 Linuxeden开源社区
Linuxeden开源社区作者
物联网领域近期如火如荼,互联网和传统公司争相布局物联网。作为物联网领域数据存储的首选,时序数据库也越来越多进入人们的视野,而早在2016年7月,百度云在其天工物联网平台上发布了国内首个多租户的分布式时序数据库产品TSDB,成为支持其发展制造,交通,能源,智慧城市等产业领域的核心产品,同时也成为百度战略发展产业物联网的标志性事件。
前文提到数据查询特别是大数据量的聚合分析查询是时序数据库需要解决的一个主要问题,之前的文章介绍了通过预处理数据的方法,用空间换时间的思路,降低了大数据量聚合分析的延时。
本文将从分布式计算方向思考,从并发的角度介绍时序数据库如何降低数据查询的延时。
1. 单机时序数据的聚合计算
我们先来看看单机是如何支持单聚合函数的计算。单机聚合计算非常简单,用户查询数据时,计算节点查询获取时间范围内的所有时序数据,节点按照时序使用聚合函数对数据进行计算,生成计算结果。
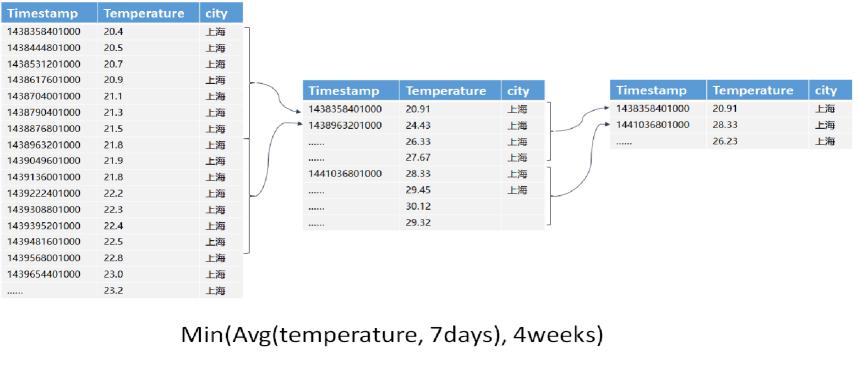
分析查询也经常会使用嵌套聚合,嵌套聚合函数使用不同的时间窗口,内部函数通常使用小时间窗口,外部使用更大的时间窗口。那嵌套聚合查询在单机如何计算呢?和单一聚合函数类似,嵌套聚合函数的计算是在内部聚合函数计算的结果之上,根据时间再次计算,获取结果。如下图查询月平均气温最低的一周以及平均气温。总体来说,单机时序数据的嵌套和非嵌套聚合函数的实现过程简单直接,很容易理解。
(点击放大图像)
单机计算有什么特征呢?从单机的计算过程,我们可以看到单机需要查询获取所有原始时序数据,原始数据查询的IO成本和计算成本非常高,整个查询的延时会很高,但是聚合运算后的结果往往数据量很少。
2. 分布式聚合计算
分布式计算是一种计算方法,与之相对的是集中式计算,是通过使用多个计算资源在分布式的环境中并发执行计算的方法。在时序数据库领域,随着数据的增长,时序数据会越来越多,单机的存储、查询和聚合分析IO时间成本非常高,虽然使用更加高效的硬件也能够缓解,但是有处理上限,基于成本等因素的考虑,分布式聚合查询仍然是时序数据库自然而然的选择。
当时序数据库存储的数据越来越多时,聚合查询不可避免,这也是OLAP分析查询中最常见操作之一,使用预处理可以提高查询性能,但是不够灵活。分布式聚合计算则是能够使用分布式的特性,通过多个计算资源并行计算,再对结果进行合并返回,通过并发提高聚合查询性能。
3. 分布式时序数据聚合计算
时序数据的分布式聚合计算需要多个节点并行计算,逻辑上也是一个Map/Reduce的过程,Map过程需要对原始时序数据进行分片,分别聚合计算。Reduce过程则是对多个分片计算结果的合并。往往聚合运算的结果和原始数据有着明显数据量的差距,其次分布式计算可以更多的考虑数据的本地化,因此使用分布式聚合计算显然能够有效提高查询性能。
时序数据要进行分布式计算需要解决两个基本问题:时序数据计算分片以及计算结果的合并。
3.1 时序数据计算分片
时序数据聚合计算的分片可以分为几个维度考虑:存储分片、聚合函数时间窗口以及查询条件。
首先,时序数据聚合查询包含多种条件,对时序数据进行分组聚合查询也是一种常用查询,不同的分组原始时序数据不同,因此可以通过查询分组对时序数据计算进行分片,不同的分组使用不同节点并发计算。
其次,时序数据聚合查询函数通常都包含时间窗口,相同时间窗口的原始数据聚合计算为一个数据点,不同的时间窗口用于计算的时序原始数据不同,因此也同样可以通过时间窗口对时序数据计算进行时间维度的分片,不同的节点计算不同时间窗口的数据。
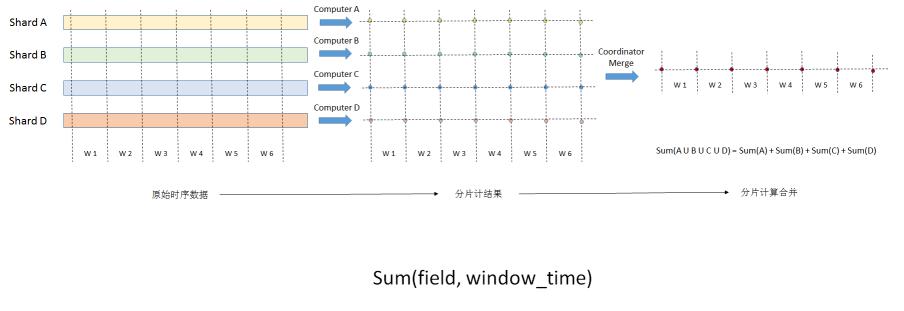
