 Linuxeden开源社区
Linuxeden开源社区作者 ,译者
本文要点
- Reladomo是Goldman Sachs开发的企业级Java ORM,并在2016年作为开源项目发布。
- Reladomo提供了一系列独到的和有趣的特性,包括强类型查询语言、数据分片、临时表支持、真正的可测试性以及高性能缓存。
- Reladomo的开发是围绕着一系列的核心价值开展的,因此是一种“自有一套”(Opinionated)的框架。
- 本文提供了一些例子,很好地展示了Reladomo的可用性和可编程性。
回顾2004年,那时我们正面对一个艰难的挑战。我们的Java应用需要采用一种能抽象数据库交互的方法,任何现有的框架都无法适应该需求。该应用具有下列需求,超出了惯常解决方案所能提供的:
- 数据是高度切分的。数据存储在一百多个具有相同模式但是数据不同的数据库中。
- 数据是双时态(Bitemporal)的。该内容我们将在本文第二部分介绍,敬请关注!
- 数据上的查询并非完全是静态的,有一些查询必须从一系列的复杂用户输入中动态创建。
- 数据模型有一定程度的复杂性,具有数以百计的数据库表。
我们从2004年就启动了Reladomo的开发工作,并于当年完成了首个生产部署。此后,我们定期发布Reladomo版本。这些年间,Reladomo以在Goldman Sachs得到了广泛采用,其中的主要新特性也是在应用的指导下添加的。Reladomo已用于累计分类账目(multiple ledger)、中台(Middle Office)交易处理、资产负债表(Balance Sheet)处理等数十种应用中。在2016年,Goldman Sachs以Apache 2.0许可开源发布Reladomo。“Reladomo”是“RELAtional DOMain Objects”(关系域对象)一词的缩写。
我们为什么要再构建一个ORM产品?
我们决定在代码这一级上消除样板(Boilerplate)和未完全发育的结构。在Reladomo中不存在对连接的获取、关闭、泄漏或清空,也没有Session、EntityManager和LazyInitializationException。Reladomo以两种基本方式提供API,即在域对象本身上,以及通过强类型List实现的高度提升。
对于我们而言,另一个关键点是Reladomo的查询语言。通常,基于字符串的语言完全不适合于我们的应用及面向对象的代码。除了一些最琐碎的查询之外,通过将字符串连接在一起而构建动态查询并不会很好地工作。维护这些基于字符串连接的动态查询无疑是一件让人头疼的事情。
此外,我们需要对数据分片的完全原生支持。Reladomo中的数据分片是非常灵活的,可以处理出现在不同分片中、指向不同对象的同一主键值。分片查询的语法天然地适合于查询语言。
正如在Richard Snodgrass编写的《Developing Time-Oriented Database Applications in SQL》一书中所指出的,对时序(单时序或双时序)的支持可以帮助数据库设计人员记录和推理时序信息,这完全是Reladomo独有的一个特性。该特性适用面很广,从各种各样的记账系统,到用于所有需要完全可再现性的参考数据(Reference Data)。甚至像项目协作工具这类基本应用,可以受益于单时序表示,成为一种可让用户界面能呈现事情改变方式的时间机器。
应用要实现正常的工作,真实的可测试性无疑是一件非常重要的事情。我们很早就决定,自力更生是正确做事的唯一方法。大部分Reladomo测试是使用Reladomo自身的测试工具编写的!我们对测试的看法很务实,就是要将长期价值添加到测试中。Reladomo测试易于建立,可以在内存数据库上执行所有的生产代码,并允许持续集成测试。这些测试有助于开发人员理解与数据库的交互,无需再配置一个安装了数据库的开发环境。
