRAME['blue'],'b-')plt.plot(DATAFRAME['red'],'ro')plt.plot(DATAFRAME['green'],'go')plt.plot(DATAFRAME['blue'],'bo')plt.show()
这使用特殊的 Matplotlib 表示法为每列创建两个图。每列的初始图分配有一种颜色(红色为 r,绿色为 g,蓝色为 b)。这些是内置的 Matplotlib 设置。 -表示实线(双破折号,例如 r--,将创建虚线)。为每个具有相同颜色的列创建第二个图,但是使用 o 表示点或节点。为了演示内置的 Seaborn 主题,请将 sns.set_style 的值更改为 whitegrid。
停用你的虚拟环境
探索完 Pandas 和绘图后,可以使用 deactivate 命令停用 Python 虚拟环境:
(example) $ deactivate$
当你想重新使用它时,只需像在本文开始时一样重新激活它即可。重新激活虚拟环境时,你必须重新安装模块,但是它们是从缓存安装的,而不是从互联网下载的,因此你不必联网。
无尽的可能性
Pandas、Matplotlib、Seaborn 和数据科学的真正力量是无穷的潜力,使你能够以有意义和启发性的方式解析、解释和组织数据。下一步是使用你在本文中学到的新工具探索简单的数据集。Matplotlib 和 Seaborn 不仅有折线图,还有很多其他功能,因此,请尝试创建条形图或饼图或完全不一样的东西。
一旦你了解了你的工具集并对如何关联数据有了一些想法,则可能性是无限的。数据科学是寻找隐藏在数据中的故事的新方法。让开源成为你的媒介。
via: https://opensource.com/article/19/9/get-started-data-science-python
作者:Seth Kenlon 选题:lujun9972 译者:GraveAccent 校对:wxy
转自 https://linux.cn/article-11406-1.html