 Linuxeden开源社区
Linuxeden开源社区LinkedIn有超过500个内部应用程序基于MySQL。为了便于管理,提高利用率,他们构建了MySQL即服务模型。该模型有个缺点,一个应用程序的查询可能会影响其他应用程序的查询。为了控制查询,他们希望收集数据库中运行的查询的完整信息,以便分析优化。近日,LinkedIn工程师Karthik Appigatla撰文介绍了他们在这方面所做的工作。
MySQL Performance Schema是摆在他们面前的一个选项。MySQL从5.5.3版本开始提供这个特性,它可以从底层监控MySQL服务器的运行。这种方法的缺点是,启用或禁用performance_schema需要重启。而且,启用该模式会增加大约8%到25%的开销。另外,分析Performance Schema的结果也异常复杂。
还有一个选项是借助查询日志。他们可以预先设定一个阈值,并把所有超过阈值的查询记录在一个文件里用于后续分析。这种方法的缺点是无法捕获所有查询。虽然将阈值设为0可以捕获所有查询,但那会导致非常高的I/O,严重降低系统吞吐量,所以,他们一开始就没有考虑使用这种方式。
为了保证开销最小同时又能有效地度量所有查询,他们构建了Query Analyzer。该工具包含三个组件,如下图所示:
- 代理——运行在数据库服务器上。
- 中央服务器——存储查询信息;
- UI——位于中央服务器之上,用于展示SQL分析结果。
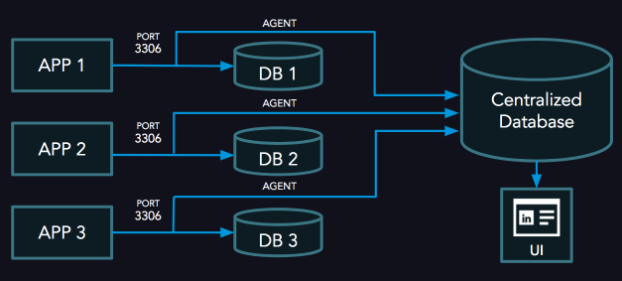
Query Analyzer的高层架构
其中,代理使用原始套接字捕获TCP数据包并解码,然后使用MySQL Protocol从数据包流构建出查询。它会计算查询的响应时间,并将查询发送给一个Go例程(他们使用了Percona GO程序包),由后者识别出查询指纹。代理会以这个指纹为基础计算生成一个哈希值,作为查询的KEY。代理会把查询的哈希值、总响应时间、次数、用户、数据库名称等信息存储在哈希表中。如果服务器执行了哈希值相同的查询,那么次数及总响应时间会增加。此外,代理还会存储查询的元数据,包括查询的哈希值、指纹、第一次执行时间、最大时间、最小时间等。代理会定期将收集到的信息发送给中央服务器,并重置计数器。元数据信息只有在发生变化时才会发送。该代理只需要几个MB的内存来管理这些数据结构,而其发送信息所占用的带宽则可以忽略不计。
UI会显示所有不同的查询,如下图所示:
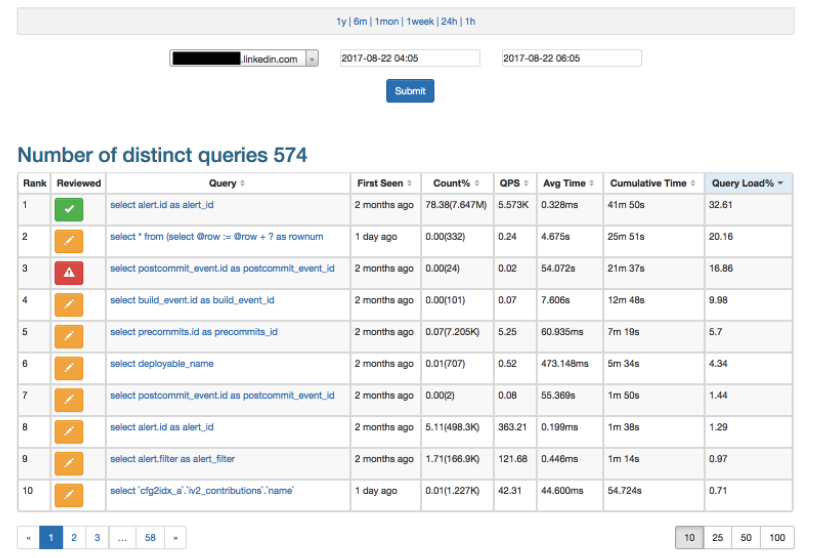
其中有个有趣的指标是查询负载占比,查询负载的计算方法为:

而查询负载占比的计算方法为:

查询负载占比高的查询是需要特别关注的,即使该查询的单次执行时间并不长。点击任意查询,可以查看该查询的趋势图及其他更多信息,如下图所示:

LinkedIn使用sysbench在MySQL 5.6.29-76.2-log Percona Server (GPL)上做了基准测试。当并发线程小于128时,Query Analyzer基本不会影响吞吐量。当并发线程数到达256时,每秒事务数减少了5%,这仍然好于Performance Schema的10%。在整个测试过程中,Query Analyzer占用的CPU不足1%,当并发线程数超过128时,其占用的CPU也仅为5%。
Query Analyzer可以带来许多好处。数据库工程师可以快速定位有问题的查询,高效地分析解决数据库速度变慢的问题。开发人员和业务分析师可以查看查询趋势,检查查询负载。在安全方面,Query Analyzer可以在数据库收到新的查询请求时发出警告。
最后,虽然时间还没有确定,但LinkedIn的最终目标是将Query Analyzer开源。
转自 http://www.infoq.com/cn/news/2017/09/LinkedIn-MySQL-Query-Analyzer