最后一点,我们不想在性能上做妥协。缓存是影响性能的最重要因素之一。从技术角度看,缓存是Reladomo中最为复杂的部分。Reladomo的缓存是一种无键值、多索引的事务对象缓存。对象是以对象本身的形式缓存的,并确保对象中的数据占用单一的内存引用。对象缓存还附加了对同一对象的查询缓存。查询缓存是智能的,它不会返回过期的结果。当多个JVM使用Reladomo写同一数据时,缓存会正确的工作。缓存可以被配置为在启动时按需分配,或是完全最大化。如果适当类型的数据和应用具备可复制的大规模缓存,对象甚至可以是堆外(off-heap)存储。在我们的生产系统中,就运行了超过200GB的缓存。
开发原则
从定位上看,Reladomo是一个框架,而非一个软件库。要确定一个编程模式是否适用,相比于软件库,框架要更为规范,也更具有自己的一套方法。Reladomo也会生成代码,它所生成的API被认识是可自由地用在开发人员代码的其余部分中。因此对于代码是否能很好地工作,框架代码和应用代码具有统一外观是势在必行的。
我们定义了以下的核心价值,这样我们的潜在用户就可据此决定Reladomo是否适用:
- 代码的目标是可在生产环境中运行多年乃至数十年。
- 一次且仅一次原则(DRY,Don’t repeat yourself)。
- 打造易于更改的代码。
- 以面向基于领域对象的方法编写代码。
- 不要在正确性和一致性上妥协。
我们在“理念和愿景”文档中,详细阐述了上述核心价值及其影响。
可用性和可编程性
为展示Reladomo的部分特性,我们将使用两个小型的领域模型。首先给出的是一个关于宠物的恒定模型(Non-temporal Model):
(点击放大图像)
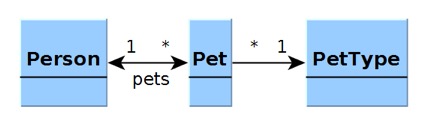
第二个模型是一个出现在教科书上的分类账目模型:
(点击放大图像)
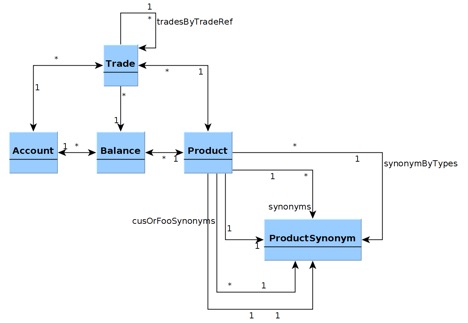
在该模型中,Account对象交易的是有价证券(即Product对象),而一个Product对象具有多个标识码(也称为同义词)。Balance对象中保存了累计余额信息。Balance可以表示Account中任意数量的累计值,例如总量、应税收入、利息等。上述模型的代码提供于GitHub上。
下面我们将会看到,该例子是一个双时态模型。从现在开始,我们会忽略时态位,这并不会影响到特性展示。
在定义模型时,我们对每个概念对象创建了一个Relamodo对象,并使用所创建的对象去生成一些类。我们期待每个开发人员所定义的领域类都能用于真实的业务领域中。一开始生成的对象,永远不会覆写领域中的实际类。这些类的抽象超类是在每次更改模型或Reladomo版本后生成。开发人员也可以为这些具体的类添加一些方法,并将更改检入(check in)到版本控制系统中。
大多数Reladomo所提供的API位于生成类中。在我们提供的宠物例子中,这样的方法包括:PetFinder、PetAbstract和PetListAbstract。PetFinder具有正常的get/set方法,以及其它一些用于持久化的方法。API中最有意思的部分在于Finder和List。
正如方法名所表示的,类特定的Finder(例如PersonFinder)方法是用于发现事物。下面给出一个简单的例子:
Person john = PersonFinder.findOne(PersonFinder.personId().eq(8));
注意,这里不存在需要获取或关闭的连接和会话。方法所检索到的对象在任何场景中都是有效的引用。开发人员可将该对象传递到不同的线程中,并参与到事务的工作单元中。如果方法返回一个以上的对象,findOne就会抛出异常。
如果我们将这个表达式进行分解。其中PersonFinder.firstName()是一个属性,该属性是有类型的,即StringAttribute。开发人员可以调用firstName().eq(“John”),而不是firstName().eq(8)或firstName().eq(someDate)。该对象也具有一些在其它类型属性中无法看到的特殊方法,例如:
PersonFinder.firstName().toLowerCase().startsWith("j")
注意,在我们所说的IntegerAttribute上,toLowerCase()、startsWith()等方法是不可用的,该类型具有自身的一系列特殊方法。