第三,按照存储分片进行计算。我们先来回忆一下前文说描述的时序数据的存储,时序数据由于存储的数据量很大,单机并不能满足需求,因此需要对时序数据进行分片存储,分片(shard)通常使用metric+tags的方式进行,不同的分片存储在不同的存储节点,分片存储着原始时序数据,使用存储分片进行分片计算,也是一种自然而然的选择。如下图先对shard进行分片计算查询,最后对结果进行合并。
(点击放大图像)
使用存储分片来分片计算有着什么优势呢?显然,数据查询和计算在存储分片的节点上进行,能够最大的保证数据本地化,能够有效减少网络通讯带来的延时,使得本地数据计算更加高效。
分布式聚合查询在实现时,往往多种计算分片方式同时使用,聚合计算尽量保证本地化、 尽量多的并发执行。
3.2 时序数据计算结果的合并
时序数据聚合计算结果的合并和计算分片的方式有相关性,不同分片方式结果的合并方式也不同。
首先,对于分组聚合查询结果的合并来说,不同的分组查询结果属于不同的分组,按照分组聚合查询条件合并结果,就能形成计算结果。
其次,对于聚合函数时间窗口分片查询的合并来说,不同的时间窗口的计算结果虽然属于同一个分组,但是结果在时间是上有序的,因此只需要对分片计算结果按照时序排序合并,就能获取最终计算结果。
第三,对于存储分片进行分片计算结果的合并来说,合并相对复杂,因为在同一个时间窗口内,可能会包含多个分片,多个分片上同一时间窗口需要聚合运算为一个数据点。聚合运算结果的合并就需要分析聚合函数的特性来进行,例如在A和B两个存储分片的同一时间窗口内SUM聚合函数,显然计算结果可以直接累加SUM(A U B) = SUM(A) + SUM(B),但是并不是所有的聚合函数都满足这一特性,需要根据聚合函数的特性做一一的分类。
当使用多种分片方式进行聚合查询时,相应结果的合并也同样更为复杂。
3.3 时序数据嵌套聚合运算
嵌套聚合查询也是数据分析的常用方式,嵌套聚合运算往往多个聚合函数嵌套而成,每个聚合函数的计算属性并不完全相同。在考虑计算分片时,可以考虑将外部嵌套函数和内部嵌套函数分开计算,选择更加有利的分片方式。例如考虑 DIFF(SUM(A, 1day)) 嵌套聚合函数(DIFF聚合函数是计算前后时间序列结果的差值),既可以使用按照时间窗口的方式分片计算,也同样可以考虑将 DIFF的计算和SUM的计算拆分开来,先使用存储分片的方式聚合计算SUM(A, 1day)的结果,结果合并时计算DIFF嵌套聚合函数的结果,存储分片的分布式计算能够充分利用数据本地化的特性,因此使用后者显然更加高效。嵌套聚合函数的数据如何分片计算,需要根据聚合函数特性以及场景具体分析,这仍然是一个需要深入考虑的问题。
3.4 计算任务的调度和优化
时序数据分布式计算除了计算分片和数据合并问题以外,同样需要处理任务调度和SQL查询优化的问题,现有的很多开源框架Spark、Presto、Mongodb、Hive都有相应的解决方案,这里就不做深入讨论了。
4. 时序数据聚合查询的难题
时序数据分布式聚合计算仍然有很多难题,例如COUNT(DISTINCT FIELD),这类聚合函数的特点是在计算结果时内部需要保存大量的中间数据用于计算,需要消耗大量计算和存储资源。虽然很多大数据领域分布式查询引擎等通过算法都尝试做了部分优化,但是仍然未能完全解决所有问题。
5. 总结
在时序数据库大数据量聚合分析查询中,聚合运算直接影响着查询性能,使用分布式计算的方法,能够有效的提高查询性能,相比较于预处理查询更加的灵活。本文主要从分片以及如何并发的角度做了讨论,但是一些特殊嵌套聚合场景的优化仍旧是需要深入思考课题。
转自 http://www.infoq.com/cn/articles/distributed-computation-of-sequential-databases