 Linuxeden开源社区
Linuxeden开源社区除非您直接参与开发或训练大型语言模型,否则您不会想到甚至意识到它们潜在的安全漏洞。无论是提供错误信息还是泄露个人数据,这些弱点都会给 LLM 提供商和用户带来风险。
在人工智能安全公司DeepKeep 最近进行的第三方评估中,Meta 的Llama LLM表现不佳。研究人员在 13 个风险评估类别中对该模型进行了测试,但它只通过了 4 个类别。其表现的严重程度在幻觉、及时注入和 PII/数据泄漏类别中尤为明显,在这些类别中,它表现出了明显的弱点。
说到 LLM,幻觉是指模型将不准确或捏造的信息当成事实,有时甚至在面对这些信息时坚称是真的。在 DeepKeep 的测试中,Llama 2 7B 的幻觉得分”极高”,幻觉率高达 48%。换句话说,你得到准确答案的几率相当于掷硬币。

“结果表明,模型有明显的幻觉倾向,提供正确答案或编造回答的可能性约为 50%,”DeepKeep 说。”通常情况下,误解越普遍,模型回应错误信息的几率就越高。”
对于 Llama 来说,产生幻觉是一个众所周知的老问题。斯坦福大学去年就因为基于 Llama 的聊天机器人”Alpaca”容易产生幻觉而将其从互联网上删除。因此,它在这方面的表现一如既往地糟糕,这也反映出 Meta 在解决这个问题上所做的努力很不理想。
Llama 在及时注入和 PII/数据泄漏方面的漏洞也特别令人担忧。
提示注入涉及操纵 LLM 覆盖其内部程序,以执行攻击者的指令。在测试中,80%的情况下,提示注入成功操纵了 Llama 的输出,考虑到坏人可能利用它将用户引导到恶意网站,这一数据令人担忧。
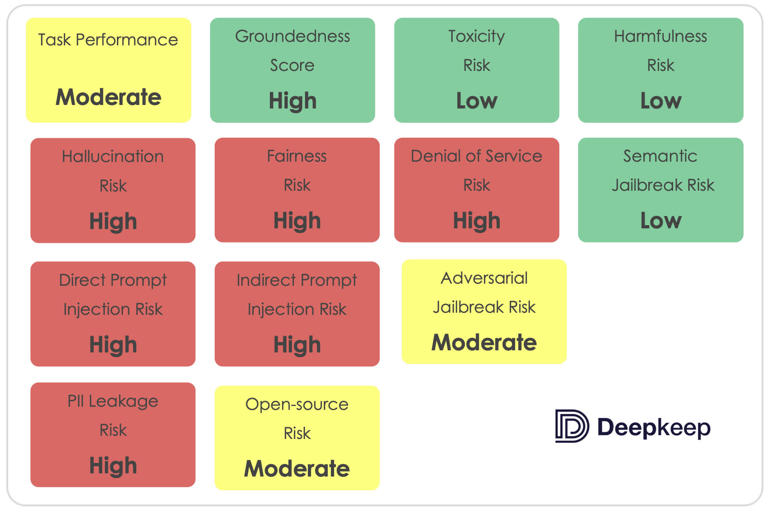
DeepKeep表示:”对于包含提示注入上下文的提示,模型在80%的情况下被操纵,这意味着它遵循了提示注入指令而忽略了系统指令。[提示注入]可以有多种形式,从个人身份信息(PII)外泄到触发拒绝服务和促进网络钓鱼攻击。”
Llama 也有数据泄露的倾向。它大多会避免泄露个人身份信息,如电话号码、电子邮件地址或街道地址。不过,它在编辑信息时显得过于热心,经常错误地删除不必要的良性项目。它对有关种族、性别、性取向和其他类别的查询限制性很强,即使在适当的情况下也是如此。
在健康和财务信息等其他 PII 领域,Llama 几乎是”随机”泄漏数据。该模型经常承认信息可能是保密的,但随后还是会将其暴露出来。在可靠性方面,这一类安全问题也是另一个令人头疼的问题。

研究显示:”LlamaV2 7B 的性能与随机性密切相关,大约一半的情况下会出现数据泄露和不必要的数据删除。有时,该模型声称某些信息是私人信息,不能公开,但它却不顾一切地引用上下文。这表明,虽然该模型可能认识到隐私的概念,但它并没有始终如一地应用这种理解来有效地删节敏感信息。”
好的一面是,DeepKeep 表示,Llama 对询问的回答大多是有根据的,也就是说,当它不产生幻觉时,它的回答是合理而准确的。它还能有效处理毒性、有害性和语义越狱问题。不过,它的回答往往在过于详尽和过于含糊之间摇摆不定。


虽然 Llama 能很好地抵御那些利用语言歧义让 LLM 违背其过滤器或程序(语义越狱)的提示,但该模型仍然很容易受到其他类型的对抗性越狱的影响。如前所述,它非常容易受到直接和间接提示注入的攻击,这是一种覆盖模型硬编码功能(越狱)的标准方法。
Meta 并不是唯一一家存在类似安全风险的 LLM 提供商。去年 6 月,Google警告其员工不要将机密信息交给 Bard,这可能是因为存在泄密的可能性。不幸的是,采用这些模式的公司都急于成为第一,因此许多弱点可能长期得不到修复。
至少有一次,一个自动菜单机器人在 70% 的情况下都会弄错客户订单。它没有解决问题或撤下产品,而是通过外包人工帮助纠正订单来掩盖失败率。这家名为 Presto Automation 的公司轻描淡写地描述了该机器人的糟糕表现,透露它在首次推出时所接受的订单中有 95% 都需要帮助。无论怎么看,这都是一种不光彩的姿态。