上述内容给出了可用性的两个关键点。首先,所用的IDE应有助于开发人员去编写正确的代码。其次,在开发人员更改了模型后,编译器应可以发现所有需要更改之处。
属性具有在自身上创建操作(Operation)的方法,例如eq()、greaterThan()等。在Reladomo中,操作用于通过Finder.findOne或Finder.findMany等方法检索对象。操作的实现是不可变的,可以与and()和or()组合使用。例如:
Operation op = PersonFinder.firstName().eq("John");
op = op.and(PersonFinder.lastName().endsWith("e"));
PersonList johns = PersonFinder.findMany(op);
在执行具有大量IO操作的应用时,一般应批量地加载数据。这可以使用in语句实现。例如,如果我们构建了如下操作:
Set<String> lastNames = ... //lastNames定义为一个大型集合。例如,其中包含了一万个元素。
PersonList largeList =
PersonFinder.findMany(PersonFinder.lastName().in(lastNames));
Reladomo会在后台分析其中的操作,并生成相应的SQL语句。那么大型的in语句会生成什么样的SQL语句呢?对于Reladomo,该问题的回答是:“依据情况而定”。Reladomo可以选择发布多个in语句,也可以选择使用一个依赖于目标数据库的临时表连接。该选择对用户是透明的。Reladomo的实现会根据操作和数据库的不同而有效地返回相应的正确结果,开发人员不必做选择。因为如果配置发生了更改,或是要编写复杂的代码对可变性进行处理时,开发人员所做出的选择无疑会是错误的。Reladomo自备全套功能!
主键
Reladomo中的主键是对象属性的任意组合。处理这些属性,无需定义键的类或是采用其它的方式。我们的理念是,组合键在所有的模型中无疑都是自然键(Natural Key),不应存在使用上的障碍。在我们给出的基本交易模型的例子中,ProductSynonym类具有自然组合键:
<Attribute name="productId"
javaType="int"
columnName="PRODUCT_ID"
primaryKey="true"/>
<Attribute name="synonymType"
javaType="String"
columnName="SYNONYM_TYPE"
primaryKey="true"/>
当然在某些场景中,合成键也十分有用。我们使用了一种基于表的高性能方法,支持合成键的生成。合成键的生成是批量、异步和按需的。
关系
类间的关系定义在模型中:
<Relationship name="pets"
relatedObject="Pet"
cardinality="one-to-many"
relatedIsDependent="true"
reverseRelationshipName="owner">
this.personId = Pet.personId
</Relationship>
定义关系提供了三个读能力:
- 对象上的get方法。如果关系通过reverseRelationshipName属性标识为双向的,那么相关的对象上可能也具有get方法。例如,person.getPets()。
- 在Finder上浏览关系,例如,PersonFinder.pets()。
- 根据每个查询深入获取关系的能力。
深度获取是一种高效检索相关对象的能力,避免了著名的“N+1查询问题”。如果要检索Person对象,我们可以请求高效地加载Pet对象,实现为:
PersonList people = ... people.deepFetch(PersonFinder.pets());
或者实现为更有意思的例子:
TradeList trades = ...
trades.deepFetch(TradeFinder.account()); //获取这些trades的account信息。
trades.deepFetch(TradeFinder.product()
.cusipSynonym()); //获取product,以及product对于trades的CUSIP同义词(是标识符的一个类型)
trades.deepFetch(TradeFinder.product()
.synonymByType("ISN")); //同样,获取product的ISN同义词(另一个标识符)。
其中可以指定图的任何可访问部分。注意这里所使用的方法,如何避免作为模型的一部分实现。模型并不具有“eager”或“lazy”的概念,而是使用代码中的特定部分实现的。因而,更改模型不可能达到极大地改进已有代码的IO和性能,进而使得模型更为敏捷。
在创建Operation时,可以使用关系。例如:
Operation op = TradeFinder
.account()
.location()
.eq("NY"); // 找到属于名为“NY”的account的所有trades。
op = op.and(TradeFinder.product()
.productName()
.in(productNames)); //并且product名字包括在给出的TradeList中。
TradeList trades2 = TradeFinder.findMany(op);
在Reladomo中,关系实现并不具有实际的引用。这使得从内存和IO角度看,添加关系是毫无代价的。
在Reladomo中,关系是非常灵活的。回到例子,Product对象具有多个不同类型的同义词(例如,CUSIP、Ticket等)。我们已经在Trade模型中定义了这个例子。Product到ProductSynonym间的传统一对多关系几乎难以发挥作用:
<Relationship name="synonyms"
relatedObject="ProductSynonym"
cardinality="one-to-many">
this.productId = ProductSynonym.productId
</Relationship>
这是因为在用户查询需要返回所有Product同义词的情况十分罕见。有两类高级关系会使该通用例子更为有用。一个是常量表达式,允许在模型中表示重要业务概念。例如,如果想通过名字访问Product的CUSIP同义词,我们添加了如下的关系:
<Relationship name="cusipSynonym"
relatedObject="ProductSynonym"
cardinality="one-to-one">
this.productId = ProductSynonym.productId and
ProductSynonym.synonymType = "CUS"
</Relationship>
注意我们是如何在deepFetch中使用这个cusipSynonym关系,并在上面给出的例子进行查询。这一做法有三个好处:首先,我们不必在整个代码中重复“CUS”;其次,如果我们想要的是CUSIP,我们不必付出IO上的代价去检索所有的同义词;最后,查询的可读性更好,在编写上更符合语言习惯。
可组合性
基于字符串的查询的最大问题之一是它们非常难以组合。通过具备类型安全、面向基于领域对象的查询语言,我们将可组合性带到了一个新的高度。为说明这一概念,让我们看一个有意思的例子。
对于我们的Trade模型,Trade对象和Balance对象均具有与Account和Product同样的关系。假设在GUI中允许通过过滤Account和Product信息而检索Trade,并具有提供通过过滤Account和Product信息检索Balance的窗口。由于要处理的是同一实体,过滤器自然是相同的。使用Reladomo,可很容易地实现两者间的代码共用。我们已将Product和Account的业务逻辑抽象为多个GUI组件类,下面我们就可以使用:
public BalanceList retrieveBalances()
{
Operation op = BalanceFinder.businessDate().eq(readUserDate());
op = op.and(BalanceFinder.desk().in(readUserDesks()));
Operation refDataOp = accountComponent.getUserOperation(
BalanceFinder.account());
refDataOp = refDataOp.and(
productComponent.getUserOperation(BalanceFinder.product()));
op = op.and(refDataOp);
return BalanceFinder.findMany(op);
}
上述代码将发布如下SQL语句:
select t0.ACCT_ID,t0.PRODUCT_ID,t0.BALANCE_TYPE,t0.VALUE,t0.FROM_Z,
t0.THRU_Z,t0.IN_Z,t0.OUT_Z
from BALANCE t0
inner join PRODUCT t1
on t0.PRODUCT_ID = t1.PRODUCT_ID
inner join PRODUCT_SYNONYM t2
on t1.PRODUCT_ID = t2.PRODUCT_ID
inner join ACCOUNT t3
on t0.ACCT_ID = t3.ACCT_ID
where t1.FROM_Z <= '2017-03-02 00:00:00.000'
and t1.THRU_Z > '2017-03-02 00:00:00.000'
and t1.OUT_Z = '9999-12-01 23:59:00.000'
and t2.OUT_Z = '9999-12-01 23:59:00.000'
and t2.FROM_Z <= '2017-03-02 00:00:00.000'
and t2.THRU_Z > '2017-03-02 00:00:00.000'
and t2.SYNONYM_TYPE = 'CUS'
and t2.SYNONYM_VAL in ( 'ABC', 'XYZ' )
and t1.MATURITY_DATE < '2020-01-01'
and t3.FROM_Z <= '2017-03-02 00:00:00.000'
and t3.THRU_Z > '2017-03-02 00:00:00.000'
and t3.OUT_Z = '9999-12-01 23:59:00.000'
and t3.CITY = 'NY'
and t0.FROM_Z <= '2017-03-02 00:00:00.000'
and t0.THRU_Z > '2017-03-02 00:00:00.000'
and t0.OUT_Z = '9999-12-01 23:59:00.000'
对于Trade类,ProductComponent类和AccountComponen类是完全可重用的(参见BalanceWindow和TradeWindow)。但是可组合性却远非这样。如果业务需求发生了变化,假定该变化仅针对Balance窗口,用户想要Balance匹配Account或Product过滤器,那么使用Reladomo只需更改一行代码:
refDataOp = refDataOp.or(
productComponent.getUserOperation(BalanceFinder.product()));
现在所发布的SQL语句就大相径庭了:
select t0.ACCT_ID,t0.PRODUCT_ID,t0.BALANCE_TYPE,t0.VALUE,t0.FROM_Z,
t0.THRU_Z,t0.IN_Z,t0.OUT_Z
from BALANCE t0
left join ACCOUNT t1
on t0.ACCT_ID = t1.ACCT_ID
and t1.OUT_Z = '9999-12-01 23:59:00.000'
and t1.FROM_Z <= '2017-03-02 00:00:00.000'
and t1.THRU_Z > '2017-03-02 00:00:00.000'
and t1.CITY = 'NY'
left join PRODUCT t2
on t0.PRODUCT_ID = t2.PRODUCT_ID
and t2.FROM_Z <= '2017-03-02 00:00:00.000'
and t2.THRU_Z > '2017-03-02 00:00:00.000'
and t2.OUT_Z = '9999-12-01 23:59:00.000'
and t2.MATURITY_DATE < '2020-01-01'
left join PRODUCT_SYNONYM t3
on t2.PRODUCT_ID = t3.PRODUCT_ID
and t3.OUT_Z = '9999-12-01 23:59:00.000'
and t3.FROM_Z <= '2017-03-02 00:00:00.000'
and t3.THRU_Z > '2017-03-02 00:00:00.000'
and t3.SYNONYM_TYPE = 'CUS'
and t3.SYNONYM_VAL in ( 'ABC', 'XYZ' )
where ( ( t1.ACCT_ID is not null )
or ( t2.PRODUCT_ID is not null
and t3.PRODUCT_ID is not null ) )
and t0.FROM_Z <= '2017-03-02 00:00:00.000'
and t0.THRU_Z > '2017-03-02 00:00:00.000'
and t0.OUT_Z = '9999-12-01 23:59:00.000'
注意,现在的SQL和先前的SQL间的结构化差异。需求已由“and”更改为“or”,我们相应地将代码从“and”更改到“or”就良好工作了。这毫无疑问就是自带各种功能!如果使用基于字符串或是任何暴露“连接”的查询机制实现该功能,那么实现从“and”到“or”的需求更改将会更为棘手。
CRUD和工作单元模式(Unit of Work)
Reladomo API和CRUD实现在对象和列表上。对象具有insert()和delete()等方法,而列表具有批量操作方法,但是没有“save”或“update”方法。设置持久对象的将会更新数据库。我们期望大多数的写操作在事务中执行,这是通过命令行模式实现的:
MithraManagerProvider.getMithraManager().executeTransactionalCommand(
tx ->
{
Person person = PersonFinder.findOne(PersonFinder.personId().eq(8));
person.setFirstName("David");
person.setLastName("Smith");
return person;
});
UPDATE PERSON
SET FIRST_NAME='David', LAST_NAME='Smith'
WHERE PERSON_ID=8
数据库的写操作将被组合在一起,并执行批处理,这里唯一的约束是正确性。
PersonList对象具有大量有用的方法,提供了基于集合的API,例如,我们可以这样做:
Operation op = PersonFinder.firstName().eq("John");
op = op.and(PersonFinder.lastName().endsWith("e"));
PersonList johns = PersonFinder.findMany(op);
johns.deleteAll();
从表面上看,你可能会认为上述语句会首先去解析列表,然后依次删除Person记录。但事实并非如此,而是发布了如下的事务查询:
DELETE from PERSON WHERE LAST_NAME like '%e' AND FIRST_NAME = 'John'
虽然这一操作不存在问题,但并非真正是生产应用所需的批量删除类型。考虑到应用需要清空旧数据的情况,数据显然不会再使用,因而不存在对全部集合完整事务的需求。数据需要以最适合的方式被移除,有可能是使用后台进程实现。为此我们可使用:
johns.deleteAllInBatches(1000);
根据不同的目标数据库,上述语句将会给出迥异的查询,例如:
对于MS-SQL数据库:
delete top(1000) from PERSON where LAST_NAME like '%e' and FIRST_NAME = 'John'
对于PostgreSQL数据库:
delete from PERSON
where ctid = any (array(select ctid
from PERSON
where LAST_NAME like '%e'
and FIRST_NAME = 'John'
limit 1000))
Reladomo会尽力完成工作,处理临时失败并在完成所有任务后返回。这就是我们所说的“自备全套功能(Batteries Included)”,即集成了通用模式并简化了实现。
易于集成
我们打造了Reladomo,并使其易于集成开发人员的代码。
首先,Reladomo的依赖关系简单。在运行时只需在CLASSPATH中设置六个jar包(即主函数库jar文件及五个浅层依赖jar文件)。在完全生产部署时,只需要给出一个驱动类、slf4j日志实现以及开发人员自身的代码。这将赋予开发人员非常大的自由,使得他们可以按需拉入其它所需模块,而不必担心存在jar冲突的问题。
其次,我们确保Reladomo中提供了向后兼容性。开发人员无需破坏自身代码就可以升级Reladomo版本。如果在我们的计划中存在可能导致向后不兼容的更改。我们将会确保开发人员至少具有一年的时间去转化到新的API。
结论
虽然我们十分看重可使用性(即“自备全套功能!”),但是我们也知道存在着许多不同的用例,满足所有人的需求是不现实的。
一个困扰传统ORM的问题是抽象漏洞(Leaky Abstraction)。我们的核心价值一旦得以实现,就会创建一个能避开所有抽象漏洞的、令人惊叹的系统。Reladomo中没有提供对查询或是存储过程的原生支持,这是刻意而为之的。我们尽量避免编写那些读上去类似于“底层数据库如果支持特性B,那么也支持特性A”这类的文档。
Reladomo还具有更多的本文尚未提及的特性。敬请访问我们的Github代码库查看文档以及Katas(即我们给出的一系列Reladomo学习教程)。本文的第二部分将于今年六月推出,其中将会展示Reladomo的部分性能、可测试性和一些企业特性。
作者简介
 Mohammad Rezaei是Reladomo的主架构师,任Goldman Sachs公司平台业务部门的技术专家(Technology Fellow)。他具有在多种环境中编写高性能Java代码的丰富经验,从分区、并发交易系统,乃至采用无锁算法实现最大吞吐量的大内存系统。Mohammad具有宾夕法尼亚大学的计算机科学本科学位,并在康奈尔大学获得物理学博士学位。
Mohammad Rezaei是Reladomo的主架构师,任Goldman Sachs公司平台业务部门的技术专家(Technology Fellow)。他具有在多种环境中编写高性能Java代码的丰富经验,从分区、并发交易系统,乃至采用无锁算法实现最大吞吐量的大内存系统。Mohammad具有宾夕法尼亚大学的计算机科学本科学位,并在康奈尔大学获得物理学博士学位。
查看英文原文: Introducing Reladomo – Enterprise Open Source Java ORM, Batteries Included!
转自 http://www.infoq.com/cn/articles/Reladomo-Open-Source-ORM